Diffusion Policy Attacker: Crafting Adversarial Attacks for Diffusion-based Policies

0

Sign in to get full access
Overview
- Discusses a new technique called "Diffusion Policy Attacker" for crafting adversarial attacks against diffusion-based machine learning models
- Demonstrates how these attacks can fool state-of-the-art diffusion models like Stable Diffusion and DALL-E 2 into generating unintended outputs
- Highlights the need for improved robustness in diffusion models as they become more widely used
Plain English Explanation
Diffusion models are a powerful type of machine learning that can generate highly realistic images, text, and other content. However, just like other AI systems, they can be vulnerable to "adversarial attacks" - subtle manipulations of the input that cause the model to make mistakes.
This paper introduces a new technique called the "Diffusion Policy Attacker" that can craft these adversarial attacks specifically for diffusion models. The researchers show how they can fool state-of-the-art diffusion models like Stable Diffusion and DALL-E 2 into generating completely different outputs than the user intended.
For example, they could prompt the model to generate an image of a dog, but the Diffusion Policy Attacker would subtly manipulate the input in a way that causes the model to generate a cat instead. These attacks work by exploiting weaknesses in how diffusion models process and combine the noisy intermediate steps of the generation process.
As diffusion models become more widely used for tasks like content creation, the researchers argue that improving their robustness to these kinds of adversarial attacks will be crucial. The Diffusion Policy Attacker technique highlights the need for further research and development to make these powerful AI systems more secure and reliable.
Technical Explanation
The key innovation in this paper is the "Diffusion Policy Attacker" - a method for crafting adversarial attacks specifically targeting diffusion-based machine learning models. Diffusion models, which have shown impressive results in generating images, text, and other content, work by iteratively adding and removing noise from an input, following a learned "diffusion process."
The Diffusion Policy Attacker exploits weaknesses in this diffusion process to subtly manipulate the input in a way that causes the model to generate unintended outputs. The researchers demonstrate these attacks on state-of-the-art diffusion models like Stable Diffusion and DALL-E 2, showing how they can fool the models into producing completely different images than the user intended.
Building on prior work on adversarial examples for vision and language models, the Diffusion Policy Attacker is designed to be more effective and efficient at generating these attacks for diffusion-based systems. The researchers also explore connections to other topics like adversarial purification and data poisoning.
Overall, this work highlights the need for improved robustness in diffusion models as they become more widely deployed, and provides a new tool for understanding and addressing their vulnerabilities.
Critical Analysis
The Diffusion Policy Attacker technique represents an important advance in understanding the security and reliability of diffusion-based AI systems. As the researchers note, the growing use of these models for high-stakes applications like content creation means that their vulnerabilities to adversarial attacks must be addressed.
While the paper provides a compelling demonstration of these attacks, there are some limitations to consider. The attacks are evaluated in a relatively controlled setting, and it's unclear how they would scale or transfer to real-world deployment scenarios. There may also be ways to defend against these attacks, such as through improved model architectures or training procedures.
Additionally, the broader societal implications of these attacks are worth further exploration. While the paper is focused on the technical details, the potential for adversarial images or content to be used for misinformation, fraud, or other harmful purposes raises important ethical questions that deserve careful consideration.
Overall, this work represents an important step forward in understanding the security of diffusion models, but there is still much more research needed to ensure the robustness and reliability of these powerful AI systems.
Conclusion
The Diffusion Policy Attacker technique introduced in this paper highlights a critical vulnerability in state-of-the-art diffusion models like Stable Diffusion and DALL-E 2. By exploiting weaknesses in the diffusion process, the researchers demonstrate how these models can be fooled into generating unintended outputs, posing a potential threat as these technologies become more widely deployed.
As diffusion models continue to advance and find new applications, addressing their susceptibility to adversarial attacks will be crucial. This paper provides a valuable tool for understanding these vulnerabilities, but also underscores the need for further research and development to improve the robustness and security of these powerful AI systems. Ensuring the reliability of diffusion models will be essential for realizing their full potential in fields like content creation, while mitigating the risks of malicious actors leveraging their weaknesses.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Diffusion Policy Attacker: Crafting Adversarial Attacks for Diffusion-based Policies
Yipu Chen, Haotian Xue, Yongxin Chen
Diffusion models (DMs) have emerged as a promising approach for behavior cloning (BC). Diffusion policies (DP) based on DMs have elevated BC performance to new heights, demonstrating robust efficacy across diverse tasks, coupled with their inherent flexibility and ease of implementation. Despite the increasing adoption of DP as a foundation for policy generation, the critical issue of safety remains largely unexplored. While previous attempts have targeted deep policy networks, DP used diffusion models as the policy network, making it ineffective to be attacked using previous methods because of its chained structure and randomness injected. In this paper, we undertake a comprehensive examination of DP safety concerns by introducing adversarial scenarios, encompassing offline and online attacks, and global and patch-based attacks. We propose DP-Attacker, a suite of algorithms that can craft effective adversarial attacks across all aforementioned scenarios. We conduct attacks on pre-trained diffusion policies across various manipulation tasks. Through extensive experiments, we demonstrate that DP-Attacker has the capability to significantly decrease the success rate of DP for all scenarios. Particularly in offline scenarios, DP-Attacker can generate highly transferable perturbations applicable to all frames. Furthermore, we illustrate the creation of adversarial physical patches that, when applied to the environment, effectively deceive the model. Video results are put in: https://sites.google.com/view/diffusion-policy-attacker.
Read more5/31/2024

0
Attacks and Defenses for Generative Diffusion Models: A Comprehensive Survey
Vu Tuan Truong, Luan Ba Dang, Long Bao Le
Diffusion models (DMs) have achieved state-of-the-art performance on various generative tasks such as image synthesis, text-to-image, and text-guided image-to-image generation. However, the more powerful the DMs, the more harmful they potentially are. Recent studies have shown that DMs are prone to a wide range of attacks, including adversarial attacks, membership inference, backdoor injection, and various multi-modal threats. Since numerous pre-trained DMs are published widely on the Internet, potential threats from these attacks are especially detrimental to the society, making DM-related security a worth investigating topic. Therefore, in this paper, we conduct a comprehensive survey on the security aspect of DMs, focusing on various attack and defense methods for DMs. First, we present crucial knowledge of DMs with five main types of DMs, including denoising diffusion probabilistic models, denoising diffusion implicit models, noise conditioned score networks, stochastic differential equations, and multi-modal conditional DMs. We further survey a variety of recent studies investigating different types of attacks that exploit the vulnerabilities of DMs. Then, we thoroughly review potential countermeasures to mitigate each of the presented threats. Finally, we discuss open challenges of DM-related security and envision certain research directions for this topic.
Read more8/9/2024
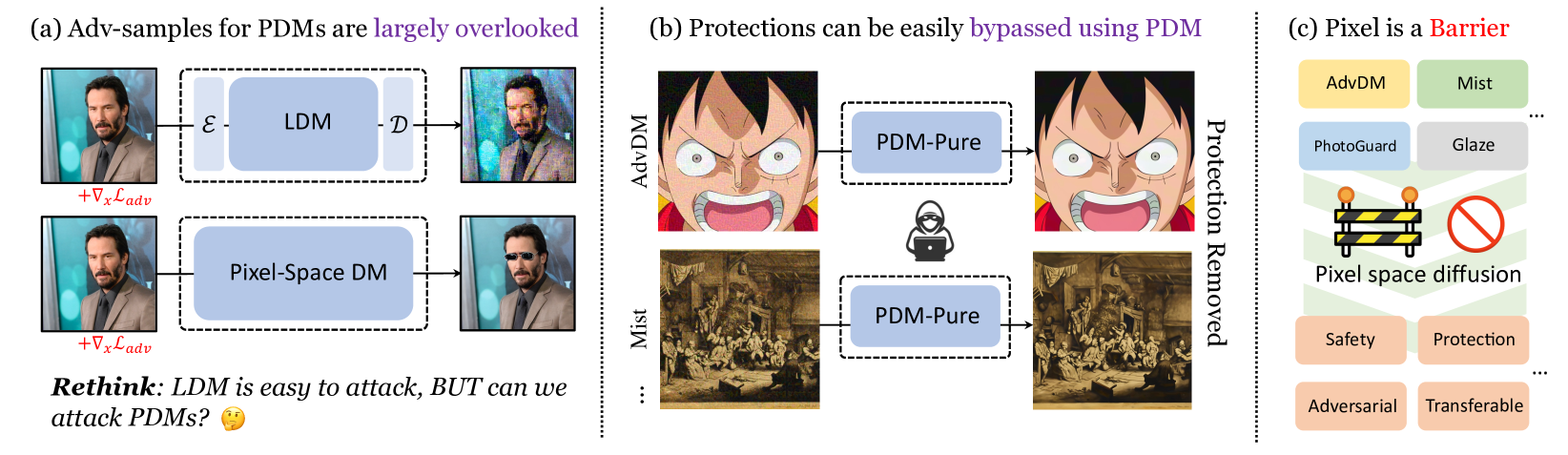
0
Pixel is a Barrier: Diffusion Models Are More Adversarially Robust Than We Think
Haotian Xue, Yongxin Chen
Adversarial examples for diffusion models are widely used as solutions for safety concerns. By adding adversarial perturbations to personal images, attackers can not edit or imitate them easily. However, it is essential to note that all these protections target the latent diffusion model (LDMs), the adversarial examples for diffusion models in the pixel space (PDMs) are largely overlooked. This may mislead us to think that the diffusion models are vulnerable to adversarial attacks like most deep models. In this paper, we show novel findings that: even though gradient-based white-box attacks can be used to attack the LDMs, they fail to attack PDMs. This finding is supported by extensive experiments of almost a wide range of attacking methods on various PDMs and LDMs with different model structures, which means diffusion models are indeed much more robust against adversarial attacks. We also find that PDMs can be used as an off-the-shelf purifier to effectively remove the adversarial patterns that were generated on LDMs to protect the images, which means that most protection methods nowadays, to some extent, cannot protect our images from malicious attacks. We hope that our insights will inspire the community to rethink the adversarial samples for diffusion models as protection methods and move forward to more effective protection. Codes are available in https://github.com/xavihart/PDM-Pure.
Read more5/3/2024

0
Real-world Adversarial Defense against Patch Attacks based on Diffusion Model
Xingxing Wei, Caixin Kang, Yinpeng Dong, Zhengyi Wang, Shouwei Ruan, Yubo Chen, Hang Su
Adversarial patches present significant challenges to the robustness of deep learning models, making the development of effective defenses become critical for real-world applications. This paper introduces DIFFender, a novel DIFfusion-based DeFender framework that leverages the power of a text-guided diffusion model to counter adversarial patch attacks. At the core of our approach is the discovery of the Adversarial Anomaly Perception (AAP) phenomenon, which enables the diffusion model to accurately detect and locate adversarial patches by analyzing distributional anomalies. DIFFender seamlessly integrates the tasks of patch localization and restoration within a unified diffusion model framework, enhancing defense efficacy through their close interaction. Additionally, DIFFender employs an efficient few-shot prompt-tuning algorithm, facilitating the adaptation of the pre-trained diffusion model to defense tasks without the need for extensive retraining. Our comprehensive evaluation, covering image classification and face recognition tasks, as well as real-world scenarios, demonstrates DIFFender's robust performance against adversarial attacks. The framework's versatility and generalizability across various settings, classifiers, and attack methodologies mark a significant advancement in adversarial patch defense strategies. Except for the popular visible domain, we have identified another advantage of DIFFender: its capability to easily expand into the infrared domain. Consequently, we demonstrate the good flexibility of DIFFender, which can defend against both infrared and visible adversarial patch attacks alternatively using a universal defense framework.
Read more9/17/2024