DiG-IN: Diffusion Guidance for Investigating Networks -- Uncovering Classifier Differences, Neuron Visualisations, and Visual Counterfactual Explanations

0

Sign in to get full access
Overview
- This paper presents a method for analyzing and explaining the decision-making process of image classifiers using diffusion guidance.
- The proposed approach aims to provide insights into how image classifiers make predictions by generating counterfactual examples that highlight the relevant and irrelevant features used by the model.
- The method leverages diffusion models, a type of generative AI model, to generate these counterfactual examples in a controlled and interpretable manner.
Plain English Explanation
The researchers developed a new way to understand how image classifiers, algorithms that can identify objects in images, make their predictions. They used a powerful type of AI model called a diffusion model to generate "counterfactual examples" - images that are very similar to the original image but are classified differently by the classifier.
By analyzing these counterfactual examples, the researchers could identify which specific features of the image the classifier is using to make its prediction. This allows them to explain the classifier's decision-making process in a more transparent and interpretable way.
The key idea is that the diffusion model can gradually transform the original image into a counterfactual example by systematically removing or adding certain visual features. By tracking this transformation process, the researchers can pinpoint which features the classifier finds relevant or irrelevant for its prediction.
This approach provides valuable insights that can help improve the reliability and trustworthiness of image classifiers, which are increasingly being used in high-stakes applications like healthcare and autonomous vehicles. Understanding how these models work under the hood is an important step towards making AI systems more transparent and accountable.
Technical Explanation
The paper introduces a method called Relevant Irrelevance that leverages diffusion models to generate counterfactual examples for explaining image classifiers.
Diffusion models are a type of generative AI that can gradually transform an input image into a completely different image by adding noise and then removing it in a controlled way. The researchers use this property to generate counterfactual examples - images that are visually similar to the original but are classified differently by the target model.
By analyzing the step-by-step transformation of the original image into the counterfactual, the researchers can identify the relevant and irrelevant features used by the image classifier to make its prediction. This information is then used to provide explanations for the classifier's decision-making process.
The paper also introduces an extension called DecodEx, which enhances the diffusion-based explanation method by incorporating a confounder detector. This helps identify spurious correlations that the classifier may be relying on, leading to more robust and reliable explanations.
Critical Analysis
The proposed approach represents an important step forward in making image classifiers more transparent and interpretable. By using diffusion models to generate counterfactual examples, the method provides a principled and controllable way to unpack the decision-making process of these black-box models.
However, the paper also acknowledges some limitations of the approach. For example, the generated counterfactual examples may not always be visually plausible or semantically meaningful, which could limit their usefulness in real-world applications. Additionally, the method relies on the performance of the underlying diffusion model, which may introduce its own biases and errors.
Further research is needed to address these challenges and improve the robustness and practicality of diffusion-based explanation methods. Exploring alternative generative techniques or incorporating additional constraints and objective functions could help generate more faithful and interpretable counterfactual examples.
It's also important to consider the broader implications of explanation methods like the one proposed in this paper. While they can certainly improve the transparency of AI systems, they do not necessarily address deeper issues of bias, fairness, and ethical alignment. Careful consideration of these factors will be crucial as these techniques are deployed in high-stakes domains.
Conclusion
This paper presents a novel method for analyzing and explaining the decision-making of image classifiers using diffusion-based generative models. By generating counterfactual examples that highlight the relevant and irrelevant features used by the classifier, the proposed approach provides valuable insights into the inner workings of these black-box models.
The ability to unpack the decision-making process of image classifiers has important implications for improving their reliability, robustness, and trustworthiness, especially in domains like healthcare and autonomous vehicles where these models are increasingly being deployed. While the current approach has some limitations, the broader direction of using generative techniques for model explanation is a promising area of research that deserves further attention and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DiG-IN: Diffusion Guidance for Investigating Networks -- Uncovering Classifier Differences, Neuron Visualisations, and Visual Counterfactual Explanations
Maximilian Augustin, Yannic Neuhaus, Matthias Hein
While deep learning has led to huge progress in complex image classification tasks like ImageNet, unexpected failure modes, e.g. via spurious features, call into question how reliably these classifiers work in the wild. Furthermore, for safety-critical tasks the black-box nature of their decisions is problematic, and explanations or at least methods which make decisions plausible are needed urgently. In this paper, we address these problems by generating images that optimize a classifier-derived objective using a framework for guided image generation. We analyze the decisions of image classifiers by visual counterfactual explanations (VCEs), detection of systematic mistakes by analyzing images where classifiers maximally disagree, and visualization of neurons and spurious features. In this way, we validate existing observations, e.g. the shape bias of adversarially robust models, as well as novel failure modes, e.g. systematic errors of zero-shot CLIP classifiers. Moreover, our VCEs outperform previous work while being more versatile.
Read more7/15/2024

0
CoLa-DCE -- Concept-guided Latent Diffusion Counterfactual Explanations
Franz Motzkus, Christian Hellert, Ute Schmid
Recent advancements in generative AI have introduced novel prospects and practical implementations. Especially diffusion models show their strength in generating diverse and, at the same time, realistic features, positioning them well for generating counterfactual explanations for computer vision models. Answering what if questions of what needs to change to make an image classifier change its prediction, counterfactual explanations align well with human understanding and consequently help in making model behavior more comprehensible. Current methods succeed in generating authentic counterfactuals, but lack transparency as feature changes are not directly perceivable. To address this limitation, we introduce Concept-guided Latent Diffusion Counterfactual Explanations (CoLa-DCE). CoLa-DCE generates concept-guided counterfactuals for any classifier with a high degree of control regarding concept selection and spatial conditioning. The counterfactuals comprise an increased granularity through minimal feature changes. The reference feature visualization ensures better comprehensibility, while the feature localization provides increased transparency of where changed what. We demonstrate the advantages of our approach in minimality and comprehensibility across multiple image classification models and datasets and provide insights into how our CoLa-DCE explanations help comprehend model errors like misclassification cases.
Read more6/5/2024
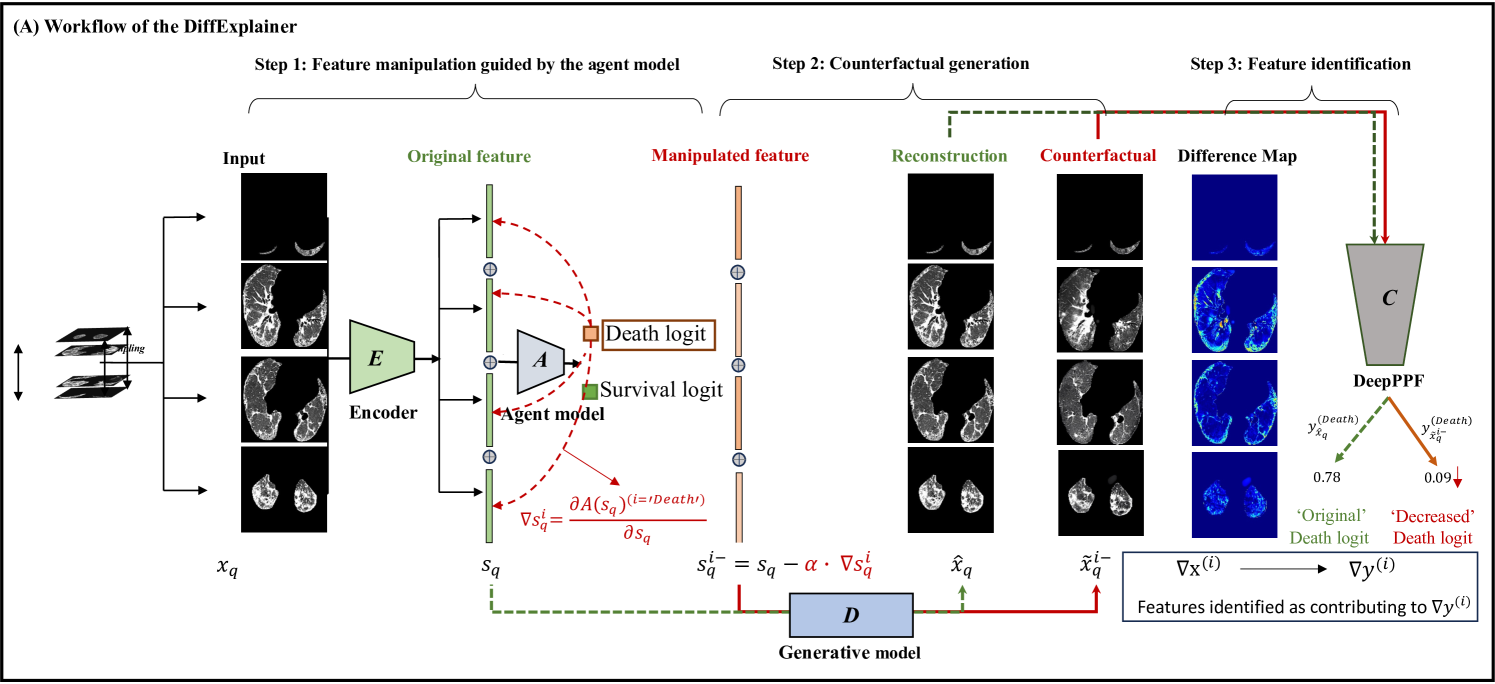
0
DiffExplainer: Unveiling Black Box Models Via Counterfactual Generation
Yingying Fang, Shuang Wu, Zihao Jin, Caiwen Xu, Shiyi Wang, Simon Walsh, Guang Yang
In the field of medical imaging, particularly in tasks related to early disease detection and prognosis, understanding the reasoning behind AI model predictions is imperative for assessing their reliability. Conventional explanation methods encounter challenges in identifying decisive features in medical image classifications, especially when discriminative features are subtle or not immediately evident. To address this limitation, we propose an agent model capable of generating counterfactual images that prompt different decisions when plugged into a black box model. By employing this agent model, we can uncover influential image patterns that impact the black model's final predictions. Through our methodology, we efficiently identify features that influence decisions of the deep black box. We validated our approach in the rigorous domain of medical prognosis tasks, showcasing its efficacy and potential to enhance the reliability of deep learning models in medical image classification compared to existing interpretation methods. The code will be publicly available at https://github.com/ayanglab/DiffExplainer.
Read more6/28/2024

0
Graph Edits for Counterfactual Explanations: A comparative study
Angeliki Dimitriou, Nikolaos Chaidos, Maria Lymperaiou, Giorgos Stamou
Counterfactuals have been established as a popular explainability technique which leverages a set of minimal edits to alter the prediction of a classifier. When considering conceptual counterfactuals on images, the edits requested should correspond to salient concepts present in the input data. At the same time, conceptual distances are defined by knowledge graphs, ensuring the optimality of conceptual edits. In this work, we extend previous endeavors on graph edits as counterfactual explanations by conducting a comparative study which encompasses both supervised and unsupervised Graph Neural Network (GNN) approaches. To this end, we pose the following significant research question: should we represent input data as graphs, which is the optimal GNN approach in terms of performance and time efficiency to generate minimal and meaningful counterfactual explanations for black-box image classifiers?
Read more4/19/2024