Generative Image as Action Models

0
Sign in to get full access
Overview
- The paper "Generative Image as Action Models" introduces a novel approach called GENIMA, which uses generative image models to learn effective visuomotor policies for real-world robotic tasks.
- GENIMA leverages pre-trained diffusion-based image generation models to align the image and action spaces, enabling the model to learn complex manipulation skills from visual demonstrations.
- The proposed framework outperforms existing methods on a range of challenging robotic manipulation tasks, including tasks with visual occlusion, dynamic objects, and narrow-opening environments.
Plain English Explanation
The paper presents a new way for robots to learn how to perform complex physical tasks by observing visual demonstrations. The key idea is to use powerful AI models that can generate images, called "diffusion models," to bridge the gap between the visual world and the world of robotic actions.
Traditionally, teaching robots new skills has been a challenging problem. Robots need to learn how to translate what they see into the right sequence of movements to accomplish a task. This can be especially tricky for tasks involving dexterity, object manipulation, or navigating cluttered environments.
The researchers behind this work developed a system called GENIMA that uses diffusion models to learn these visuomotor skills. Diffusion models are a type of AI that can generate highly realistic images by starting with random noise and gradually transforming it into a desired image. The researchers found that the internal representations learned by these diffusion models can also be used to map visual observations to the appropriate robotic actions.
By aligning the "image space" and the "action space" using diffusion models, GENIMA can learn complex manipulation skills directly from visual demonstrations, without needing explicit programming of the robot's movements. The paper shows that GENIMA outperforms previous methods on a variety of challenging robotic tasks, including moving objects around obstacles, picking up objects in cluttered scenes, and navigating through narrow openings.
This work is an exciting step forward in making it easier to teach robots new skills. By leveraging the representational power of modern generative AI models, robots can learn to perform tasks that would be very difficult to program by hand. This could lead to more capable and versatile robots that can adapt to a wider range of real-world situations.
Technical Explanation
The core idea behind GENIMA [https://aimodels.fyi/papers/arxiv/generative-image-as-action-models] is to leverage pre-trained diffusion-based image generation models to learn effective visuomotor policies for real-world robotic manipulation tasks. Diffusion models [https://aimodels.fyi/papers/arxiv/render-diffuse-aligning-image-action-spaces-diffusion], a class of powerful generative models, have shown the ability to produce highly realistic and diverse images.
The researchers hypothesized that the internal representations learned by diffusion models during image generation could also be used to map visual observations to appropriate robotic actions. To this end, GENIMA aligns the "image space" and the "action space" by training the diffusion model to not only generate images, but also to predict the actions that would transform one image into another.
This alignment allows GENIMA to learn complex manipulation skills directly from visual demonstrations, without the need for explicit programming of the robot's movements. The paper demonstrates the effectiveness of this approach on a range of challenging robotic tasks, including tasks with visual occlusion, dynamic objects, and narrow-opening environments.
The GENIMA framework outperforms previous methods, such as [https://aimodels.fyi/papers/arxiv/dreamitate-real-world-visuomotor-policy-learning-via] and [https://aimodels.fyi/papers/arxiv/interactive-generation-laparoscopic-videos-diffusion-models], which relied on more limited representations or required more manual engineering.
Critical Analysis
The paper provides a compelling and technically sound approach to learning visuomotor policies for robotic manipulation tasks. The key advantage of GENIMA is its ability to leverage the rich visual representations learned by pre-trained diffusion models, which enables the system to learn complex skills from visual demonstrations alone.
However, the paper does acknowledge some limitations and areas for further research. For example, the current GENIMA implementation is limited to relatively simple robotic manipulators and tasks, and it is unclear how well the approach would scale to more complex robotic systems or tasks with higher-dimensional action spaces.
Additionally, the paper does not address the potential safety and reliability concerns that may arise when deploying such learned visuomotor policies in real-world scenarios. Further research is needed to ensure the robustness and safety of these systems, especially when operating in unstructured environments or interacting with humans.
Another area for exploration is the potential to incorporate [https://aimodels.fyi/papers/arxiv/language-guided-manipulation-diffusion-policies-constrained-inpainting] or other forms of high-level task guidance to further improve the generalization and capabilities of GENIMA-based systems.
Overall, the GENIMA approach represents an exciting advancement in the field of robotic manipulation, and the promising results presented in the paper suggest that further research in this direction could lead to more versatile and capable robotic systems.
Conclusion
The paper "Generative Image as Action Models" introduces a novel framework called GENIMA that leverages pre-trained diffusion-based image generation models to learn effective visuomotor policies for real-world robotic manipulation tasks. By aligning the image and action spaces, GENIMA can learn complex skills directly from visual demonstrations, without the need for explicit programming of robotic movements.
The key innovation of GENIMA is its ability to utilize the rich visual representations learned by diffusion models, enabling the system to outperform previous methods on a range of challenging robotic tasks. While the current implementation has some limitations, the promising results suggest that this approach could lead to more versatile and capable robotic systems in the future.
As the field of robotics continues to evolve, techniques like GENIMA that can bridge the gap between visual perception and physical action will become increasingly important. This work represents an important step forward in making it easier to teach robots new skills and adapt them to a wider range of real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Generative Image as Action Models
Mohit Shridhar, Yat Long Lo, Stephen James
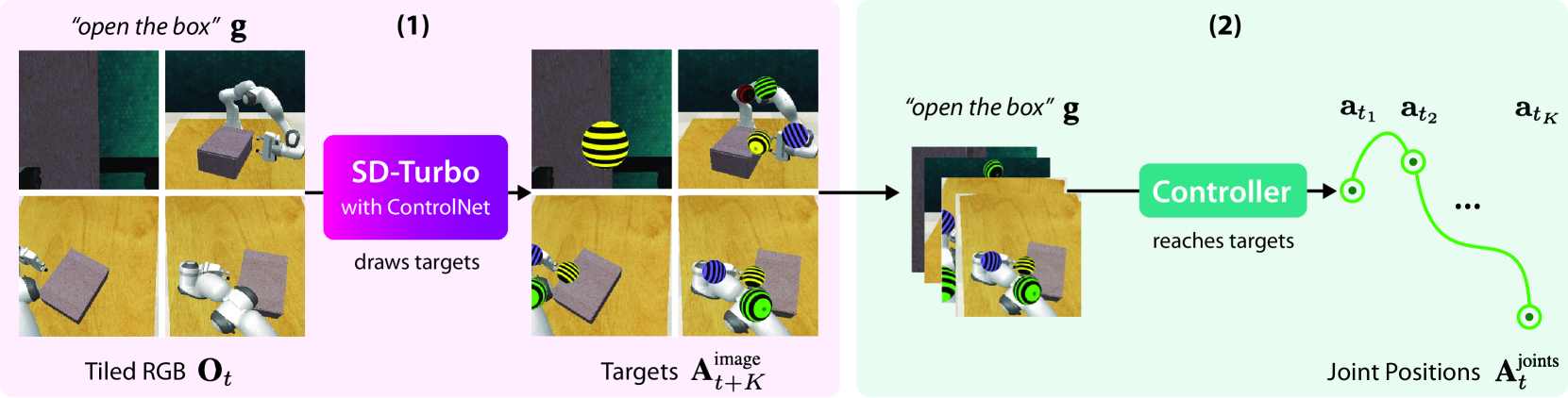
Image-generation diffusion models have been fine-tuned to unlock new capabilities such as image-editing and novel view synthesis. Can we similarly unlock image-generation models for visuomotor control? We present GENIMA, a behavior-cloning agent that fine-tunes Stable Diffusion to 'draw joint-actions' as targets on RGB images. These images are fed into a controller that maps the visual targets into a sequence of joint-positions. We study GENIMA on 25 RLBench and 9 real-world manipulation tasks. We find that, by lifting actions into image-space, internet pre-trained diffusion models can generate policies that outperform state-of-the-art visuomotor approaches, especially in robustness to scene perturbations and generalizing to novel objects. Our method is also competitive with 3D agents, despite lacking priors such as depth, keypoints, or motion-planners.
Read more7/11/2024
0
Dreamitate: Real-World Visuomotor Policy Learning via Video Generation
Junbang Liang, Ruoshi Liu, Ege Ozguroglu, Sruthi Sudhakar, Achal Dave, Pavel Tokmakov, Shuran Song, Carl Vondrick
A key challenge in manipulation is learning a policy that can robustly generalize to diverse visual environments. A promising mechanism for learning robust policies is to leverage video generative models, which are pretrained on large-scale datasets of internet videos. In this paper, we propose a visuomotor policy learning framework that fine-tunes a video diffusion model on human demonstrations of a given task. At test time, we generate an example of an execution of the task conditioned on images of a novel scene, and use this synthesized execution directly to control the robot. Our key insight is that using common tools allows us to effortlessly bridge the embodiment gap between the human hand and the robot manipulator. We evaluate our approach on four tasks of increasing complexity and demonstrate that harnessing internet-scale generative models allows the learned policy to achieve a significantly higher degree of generalization than existing behavior cloning approaches.
Read more6/26/2024

0
Render and Diffuse: Aligning Image and Action Spaces for Diffusion-based Behaviour Cloning
Vitalis Vosylius, Younggyo Seo, Jafar Uruc{c}, Stephen James
In the field of Robot Learning, the complex mapping between high-dimensional observations such as RGB images and low-level robotic actions, two inherently very different spaces, constitutes a complex learning problem, especially with limited amounts of data. In this work, we introduce Render and Diffuse (R&D) a method that unifies low-level robot actions and RGB observations within the image space using virtual renders of the 3D model of the robot. Using this joint observation-action representation it computes low-level robot actions using a learnt diffusion process that iteratively updates the virtual renders of the robot. This space unification simplifies the learning problem and introduces inductive biases that are crucial for sample efficiency and spatial generalisation. We thoroughly evaluate several variants of R&D in simulation and showcase their applicability on six everyday tasks in the real world. Our results show that R&D exhibits strong spatial generalisation capabilities and is more sample efficient than more common image-to-action methods.
Read more5/29/2024
🛸
0
Interactive Generation of Laparoscopic Videos with Diffusion Models
Ivan Iliash (Technical University of Munich), Simeon Allmendinger (University of Bayreuth), Felix Meissen (Technical University of Munich), Niklas Kuhl (University of Bayreuth), Daniel Ruckert (Technical University of Munich)
Generative AI, in general, and synthetic visual data generation, in specific, hold much promise for benefiting surgical training by providing photorealism to simulation environments. Current training methods primarily rely on reading materials and observing live surgeries, which can be time-consuming and impractical. In this work, we take a significant step towards improving the training process. Specifically, we use diffusion models in combination with a zero-shot video diffusion method to interactively generate realistic laparoscopic images and videos by specifying a surgical action through text and guiding the generation with tool positions through segmentation masks. We demonstrate the performance of our approach using the publicly available Cholec dataset family and evaluate the fidelity and factual correctness of our generated images using a surgical action recognition model as well as the pixel-wise F1-score for the spatial control of tool generation. We achieve an FID of 38.097 and an F1-score of 0.71.
Read more6/12/2024