Diffusion Models for Monocular Depth Estimation: Overcoming Challenging Conditions

0

Sign in to get full access
Overview
- Diffusion models have shown promising results for monocular depth estimation, but they face challenges in complex environments.
- This paper explores techniques to improve the performance of diffusion models in these challenging conditions.
Plain English Explanation
Monocular depth estimation is the task of determining the depth or distance of objects in a single 2D image. This is a useful capability for applications like self-driving cars, augmented reality, and robotics. Diffusion models have emerged as a powerful approach for monocular depth estimation, but they can struggle in complex environments with occlusions, varying lighting, and other factors.
This research paper explores techniques to help diffusion models overcome these challenging conditions. The key ideas include:
- Hierarchical Feature Encoding: Capturing depth cues at multiple scales to handle complex scenes.
- Effective Conditioning: Incorporating additional information, like object boundaries, to guide the depth prediction.
- Geometry-Aware Modeling: Modeling the underlying 3D geometry to improve depth estimation.
By incorporating these innovations, the authors show how diffusion models can produce more accurate and robust monocular depth estimates, even in tricky real-world scenarios.
Technical Explanation
The paper presents several advancements to improve the performance of diffusion models for monocular depth estimation:
-
Hierarchical Feature Encoding: The authors propose a multi-scale feature extraction module that captures depth cues at different resolutions. This allows the model to handle complex scenes with varying depth levels and structures.
-
Effective Conditioning: The researchers incorporate additional conditioning information, such as object boundaries, to guide the depth estimation process. This helps the model leverage relevant spatial and semantic cues to make more accurate predictions.
-
Geometry-Aware Modeling: The approach models the underlying 3D geometry of the scene to better understand the depth relationships between objects. This geometric reasoning improves the model's ability to handle occlusions and other challenging depth cues.
The paper evaluates these techniques on several monocular depth estimation benchmarks, demonstrating significant performance improvements over previous diffusion-based methods, especially in complex environments.
Critical Analysis
The paper makes a compelling case for the effectiveness of the proposed techniques in enhancing diffusion models for monocular depth estimation. The authors provide thorough experimental evaluations and comparisons to state-of-the-art methods, which lend credibility to their findings.
However, the paper does not delve into the potential limitations or failure cases of the approach. For example, it would be interesting to understand the performance of the model in extreme lighting conditions, scenes with transparent or reflective surfaces, or scenarios with very sparse depth information. Additionally, the computational complexity and inference time of the proposed model could be an area for further investigation.
Another aspect worth exploring is the generalization capabilities of the model. The authors primarily evaluate on standard benchmark datasets, but it would be valuable to assess the model's robustness and adaptability to real-world deployment scenarios with diverse and unpredictable conditions.
Overall, the research presented in this paper represents a significant advancement in the field of monocular depth estimation, and the proposed techniques could have important implications for various applications that rely on accurate depth information.
Conclusion
This paper demonstrates how diffusion models can be enhanced to overcome challenging conditions for monocular depth estimation. By incorporating hierarchical feature encoding, effective conditioning, and geometry-aware modeling, the authors have developed a robust and accurate depth estimation approach.
The technical advancements outlined in this work have the potential to enable more reliable and versatile depth perception capabilities, which could benefit a wide range of applications, from autonomous navigation and robotics to augmented reality and computational photography. As the field of computer vision continues to evolve, research like this paves the way for more robust and adaptable depth estimation solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Diffusion Models for Monocular Depth Estimation: Overcoming Challenging Conditions
Fabio Tosi, Pierluigi Zama Ramirez, Matteo Poggi
We present a novel approach designed to address the complexities posed by challenging, out-of-distribution data in the single-image depth estimation task. Starting with images that facilitate depth prediction due to the absence of unfavorable factors, we systematically generate new, user-defined scenes with a comprehensive set of challenges and associated depth information. This is achieved by leveraging cutting-edge text-to-image diffusion models with depth-aware control, known for synthesizing high-quality image content from textual prompts while preserving the coherence of 3D structure between generated and source imagery. Subsequent fine-tuning of any monocular depth network is carried out through a self-distillation protocol that takes into account images generated using our strategy and its own depth predictions on simple, unchallenging scenes. Experiments on benchmarks tailored for our purposes demonstrate the effectiveness and versatility of our proposal.
Read more7/24/2024
🔍
0
New!Fine-Tuning Image-Conditional Diffusion Models is Easier than You Think
Gonzalo Martin Garcia, Karim Abou Zeid, Christian Schmidt, Daan de Geus, Alexander Hermans, Bastian Leibe
Recent work showed that large diffusion models can be reused as highly precise monocular depth estimators by casting depth estimation as an image-conditional image generation task. While the proposed model achieved state-of-the-art results, high computational demands due to multi-step inference limited its use in many scenarios. In this paper, we show that the perceived inefficiency was caused by a flaw in the inference pipeline that has so far gone unnoticed. The fixed model performs comparably to the best previously reported configuration while being more than 200$times$ faster. To optimize for downstream task performance, we perform end-to-end fine-tuning on top of the single-step model with task-specific losses and get a deterministic model that outperforms all other diffusion-based depth and normal estimation models on common zero-shot benchmarks. We surprisingly find that this fine-tuning protocol also works directly on Stable Diffusion and achieves comparable performance to current state-of-the-art diffusion-based depth and normal estimation models, calling into question some of the conclusions drawn from prior works.
Read more9/18/2024
🖼️
0
Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, Konrad Schindler
Monocular depth estimation is a fundamental computer vision task. Recovering 3D depth from a single image is geometrically ill-posed and requires scene understanding, so it is not surprising that the rise of deep learning has led to a breakthrough. The impressive progress of monocular depth estimators has mirrored the growth in model capacity, from relatively modest CNNs to large Transformer architectures. Still, monocular depth estimators tend to struggle when presented with images with unfamiliar content and layout, since their knowledge of the visual world is restricted by the data seen during training, and challenged by zero-shot generalization to new domains. This motivates us to explore whether the extensive priors captured in recent generative diffusion models can enable better, more generalizable depth estimation. We introduce Marigold, a method for affine-invariant monocular depth estimation that is derived from Stable Diffusion and retains its rich prior knowledge. The estimator can be fine-tuned in a couple of days on a single GPU using only synthetic training data. It delivers state-of-the-art performance across a wide range of datasets, including over 20% performance gains in specific cases. Project page: https://marigoldmonodepth.github.io.
Read more4/4/2024
0
Unsupervised Monocular Depth Estimation Based on Hierarchical Feature-Guided Diffusion
Runze Liu, Dongchen Zhu, Guanghui Zhang, Yue Xu, Wenjun Shi, Xiaolin Zhang, Lei Wang, Jiamao Li
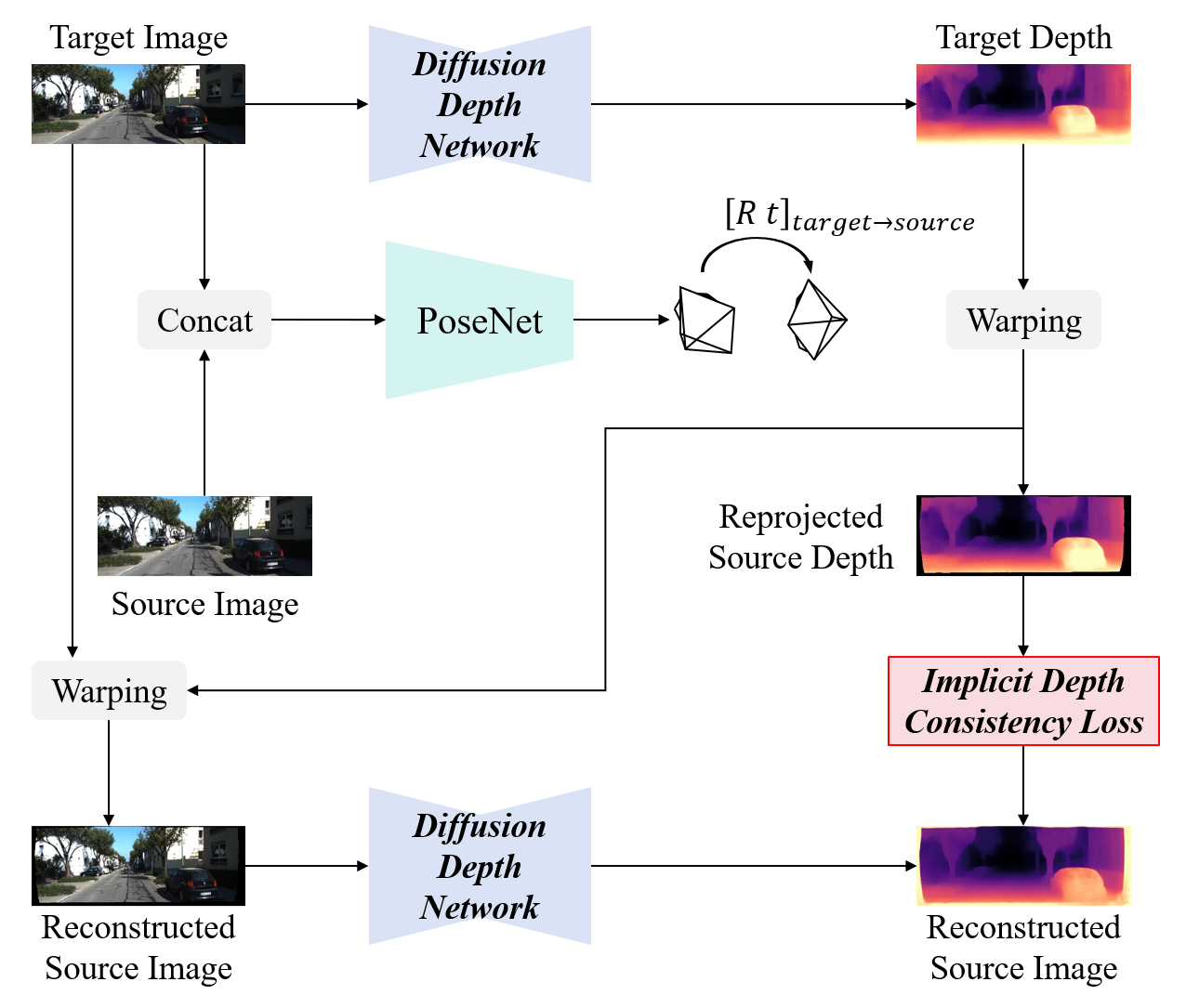
Unsupervised monocular depth estimation has received widespread attention because of its capability to train without ground truth. In real-world scenarios, the images may be blurry or noisy due to the influence of weather conditions and inherent limitations of the camera. Therefore, it is particularly important to develop a robust depth estimation model. Benefiting from the training strategies of generative networks, generative-based methods often exhibit enhanced robustness. In light of this, we employ a well-converging diffusion model among generative networks for unsupervised monocular depth estimation. Additionally, we propose a hierarchical feature-guided denoising module. This model significantly enriches the model's capacity for learning and interpreting depth distribution by fully leveraging image features to guide the denoising process. Furthermore, we explore the implicit depth within reprojection and design an implicit depth consistency loss. This loss function serves to enhance the performance of the model and ensure the scale consistency of depth within a video sequence. We conduct experiments on the KITTI, Make3D, and our self-collected SIMIT datasets. The results indicate that our approach stands out among generative-based models, while also showcasing remarkable robustness.
Read more6/17/2024