Diffusion Models as Optimizers for Efficient Planning in Offline RL

0
Sign in to get full access
Overview
- The paper proposes using diffusion models as optimizers for efficient planning in offline reinforcement learning (RL).
- Diffusion models are used to generate high-quality action sequences that can be used for planning in offline RL.
- The method outperforms existing offline RL algorithms on a range of continuous control tasks.
Plain English Explanation
Reinforcement learning is a powerful technique for training AI systems to make decisions and take actions. However, standard reinforcement learning approaches often require a lot of trial-and-error exploration, which can be inefficient and expensive, especially in the real world.
<a href="https://aimodels.fyi/papers/arxiv/constraint-aware-diffusion-models-trajectory-optimization">Offline reinforcement learning</a> aims to overcome this by training the AI system using previously collected data, without the need for live interaction. This paper proposes using a special type of AI model called a <a href="https://aimodels.fyi/papers/arxiv/atradiff-accelerating-online-reinforcement-learning-imaginary-trajectories">diffusion model</a> to help the system plan efficient actions based on the offline data.
Diffusion models are trained to generate high-quality, realistic-looking data, similar to the training data. In this case, the diffusion model is trained to generate sequences of actions that lead to good outcomes, based on the offline reinforcement learning data. The system can then use these generated action sequences to efficiently plan its behavior, without needing to explore the environment extensively.
The researchers show that this approach outperforms other state-of-the-art offline reinforcement learning methods on a variety of continuous control tasks, demonstrating the potential of diffusion models for efficient planning in offline RL.
Technical Explanation
The key idea of the paper is to leverage <a href="https://aimodels.fyi/papers/arxiv/preferred-action-optimized-diffusion-policies-offline-reinforcement">diffusion models</a> as optimizers for efficient planning in offline reinforcement learning. Diffusion models are trained to progressively add noise to data, then learn to reverse this process and generate high-quality samples.
The authors propose using a diffusion model to generate action sequences that lead to high rewards, based on the offline RL data. This allows the system to plan efficient behavior without the need for extensive exploration. Specifically, the diffusion model is trained to map from a latent space of low-dimensional action embeddings to the full action sequences.
During planning, the system uses the trained diffusion model to sample high-quality action sequences, which are then evaluated using the offline RL reward function. This allows the system to efficiently explore the space of possible action sequences and find ones that lead to high rewards.
The authors evaluate their approach, called <a href="https://aimodels.fyi/papers/arxiv/diffusion-es-gradient-free-planning-diffusion-autonomous">Diffusion-based Optimization for Offline RL (DOOFER)</a>, on a range of continuous control tasks. They show that DOOFER outperforms existing state-of-the-art offline RL algorithms, demonstrating the potential of diffusion models for efficient planning in offline RL.
Critical Analysis
The paper presents a novel and promising approach to offline reinforcement learning, but there are a few potential limitations and areas for further research:
-
The performance of the diffusion model is crucial, and the authors do not provide a detailed analysis of the model's training and generation capabilities. Further research could explore more advanced diffusion model architectures and training techniques.
-
The method relies on the offline RL data being of high quality and representative of the task. In real-world scenarios, the available data may be limited or biased, which could impact the performance of the diffusion-based planning approach.
<a href="https://aimodels.fyi/papers/arxiv/madiff-offline-multi-agent-learning-diffusion-models">Extensions to multi-agent</a> or <a href="https://aimodels.fyi/papers/arxiv/constraint-aware-diffusion-models-trajectory-optimization">constraint-aware</a> settings could also be an interesting direction for future research.
Conclusion
This paper demonstrates the potential of using diffusion models as optimizers for efficient planning in offline reinforcement learning. By generating high-quality action sequences, the diffusion-based approach can outperform existing offline RL methods on a range of continuous control tasks.
The work highlights the value of exploring novel AI techniques, such as diffusion models, to address the challenges of efficient exploration and planning in real-world reinforcement learning applications. Further research in this area could lead to significant advancements in offline RL and its practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Diffusion Models as Optimizers for Efficient Planning in Offline RL
Renming Huang, Yunqiang Pei, Guoqing Wang, Yangming Zhang, Yang Yang, Peng Wang, Hengtao Shen
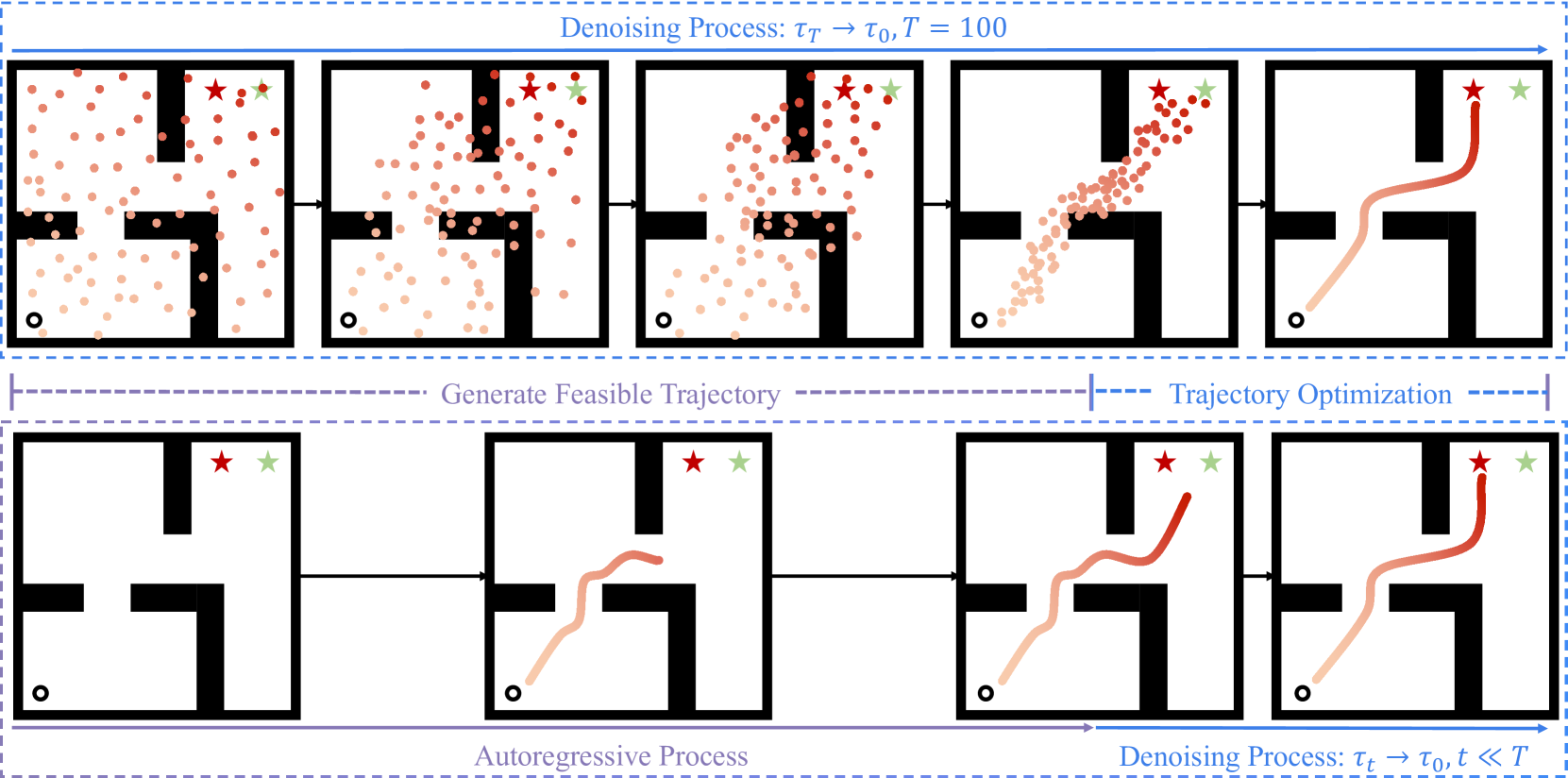
Diffusion models have shown strong competitiveness in offline reinforcement learning tasks by formulating decision-making as sequential generation. However, the practicality of these methods is limited due to the lengthy inference processes they require. In this paper, we address this problem by decomposing the sampling process of diffusion models into two decoupled subprocesses: 1) generating a feasible trajectory, which is a time-consuming process, and 2) optimizing the trajectory. With this decomposition approach, we are able to partially separate efficiency and quality factors, enabling us to simultaneously gain efficiency advantages and ensure quality assurance. We propose the Trajectory Diffuser, which utilizes a faster autoregressive model to handle the generation of feasible trajectories while retaining the trajectory optimization process of diffusion models. This allows us to achieve more efficient planning without sacrificing capability. To evaluate the effectiveness and efficiency of the Trajectory Diffuser, we conduct experiments on the D4RL benchmarks. The results demonstrate that our method achieves $it 3$-$it 10 times$ faster inference speed compared to previous sequence modeling methods, while also outperforming them in terms of overall performance. https://github.com/RenMing-Huang/TrajectoryDiffuser Keywords: Reinforcement Learning and Efficient Planning and Diffusion Model
Read more7/24/2024

0
ATraDiff: Accelerating Online Reinforcement Learning with Imaginary Trajectories
Qianlan Yang, Yu-Xiong Wang
Training autonomous agents with sparse rewards is a long-standing problem in online reinforcement learning (RL), due to low data efficiency. Prior work overcomes this challenge by extracting useful knowledge from offline data, often accomplished through the learning of action distribution from offline data and utilizing the learned distribution to facilitate online RL. However, since the offline data are given and fixed, the extracted knowledge is inherently limited, making it difficult to generalize to new tasks. We propose a novel approach that leverages offline data to learn a generative diffusion model, coined as Adaptive Trajectory Diffuser (ATraDiff). This model generates synthetic trajectories, serving as a form of data augmentation and consequently enhancing the performance of online RL methods. The key strength of our diffuser lies in its adaptability, allowing it to effectively handle varying trajectory lengths and mitigate distribution shifts between online and offline data. Because of its simplicity, ATraDiff seamlessly integrates with a wide spectrum of RL methods. Empirical evaluation shows that ATraDiff consistently achieves state-of-the-art performance across a variety of environments, with particularly pronounced improvements in complicated settings. Our code and demo video are available at https://atradiff.github.io .
Read more6/7/2024
0
Constraint-Aware Diffusion Models for Trajectory Optimization
Anjian Li, Zihan Ding, Adji Bousso Dieng, Ryne Beeson
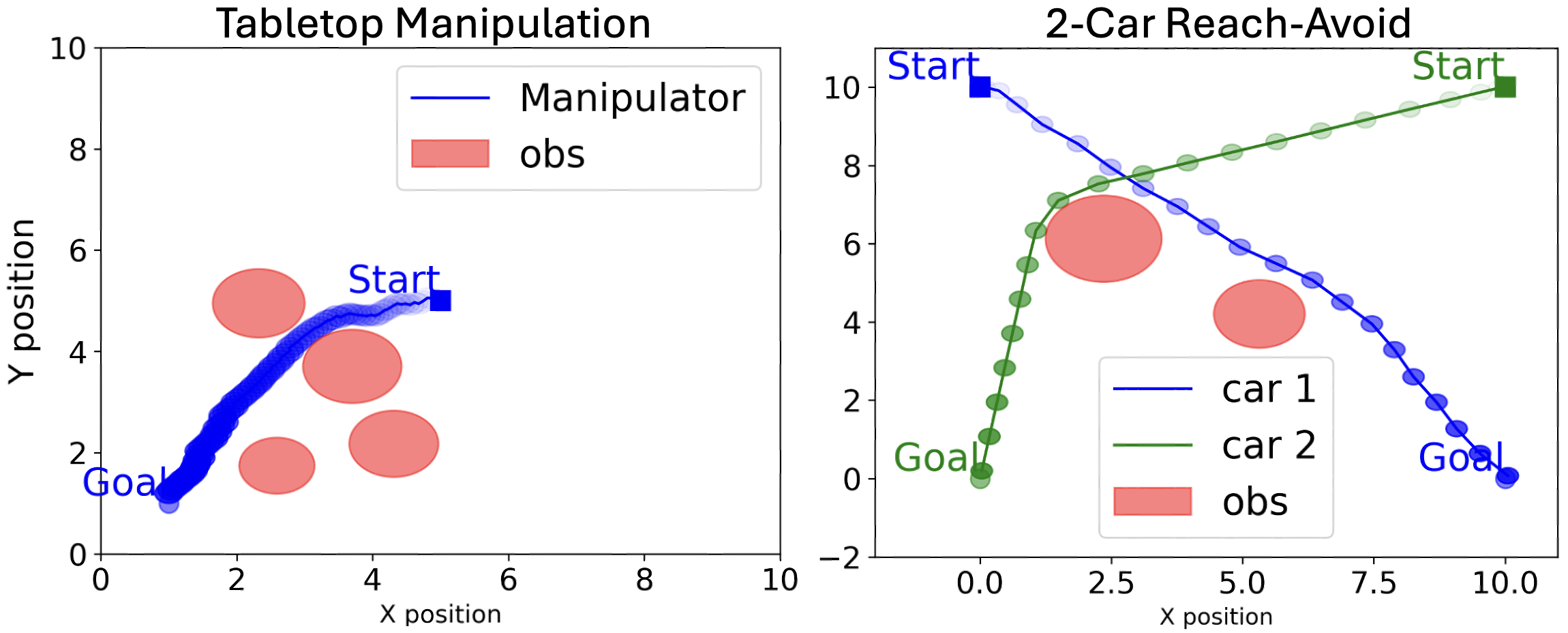
The diffusion model has shown success in generating high-quality and diverse solutions to trajectory optimization problems. However, diffusion models with neural networks inevitably make prediction errors, which leads to constraint violations such as unmet goals or collisions. This paper presents a novel constraint-aware diffusion model for trajectory optimization. We introduce a novel hybrid loss function for training that minimizes the constraint violation of diffusion samples compared to the groundtruth while recovering the original data distribution. Our model is demonstrated on tabletop manipulation and two-car reach-avoid problems, outperforming traditional diffusion models in minimizing constraint violations while generating samples close to locally optimal solutions.
Read more6/4/2024
🏅
0
Enhancing Sample Efficiency and Exploration in Reinforcement Learning through the Integration of Diffusion Models and Proximal Policy Optimization
Gao Tianci, Dmitriev D. Dmitry, Konstantin A. Neusypin, Yang Bo, Rao Shengren
Recent advancements in reinforcement learning (RL) have been fueled by large-scale data and deep neural networks, particularly for high-dimensional and complex tasks. Online RL methods like Proximal Policy Optimization (PPO) are effective in dynamic scenarios but require substantial real-time data, posing challenges in resource-constrained or slow simulation environments. Offline RL addresses this by pre-learning policies from large datasets, though its success depends on the quality and diversity of the data. This work proposes a framework that enhances PPO algorithms by incorporating a diffusion model to generate high-quality virtual trajectories for offline datasets. This approach improves exploration and sample efficiency, leading to significant gains in cumulative rewards, convergence speed, and strategy stability in complex tasks. Our contributions are threefold: we explore the potential of diffusion models in RL, particularly for offline datasets, extend the application of online RL to offline environments, and experimentally validate the performance improvements of PPO with diffusion models. These findings provide new insights and methods for applying RL to high-dimensional, complex tasks. Finally, we open-source our code at https://github.com/TianciGao/DiffPPO
Read more9/17/2024