Digital Forgetting in Large Language Models: A Survey of Unlearning Methods
2404.02062
0
0
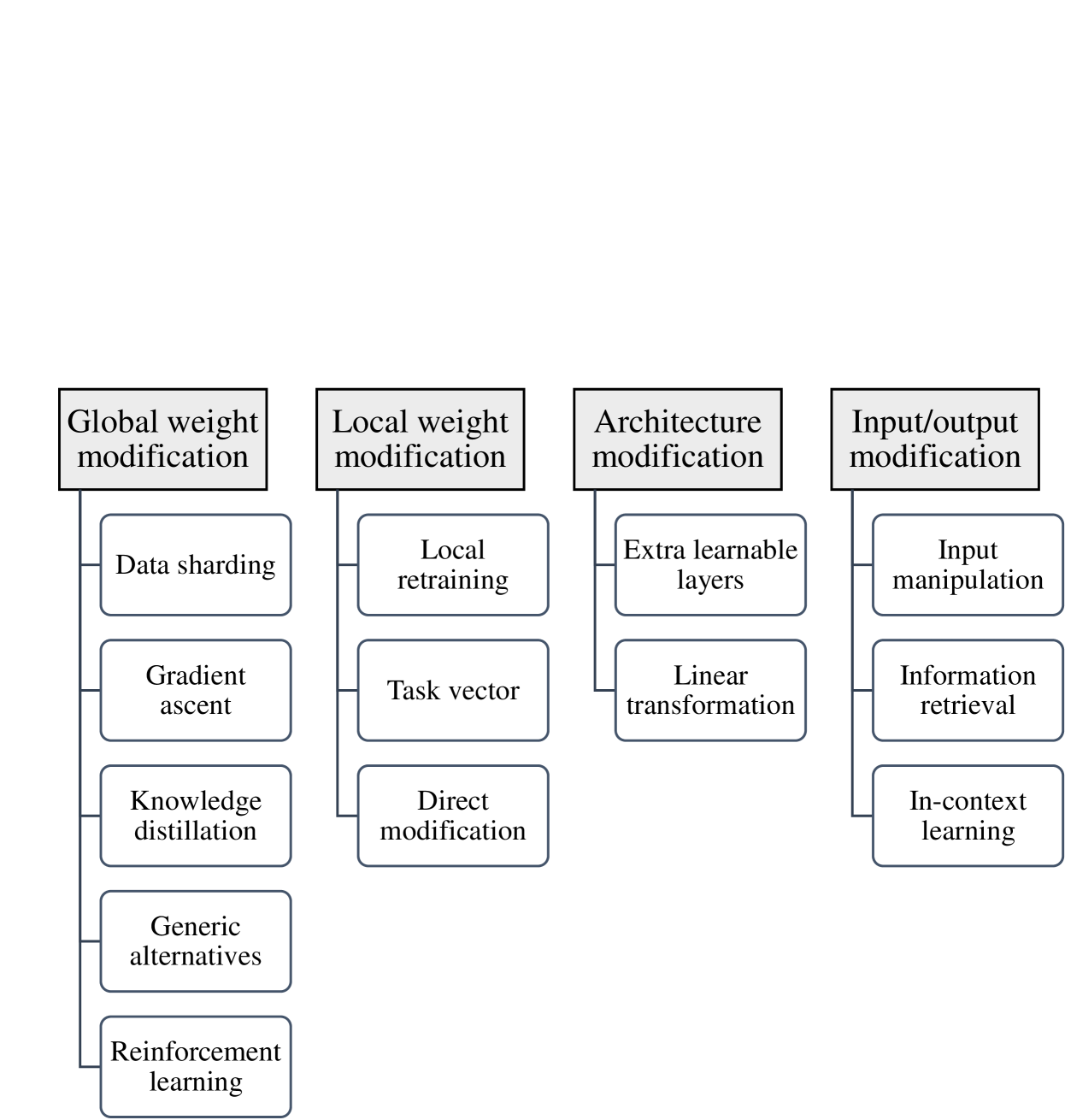
Abstract
The objective of digital forgetting is, given a model with undesirable knowledge or behavior, obtain a new model where the detected issues are no longer present. The motivations for forgetting include privacy protection, copyright protection, elimination of biases and discrimination, and prevention of harmful content generation. Effective digital forgetting has to be effective (meaning how well the new model has forgotten the undesired knowledge/behavior), retain the performance of the original model on the desirable tasks, and be scalable (in particular forgetting has to be more efficient than retraining from scratch on just the tasks/data to be retained). This survey focuses on forgetting in large language models (LLMs). We first provide background on LLMs, including their components, the types of LLMs, and their usual training pipeline. Second, we describe the motivations, types, and desired properties of digital forgetting. Third, we introduce the approaches to digital forgetting in LLMs, among which unlearning methodologies stand out as the state of the art. Fourth, we provide a detailed taxonomy of machine unlearning methods for LLMs, and we survey and compare current approaches. Fifth, we detail datasets, models and metrics used for the evaluation of forgetting, retaining and runtime. Sixth, we discuss challenges in the area. Finally, we provide some concluding remarks.
Create account to get full access
Overview
- This paper provides a survey of methods for "unlearning" or removing information from large language models (LLMs).
- LLMs are powerful AI systems that can generate human-like text, but they can also absorb unwanted biases or sensitive information during training.
- The paper explores techniques for selectively removing or "forgetting" certain knowledge or behaviors from LLMs after training, known as "digital forgetting."
Plain English Explanation
Large language models are AI systems that can understand and generate human-like text. They are trained on enormous datasets of online text, which allows them to become incredibly knowledgeable and capable. However, this training process can also lead them to absorb unwanted information, biases, or behaviors.
The idea of "digital forgetting" refers to methods that can selectively remove or "unlearn" certain knowledge or tendencies from these large language models after they've been trained. This is important because LLMs are being used in an increasing number of real-world applications, and it's crucial that they behave in safe and ethical ways.
The paper surveys different techniques that researchers have developed for digital forgetting. Some approaches focus on modifying the model's internal structure or training process, while others involve post-processing the model after training to remove specific information. The goal is to give LLM developers more tools to control what their models know and how they behave.
Technical Explanation
The paper provides an overview of the components that make up large language models, including the transformer architecture and techniques like transfer learning and fine-tuning. It then delves into the various "unlearning" or "forgetting" methods that have been proposed to selectively remove information from trained LLMs.
These methods include:
- Data Editing: Modifying the training data to remove or obscure specific content.
- Regularization: Incorporating loss terms during training to discourage the model from learning certain behaviors.
- Model Editingd: Directly altering the model's parameters or architecture to erase unwanted knowledge.
- Prompt Engineering: Designing prompts that steer the model away from producing problematic outputs.
- Post-processing: Applying filters or transformations to the model's outputs to remove sensitive content.
The paper discusses the pros and cons of each approach, as well as their potential applications and limitations. It highlights key research challenges, such as ensuring the effectiveness and stability of unlearning, preserving useful knowledge, and scaling the techniques to very large models.
Critical Analysis
The paper provides a comprehensive survey of digital forgetting methods, but it also acknowledges that this is a complex and challenging problem. Completely removing knowledge from a large neural network is difficult, and there are often tradeoffs between the effectiveness of unlearning and the model's overall performance and capabilities.
Additionally, the paper notes that many of the proposed techniques have only been tested on relatively small-scale models, and it's unclear how well they would scale to the massive LLMs used in industry. There are also concerns about the potential for abuse, as unlearning methods could theoretically be used to remove important historical information or silence certain viewpoints.
Overall, the research in this area is still quite nascent, and there is significant room for improvement and further exploration. Developing robust and trustworthy digital forgetting capabilities will be an important challenge as LLMs become more pervasive in society.
Conclusion
This paper provides a valuable survey of the current state of research on digital forgetting in large language models. As these AI systems become more powerful and ubiquitous, the ability to selectively remove or "unlearn" certain information will be crucial for ensuring their safety and ethical deployment.
The various unlearning techniques explored in the paper offer promising avenues for LLM developers to gain greater control over their models' behavior and knowledge. However, significant challenges remain, particularly around the scalability and reliability of these methods.
Continued research and innovation in this area will be essential as we work to harness the transformative potential of large language models while mitigating the risks and unintended consequences that can arise from their unchecked development. This paper serves as an important step in advancing our understanding of digital forgetting and its role in the responsible advancement of AI technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Rethinking Machine Unlearning for Large Language Models
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Xiaojun Xu, Yuguang Yao, Hang Li, Kush R. Varshney, Mohit Bansal, Sanmi Koyejo, Yang Liu
0
0
We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illegal information) and the associated model capabilities, while maintaining the integrity of essential knowledge generation and not affecting causally unrelated information. We envision LLM unlearning becoming a pivotal element in the life-cycle management of LLMs, potentially standing as an essential foundation for developing generative AI that is not only safe, secure, and trustworthy, but also resource-efficient without the need of full retraining. We navigate the unlearning landscape in LLMs from conceptual formulation, methodologies, metrics, and applications. In particular, we highlight the often-overlooked aspects of existing LLM unlearning research, e.g., unlearning scope, data-model interaction, and multifaceted efficacy assessment. We also draw connections between LLM unlearning and related areas such as model editing, influence functions, model explanation, adversarial training, and reinforcement learning. Furthermore, we outline an effective assessment framework for LLM unlearning and explore its applications in copyright and privacy safeguards and sociotechnical harm reduction.
4/8/2024

Machine Unlearning in Large Language Models
Saaketh Koundinya Gundavarapu, Shreya Agarwal, Arushi Arora, Chandana Thimmalapura Jagadeeshaiah
0
0
Machine unlearning, a novel area within artificial intelligence, focuses on addressing the challenge of selectively forgetting or reducing undesirable knowledge or behaviors in machine learning models, particularly in the context of large language models (LLMs). This paper introduces a methodology to align LLMs, such as Open Pre-trained Transformer Language Models, with ethical, privacy, and safety standards by leveraging the gradient ascent algorithm for knowledge unlearning. Our approach aims to selectively erase or modify learned information in LLMs, targeting harmful responses and copyrighted content. This paper presents a dual-pronged approach to enhance the ethical and safe behavior of large language models (LLMs) by addressing the issues of harmful responses and copyrighted content. To mitigate harmful responses, we applied gradient ascent on the PKU dataset, achieving a 75% reduction in harmful responses for Open Pre-trained Transformer Language Models (OPT1.3b and OPT2.7b) citet{zhang2022opt} while retaining previous knowledge using the TruthfulQA dataset citet{DBLP:journals/corr/abs-2109-07958}. For handling copyrighted content, we constructed a custom dataset based on the Lord of the Rings corpus and aligned LLMs (OPT1.3b and OPT2.7b) citet{zhang2022opt} through LoRA: Low-Rank Adaptation of Large Language Models citet{DBLP:journals/corr/abs-2106-09685} finetuning. Subsequently, we employed gradient ascent to unlearn the Lord of the Rings content, resulting in a remarkable reduction in the presence of copyrighted material. To maintain a diverse knowledge base, we utilized the Book Corpus dataset. Additionally, we propose a new evaluation technique for assessing the effectiveness of harmful unlearning.
5/27/2024
💬
To Each (Textual Sequence) Its Own: Improving Memorized-Data Unlearning in Large Language Models
George-Octavian Barbulescu, Peter Triantafillou
0
0
LLMs have been found to memorize training textual sequences and regurgitate verbatim said sequences during text generation time. This fact is known to be the cause of privacy and related (e.g., copyright) problems. Unlearning in LLMs then takes the form of devising new algorithms that will properly deal with these side-effects of memorized data, while not hurting the model's utility. We offer a fresh perspective towards this goal, namely, that each textual sequence to be forgotten should be treated differently when being unlearned based on its degree of memorization within the LLM. We contribute a new metric for measuring unlearning quality, an adversarial attack showing that SOTA algorithms lacking this perspective fail for privacy, and two new unlearning methods based on Gradient Ascent and Task Arithmetic, respectively. A comprehensive performance evaluation across an extensive suite of NLP tasks then mapped the solution space, identifying the best solutions under different scales in model capacities and forget set sizes and quantified the gains of the new approaches.
5/7/2024
⛏️
Machine Unlearning: A Comprehensive Survey
Weiqi Wang, Zhiyi Tian, Shui Yu
0
0
As the right to be forgotten has been legislated worldwide, many studies attempt to design unlearning mechanisms to protect users' privacy when they want to leave machine learning service platforms. Specifically, machine unlearning is to make a trained model to remove the contribution of an erased subset of the training dataset. This survey aims to systematically classify a wide range of machine unlearning and discuss their differences, connections and open problems. We categorize current unlearning methods into four scenarios: centralized unlearning, distributed and irregular data unlearning, unlearning verification, and privacy and security issues in unlearning. Since centralized unlearning is the primary domain, we use two parts to introduce: firstly, we classify centralized unlearning into exact unlearning and approximate unlearning; secondly, we offer a detailed introduction to the techniques of these methods. Besides the centralized unlearning, we notice some studies about distributed and irregular data unlearning and introduce federated unlearning and graph unlearning as the two representative directions. After introducing unlearning methods, we review studies about unlearning verification. Moreover, we consider the privacy and security issues essential in machine unlearning and organize the latest related literature. Finally, we discuss the challenges of various unlearning scenarios and address the potential research directions.
5/14/2024