Learning Multimodal Behaviors from Scratch with Diffusion Policy Gradient
2406.00681
0
0

Abstract
Deep reinforcement learning (RL) algorithms typically parameterize the policy as a deep network that outputs either a deterministic action or a stochastic one modeled as a Gaussian distribution, hence restricting learning to a single behavioral mode. Meanwhile, diffusion models emerged as a powerful framework for multimodal learning. However, the use of diffusion policies in online RL is hindered by the intractability of policy likelihood approximation, as well as the greedy objective of RL methods that can easily skew the policy to a single mode. This paper presents Deep Diffusion Policy Gradient (DDiffPG), a novel actor-critic algorithm that learns from scratch multimodal policies parameterized as diffusion models while discovering and maintaining versatile behaviors. DDiffPG explores and discovers multiple modes through off-the-shelf unsupervised clustering combined with novelty-based intrinsic motivation. DDiffPG forms a multimodal training batch and utilizes mode-specific Q-learning to mitigate the inherent greediness of the RL objective, ensuring the improvement of the diffusion policy across all modes. Our approach further allows the policy to be conditioned on mode-specific embeddings to explicitly control the learned modes. Empirical studies validate DDiffPG's capability to master multimodal behaviors in complex, high-dimensional continuous control tasks with sparse rewards, also showcasing proof-of-concept dynamic online replanning when navigating mazes with unseen obstacles.
Create account to get full access
Overview
- This paper introduces a novel reinforcement learning (RL) approach called Diffusion Policy Gradient (DPG) that can learn multimodal behaviors from scratch.
- DPG leverages diffusion models to generate diverse action sequences, enabling the agent to explore a wider range of behaviors during training.
- The authors demonstrate the effectiveness of DPG on several challenging robotic control tasks, including simulated legged locomotion and manipulation.
Plain English Explanation
In this paper, the researchers present a new way of training artificial intelligence (AI) agents to perform complex tasks. The key idea is to use a type of AI model called a "diffusion model" to help the agent explore a wider range of possible actions during training.
Typically, RL agents are trained to find a single, optimal sequence of actions to solve a task. However, many real-world tasks have multiple "correct" ways of being solved. The researchers' Diffusion Policy Gradient (DPG) approach allows the agent to learn a diverse set of effective behaviors, rather than just one.
The diffusion model acts as a "creativity generator," suggesting novel action sequences the agent may not have considered. This encourages the agent to explore more of the possible solution space, ultimately leading to more versatile and capable behaviors. The authors demonstrate the power of DPG on challenging robotic control tasks, such as legged locomotion and manipulation.
By using diffusion models to expand the agent's exploration, this research represents an important step towards developing AI systems that can adapt to a wider range of situations and environments, similar to how humans and animals learn.
Technical Explanation
The core of the Diffusion Policy Gradient (DPG) approach is the use of a diffusion model to generate diverse action sequences during reinforcement learning. Diffusion models are a type of generative AI model that can create new samples by gradually adding noise to data and then learning to reverse this noising process.
In the context of RL, the researchers use a diffusion model to generate diverse action sequences, which are then used to train the agent's policy. This is in contrast to traditional RL, where the agent typically learns a single, deterministic policy that maps states to actions.
By incorporating the diffusion model, DPG allows the agent to explore a much wider range of possible behaviors during training. The policy-guided diffusion component of DPG ensures that the generated action sequences are still relevant to the task, rather than being completely random.
The authors evaluate DPG on a variety of challenging robotic control tasks, including simulated legged locomotion and object manipulation. They show that DPG outperforms standard RL approaches in terms of both performance and the diversity of learned behaviors.
Critical Analysis
The authors provide a thorough evaluation of DPG and demonstrate its advantages over traditional RL methods. However, the paper does not address several potential limitations and areas for further research.
One concern is the computational overhead introduced by the diffusion model. Generating diverse action sequences may be computationally expensive, which could limit the scalability of DPG to larger, more complex tasks. The paper does not provide a detailed analysis of the runtime and memory requirements of the approach.
Additionally, the paper only evaluates DPG on simulated robotic control tasks. It remains to be seen how well the approach would translate to real-world robotic systems, which may have different dynamics and constraints.
Further research could also explore ways to optimize the diffusion process to make it more efficient, or investigate the use of different types of generative models beyond just diffusion models.
Conclusion
The Diffusion Policy Gradient (DPG) approach presented in this paper represents an important step forward in reinforcement learning. By incorporating a diffusion model to generate diverse action sequences, DPG enables agents to learn a wider range of effective behaviors, rather than just a single, optimal policy.
The authors demonstrate the success of DPG on several challenging robotic control tasks, suggesting that this approach could be a valuable tool for developing versatile and adaptable AI systems. As the field of reinforcement learning continues to evolve, techniques like DPG that encourage exploration and multimodal learning will likely play an increasingly important role.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DiffPoGAN: Diffusion Policies with Generative Adversarial Networks for Offline Reinforcement Learning
Xuemin Hu, Shen Li, Yingfen Xu, Bo Tang, Long Chen
0
0
Offline reinforcement learning (RL) can learn optimal policies from pre-collected offline datasets without interacting with the environment, but the sampled actions of the agent cannot often cover the action distribution under a given state, resulting in the extrapolation error issue. Recent works address this issue by employing generative adversarial networks (GANs). However, these methods often suffer from insufficient constraints on policy exploration and inaccurate representation of behavior policies. Moreover, the generator in GANs fails in fooling the discriminator while maximizing the expected returns of a policy. Inspired by the diffusion, a generative model with powerful feature expressiveness, we propose a new offline RL method named Diffusion Policies with Generative Adversarial Networks (DiffPoGAN). In this approach, the diffusion serves as the policy generator to generate diverse distributions of actions, and a regularization method based on maximum likelihood estimation (MLE) is developed to generate data that approximate the distribution of behavior policies. Besides, we introduce an additional regularization term based on the discriminator output to effectively constrain policy exploration for policy improvement. Comprehensive experiments are conducted on the datasets for deep data-driven reinforcement learning (D4RL), and experimental results show that DiffPoGAN outperforms state-of-the-art methods in offline RL.
6/14/2024

Diffusion Policies creating a Trust Region for Offline Reinforcement Learning
Tianyu Chen, Zhendong Wang, Mingyuan Zhou
0
0
Offline reinforcement learning (RL) leverages pre-collected datasets to train optimal policies. Diffusion Q-Learning (DQL), introducing diffusion models as a powerful and expressive policy class, significantly boosts the performance of offline RL. However, its reliance on iterative denoising sampling to generate actions slows down both training and inference. While several recent attempts have tried to accelerate diffusion-QL, the improvement in training and/or inference speed often results in degraded performance. In this paper, we introduce a dual policy approach, Diffusion Trusted Q-Learning (DTQL), which comprises a diffusion policy for pure behavior cloning and a practical one-step policy. We bridge the two polices by a newly introduced diffusion trust region loss. The diffusion policy maintains expressiveness, while the trust region loss directs the one-step policy to explore freely and seek modes within the region defined by the diffusion policy. DTQL eliminates the need for iterative denoising sampling during both training and inference, making it remarkably computationally efficient. We evaluate its effectiveness and algorithmic characteristics against popular Kullback-Leibler (KL) based distillation methods in 2D bandit scenarios and gym tasks. We then show that DTQL could not only outperform other methods on the majority of the D4RL benchmark tasks but also demonstrate efficiency in training and inference speeds. The PyTorch implementation is available at https://github.com/TianyuCodings/Diffusion_Trusted_Q_Learning.
6/4/2024
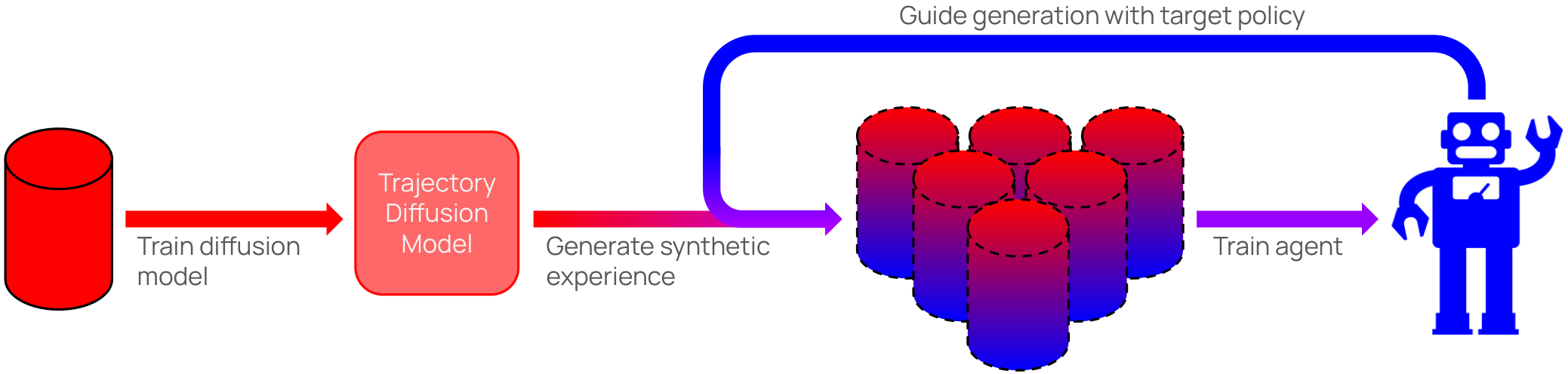
Policy-Guided Diffusion
Matthew Thomas Jackson, Michael Tryfan Matthews, Cong Lu, Benjamin Ellis, Shimon Whiteson, Jakob Foerster
0
0
In many real-world settings, agents must learn from an offline dataset gathered by some prior behavior policy. Such a setting naturally leads to distribution shift between the behavior policy and the target policy being trained - requiring policy conservatism to avoid instability and overestimation bias. Autoregressive world models offer a different solution to this by generating synthetic, on-policy experience. However, in practice, model rollouts must be severely truncated to avoid compounding error. As an alternative, we propose policy-guided diffusion. Our method uses diffusion models to generate entire trajectories under the behavior distribution, applying guidance from the target policy to move synthetic experience further on-policy. We show that policy-guided diffusion models a regularized form of the target distribution that balances action likelihood under both the target and behavior policies, leading to plausible trajectories with high target policy probability, while retaining a lower dynamics error than an offline world model baseline. Using synthetic experience from policy-guided diffusion as a drop-in substitute for real data, we demonstrate significant improvements in performance across a range of standard offline reinforcement learning algorithms and environments. Our approach provides an effective alternative to autoregressive offline world models, opening the door to the controllable generation of synthetic training data.
4/10/2024

Learning a Diffusion Model Policy from Rewards via Q-Score Matching
Michael Psenka, Alejandro Escontrela, Pieter Abbeel, Yi Ma
0
0
Diffusion models have become a popular choice for representing actor policies in behavior cloning and offline reinforcement learning. This is due to their natural ability to optimize an expressive class of distributions over a continuous space. However, previous works fail to exploit the score-based structure of diffusion models, and instead utilize a simple behavior cloning term to train the actor, limiting their ability in the actor-critic setting. In this paper, we present a theoretical framework linking the structure of diffusion model policies to a learned Q-function, by linking the structure between the score of the policy to the action gradient of the Q-function. We focus on off-policy reinforcement learning and propose a new policy update method from this theory, which we denote Q-score matching. Notably, this algorithm only needs to differentiate through the denoising model rather than the entire diffusion model evaluation, and converged policies through Q-score matching are implicitly multi-modal and explorative in continuous domains. We conduct experiments in simulated environments to demonstrate the viability of our proposed method and compare to popular baselines. Source code is available from the project website: https://scorematchingrl.com.
6/18/2024