Diffusion Models Are Real-Time Game Engines

1

Sign in to get full access
Overview
- Diffusion models are a powerful type of machine learning model that can generate realistic images, videos, and other complex data.
- This paper proposes that diffusion models can be used as the basis for real-time game engines, potentially revolutionizing the video game industry.
- The key idea is to use diffusion models to simulate interactive virtual worlds that can respond dynamically to user inputs, rather than relying on traditional game engines.
Plain English Explanation
Diffusion models are a new type of artificial intelligence that can create highly realistic images, videos, and other kinds of complex data. This paper suggests that these diffusion models could be used to build video games in a completely different way.
Typically, video games use "game engines" - software that simulates the virtual world and characters. But these game engines are often quite limited in what they can do. The researchers think diffusion models could replace traditional game engines and allow for much more flexible and responsive virtual worlds.
The idea is that the diffusion model would learn to simulate an entire interactive environment, including the physics, characters, and objects. Then when a player interacts with the game, the diffusion model can immediately update the virtual world in real-time to reflect those changes. This could enable video games with much more dynamic and unpredictable environments that feel more "alive."
The paper introduces a specific system called "GameNGen" that demonstrates how this could work in practice. GameNGen uses a diffusion model to generate and control a virtual world, and shows how it can respond to various player actions smoothly and realistically.
Overall, this research suggests diffusion models could be a game-changing technology for the video game industry, allowing for a new class of more immersive and responsive virtual experiences. However, significant technical challenges would need to be overcome to make this a reality.
Technical Explanation
The paper proposes using diffusion models as the basis for real-time game engines, in a system called "GameNGen." Diffusion models are a type of generative AI that can create highly realistic images, videos, and other complex data by learning to gradually "denoise" random noise into the desired output.
The core idea is to use a diffusion model to simulate an entire interactive virtual world, including the physics, objects, and characters. This diffusion-based world model can then be directly controlled by player inputs in real-time, rather than relying on a traditional game engine.
The GameNGen architecture combines several key components:
- A diffusion model that has been trained to generate the virtual world, including realistic 3D environments, dynamic objects, and responsive characters.
- A differentiable renderer that can translate the diffusion model's internal state into a renderable 3D scene.
- A reinforcement learning agent that controls the diffusion model's internal state in response to player inputs, allowing the virtual world to be updated in real-time.
Through experiments, the researchers demonstrate that GameNGen can generate and control complex virtual environments that respond smoothly to user interactions. This suggests diffusion models may be able to overcome the limitations of traditional game engines and enable a new class of more flexible and immersive video game experiences.
Critical Analysis
The core idea of using diffusion models for real-time game engines is intriguing and could represent a significant advance for the video game industry. However, the paper acknowledges several important technical challenges that would need to be addressed:
- Scalability: Simulating an entire interactive virtual world with a diffusion model likely requires immense computational resources. Scaling this approach to large, complex game worlds may prove difficult.
- Responsiveness: While the experiments show real-time performance, maintaining the necessary frame rates and latency for smooth gameplay across a wide range of user inputs remains an open challenge.
- Authoring Tools: Existing game development tools and workflows are highly optimized for traditional game engines. Transitioning to a diffusion-based approach would likely require radical changes to the game creation process.
Additionally, the paper does not address potential ethical concerns around the use of generative AI in video games, such as the potential for generating inappropriate or biased content.
Overall, the proposed approach is promising but would require significant further research and development to become a practical reality for mainstream video game applications. Careful consideration of the technical limitations and ethical implications would be essential.
Conclusion
This paper presents a bold vision for using diffusion models as the basis for real-time game engines, potentially revolutionizing the video game industry. The key insight is that diffusion models can be used to simulate entire interactive virtual worlds that can respond dynamically to user inputs, overcoming the limitations of traditional game engines.
While significant technical challenges remain, the demonstrated capabilities of the GameNGen system suggest this approach could enable a new class of more flexible and immersive video game experiences. As diffusion models continue to advance, exploring their potential applications in interactive entertainment could be a fruitful area of research.
However, careful consideration of the ethical implications and practical barriers to adoption would be crucial in realizing this vision. Overall, this paper offers a thought-provoking glimpse into how generative AI could reshape the future of video games.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
Diffusion Models Are Real-Time Game Engines
Dani Valevski, Yaniv Leviathan, Moab Arar, Shlomi Fruchter
We present GameNGen, the first game engine powered entirely by a neural model that enables real-time interaction with a complex environment over long trajectories at high quality. GameNGen can interactively simulate the classic game DOOM at over 20 frames per second on a single TPU. Next frame prediction achieves a PSNR of 29.4, comparable to lossy JPEG compression. Human raters are only slightly better than random chance at distinguishing short clips of the game from clips of the simulation. GameNGen is trained in two phases: (1) an RL-agent learns to play the game and the training sessions are recorded, and (2) a diffusion model is trained to produce the next frame, conditioned on the sequence of past frames and actions. Conditioning augmentations enable stable auto-regressive generation over long trajectories.
Read more8/28/2024
🔗
0
Video Diffusion Models: A Survey
Andrew Melnik, Michal Ljubljanac, Cong Lu, Qi Yan, Weiming Ren, Helge Ritter
Diffusion generative models have recently become a robust technique for producing and modifying coherent, high-quality video. This survey offers a systematic overview of critical elements of diffusion models for video generation, covering applications, architectural choices, and the modeling of temporal dynamics. Recent advancements in the field are summarized and grouped into development trends. The survey concludes with an overview of remaining challenges and an outlook on the future of the field. Website: https://github.com/ndrwmlnk/Awesome-Video-Diffusion-Models
Read more5/7/2024
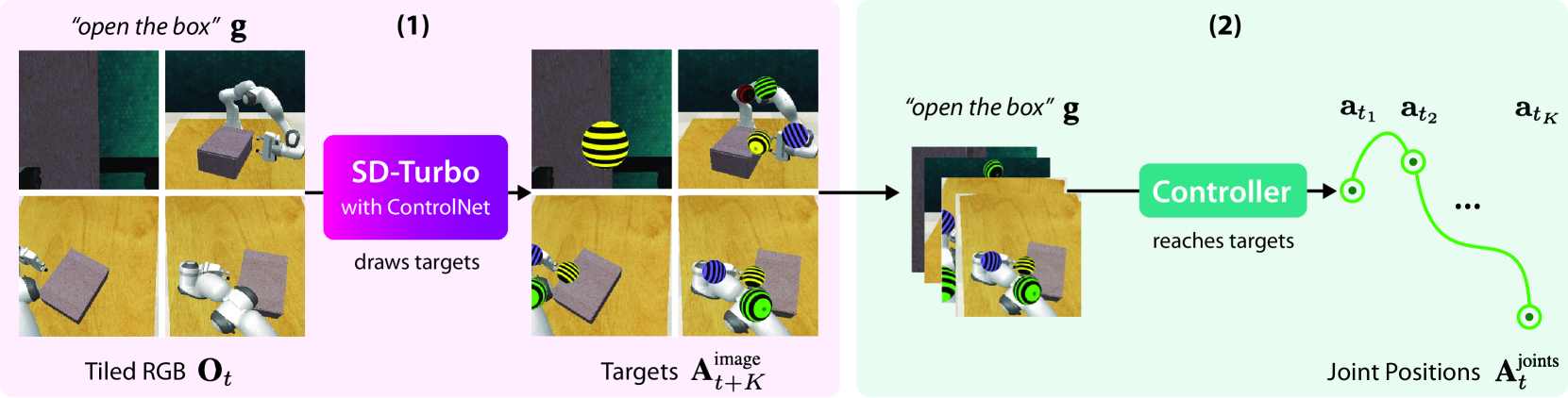
0
Generative Image as Action Models
Mohit Shridhar, Yat Long Lo, Stephen James
Image-generation diffusion models have been fine-tuned to unlock new capabilities such as image-editing and novel view synthesis. Can we similarly unlock image-generation models for visuomotor control? We present GENIMA, a behavior-cloning agent that fine-tunes Stable Diffusion to 'draw joint-actions' as targets on RGB images. These images are fed into a controller that maps the visual targets into a sequence of joint-positions. We study GENIMA on 25 RLBench and 9 real-world manipulation tasks. We find that, by lifting actions into image-space, internet pre-trained diffusion models can generate policies that outperform state-of-the-art visuomotor approaches, especially in robustness to scene perturbations and generalizing to novel objects. Our method is also competitive with 3D agents, despite lacking priors such as depth, keypoints, or motion-planners.
Read more7/11/2024

0
Online Continual Learning of Video Diffusion Models From a Single Video Stream
Jason Yoo, Dylan Green, Geoff Pleiss, Frank Wood
Diffusion models have shown exceptional capabilities in generating realistic videos. Yet, their training has been predominantly confined to offline environments where models can repeatedly train on i.i.d. data to convergence. This work explores the feasibility of training diffusion models from a semantically continuous video stream, where correlated video frames sequentially arrive one at a time. To investigate this, we introduce two novel continual video generative modeling benchmarks, Lifelong Bouncing Balls and Windows 95 Maze Screensaver, each containing over a million video frames generated from navigating stationary environments. Surprisingly, our experiments show that diffusion models can be effectively trained online using experience replay, achieving performance comparable to models trained with i.i.d. samples given the same number of gradient steps.
Read more6/10/2024