ATraDiff: Accelerating Online Reinforcement Learning with Imaginary Trajectories
2406.04323
0
0

Abstract
Training autonomous agents with sparse rewards is a long-standing problem in online reinforcement learning (RL), due to low data efficiency. Prior work overcomes this challenge by extracting useful knowledge from offline data, often accomplished through the learning of action distribution from offline data and utilizing the learned distribution to facilitate online RL. However, since the offline data are given and fixed, the extracted knowledge is inherently limited, making it difficult to generalize to new tasks. We propose a novel approach that leverages offline data to learn a generative diffusion model, coined as Adaptive Trajectory Diffuser (ATraDiff). This model generates synthetic trajectories, serving as a form of data augmentation and consequently enhancing the performance of online RL methods. The key strength of our diffuser lies in its adaptability, allowing it to effectively handle varying trajectory lengths and mitigate distribution shifts between online and offline data. Because of its simplicity, ATraDiff seamlessly integrates with a wide spectrum of RL methods. Empirical evaluation shows that ATraDiff consistently achieves state-of-the-art performance across a variety of environments, with particularly pronounced improvements in complicated settings. Our code and demo video are available at https://atradiff.github.io .
Create account to get full access
Overview
- The paper presents a new method called ATraDiff for accelerating online reinforcement learning using imaginary trajectories.
- ATraDiff leverages a generative model to produce simulated trajectories that are similar to the agent's real experiences, and then uses these imaginary trajectories to speed up learning.
- The method is evaluated on several continuous control tasks and shown to outperform existing techniques for sample-efficient reinforcement learning.
Plain English Explanation
The researchers have developed a new technique called ATraDiff to help reinforce learning algorithms learn more quickly. In reinforcement learning, an agent explores an environment, takes actions, and receives rewards, gradually learning the optimal behavior. However, this learning process can be slow, especially in complex environments.
ATraDiff aims to speed this up by using a generative model to create simulated or "imaginary" trajectories that are similar to the agent's real experiences. The agent can then use these imaginary trajectories, in addition to its real experiences, to learn more efficiently. This is like having the agent explore the environment in simulation before trying things out in the real world.
The researchers show that ATraDiff outperforms existing methods for sample-efficient reinforcement learning on several continuous control tasks. By generating relevant imaginary trajectories, the agent can learn the optimal behavior more quickly, using fewer real-world interactions.
Technical Explanation
The key idea behind ATraDiff is to leverage a generative model to produce simulated trajectories that are similar to the agent's actual experiences in the environment. These imaginary trajectories are then used, along with the real experiences, to update the agent's policy and value function.
Specifically, ATraDiff consists of two main components:
-
Trajectory Diffusion Model: This is a generative model that learns to produce plausible state-action trajectories by modeling the transition dynamics of the environment. It is trained on the agent's real experiences.
-
Policy Optimization: The agent's policy and value function are updated using a combination of real and imaginary trajectories. The imaginary trajectories help the agent learn more efficiently by exposing it to a wider range of possible experiences.
The researchers evaluate ATraDiff on several continuous control tasks from the OpenAI Gym benchmark. The results show that ATraDiff significantly outperforms existing online reinforcement learning methods in terms of sample efficiency, achieving the same performance with fewer real-world interactions.
Critical Analysis
The paper presents a novel and promising approach for accelerating online reinforcement learning. By generating realistic imaginary trajectories, ATraDiff is able to leverage more information during the learning process, leading to faster convergence.
However, the paper does not address some potential limitations of the method:
-
Accuracy of the Trajectory Diffusion Model: The performance of ATraDiff relies heavily on the accuracy of the generative model in producing trajectories that faithfully represent the true dynamics of the environment. If the model is not sufficiently expressive or trained on enough data, the imaginary trajectories may not be representative, potentially leading to suboptimal learning.
-
Generalization to Diverse Environments: The experiments in the paper are limited to continuous control tasks from the OpenAI Gym benchmark. It's unclear how well ATraDiff would perform in more complex or diverse environments, where the dynamics may be more challenging to model.
-
Computational Overhead: Training the trajectory diffusion model and generating imaginary trajectories may add significant computational overhead, which could limit the method's applicability in real-world settings with strict resource constraints.
Future research could explore ways to address these limitations, such as developing more robust generative models or optimizing the trajectory generation process. Additionally, a more thorough evaluation across a wider range of environments would help establish the broader applicability of the ATraDiff approach.
Conclusion
The ATraDiff method proposed in this paper represents a significant advancement in the field of online reinforcement learning. By incorporating imaginary trajectories generated by a learned generative model, the agent can learn more efficiently, requiring fewer real-world interactions to achieve the same level of performance.
This has important implications for real-world applications of reinforcement learning, where sample efficiency is critical, such as robotics, autonomous vehicles, and interactive game agents. If the limitations identified in the critical analysis can be addressed, ATraDiff could become a valuable tool for accelerating the deployment of reinforcement learning algorithms in these and other domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
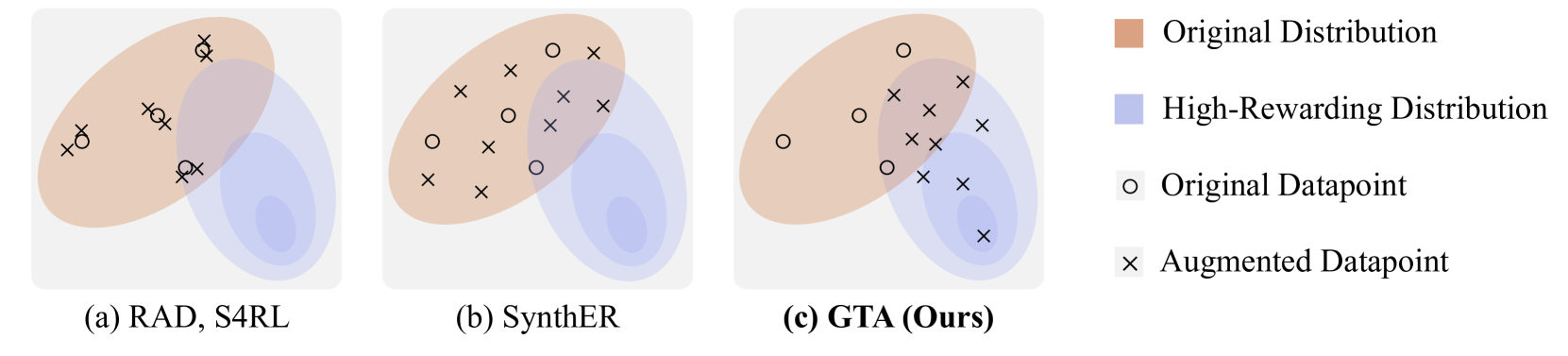
GTA: Generative Trajectory Augmentation with Guidance for Offline Reinforcement Learning
Jaewoo Lee, Sujin Yun, Taeyoung Yun, Jinkyoo Park
0
0
Offline Reinforcement Learning (Offline RL) presents challenges of learning effective decision-making policies from static datasets without any online interactions. Data augmentation techniques, such as noise injection and data synthesizing, aim to improve Q-function approximation by smoothing the learned state-action region. However, these methods often fall short of directly improving the quality of offline datasets, leading to suboptimal results. In response, we introduce textbf{GTA}, Generative Trajectory Augmentation, a novel generative data augmentation approach designed to enrich offline data by augmenting trajectories to be both high-rewarding and dynamically plausible. GTA applies a diffusion model within the data augmentation framework. GTA partially noises original trajectories and then denoises them with classifier-free guidance via conditioning on amplified return value. Our results show that GTA, as a general data augmentation strategy, enhances the performance of widely used offline RL algorithms in both dense and sparse reward settings. Furthermore, we conduct a quality analysis of data augmented by GTA and demonstrate that GTA improves the quality of the data. Our code is available at https://github.com/Jaewoopudding/GTA
6/13/2024
📊
MADiff: Offline Multi-agent Learning with Diffusion Models
Zhengbang Zhu, Minghuan Liu, Liyuan Mao, Bingyi Kang, Minkai Xu, Yong Yu, Stefano Ermon, Weinan Zhang
0
0
Diffusion model (DM) recently achieved huge success in various scenarios including offline reinforcement learning, where the diffusion planner learn to generate desired trajectories during online evaluations. However, despite the effectiveness in single-agent learning, it remains unclear how DMs can operate in multi-agent problems, where agents can hardly complete teamwork without good coordination by independently modeling each agent's trajectories. In this paper, we propose MADiff, a novel generative multi-agent learning framework to tackle this problem. MADiff is realized with an attention-based diffusion model to model the complex coordination among behaviors of multiple agents. To the best of our knowledge, MADiff is the first diffusion-based multi-agent learning framework, which behaves as both a decentralized policy and a centralized controller. During decentralized executions, MADiff simultaneously performs teammate modeling, and the centralized controller can also be applied in multi-agent trajectory predictions. Our experiments show the superior performance of MADiff compared to baseline algorithms in a wide range of multi-agent learning tasks, which emphasizes the effectiveness of MADiff in modeling complex multi-agent interactions. Our code is available at https://github.com/zbzhu99/madiff.
5/28/2024
🖼️
Contrastive Diffuser: Planning Towards High Return States via Contrastive Learning
Yixiang Shan, Zhengbang Zhu, Ting Long, Qifan Liang, Yi Chang, Weinan Zhang, Liang Yin
0
0
The performance of offline reinforcement learning (RL) is sensitive to the proportion of high-return trajectories in the offline dataset. However, in many simulation environments and real-world scenarios, there are large ratios of low-return trajectories rather than high-return trajectories, which makes learning an efficient policy challenging. In this paper, we propose a method called Contrastive Diffuser (CDiffuser) to make full use of low-return trajectories and improve the performance of offline RL algorithms. Specifically, CDiffuser groups the states of trajectories in the offline dataset into high-return states and low-return states and treats them as positive and negative samples correspondingly. Then, it designs a contrastive mechanism to pull the trajectory of an agent toward high-return states and push them away from low-return states. Through the contrast mechanism, trajectories with low returns can serve as negative examples for policy learning, guiding the agent to avoid areas associated with low returns and achieve better performance. Experiments on 14 commonly used D4RL benchmarks demonstrate the effectiveness of our proposed method. Our code is publicly available at url{https://anonymous.4open.science/r/CDiffuser}.
6/18/2024
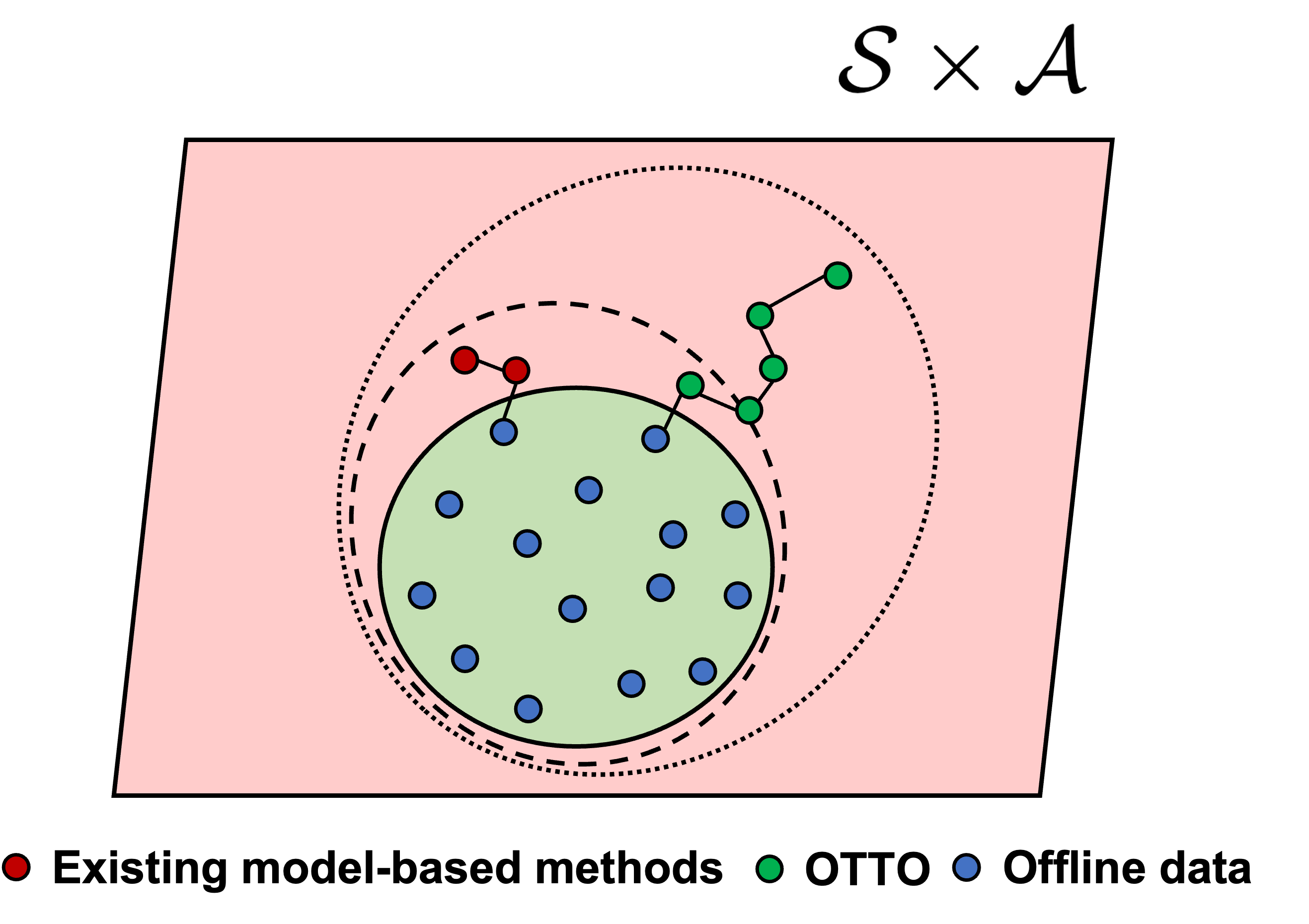
Offline Trajectory Generalization for Offline Reinforcement Learning
Ziqi Zhao, Zhaochun Ren, Liu Yang, Fajie Yuan, Pengjie Ren, Zhumin Chen, jun Ma, Xin Xin
0
0
Offline reinforcement learning (RL) aims to learn policies from static datasets of previously collected trajectories. Existing methods for offline RL either constrain the learned policy to the support of offline data or utilize model-based virtual environments to generate simulated rollouts. However, these methods suffer from (i) poor generalization to unseen states; and (ii) trivial improvement from low-qualified rollout simulation. In this paper, we propose offline trajectory generalization through world transformers for offline reinforcement learning (OTTO). Specifically, we use casual Transformers, a.k.a. World Transformers, to predict state dynamics and the immediate reward. Then we propose four strategies to use World Transformers to generate high-rewarded trajectory simulation by perturbing the offline data. Finally, we jointly use offline data with simulated data to train an offline RL algorithm. OTTO serves as a plug-in module and can be integrated with existing offline RL methods to enhance them with better generalization capability of transformers and high-rewarded data augmentation. Conducting extensive experiments on D4RL benchmark datasets, we verify that OTTO significantly outperforms state-of-the-art offline RL methods.
4/17/2024