Dimba: Transformer-Mamba Diffusion Models
2406.01159
0
0

Abstract
This paper unveils Dimba, a new text-to-image diffusion model that employs a distinctive hybrid architecture combining Transformer and Mamba elements. Specifically, Dimba sequentially stacked blocks alternate between Transformer and Mamba layers, and integrate conditional information through the cross-attention layer, thus capitalizing on the advantages of both architectural paradigms. We investigate several optimization strategies, including quality tuning, resolution adaption, and identify critical configurations necessary for large-scale image generation. The model's flexible design supports scenarios that cater to specific resource constraints and objectives. When scaled appropriately, Dimba offers substantial throughput and a reduced memory footprint relative to conventional pure Transformers-based benchmarks. Extensive experiments indicate that Dimba achieves comparable performance compared with benchmarks in terms of image quality, artistic rendering, and semantic control. We also report several intriguing properties of architecture discovered during evaluation and release checkpoints in experiments. Our findings emphasize the promise of large-scale hybrid Transformer-Mamba architectures in the foundational stage of diffusion models, suggesting a bright future for text-to-image generation.
Create account to get full access
Overview
- This paper introduces a novel transformer-based diffusion model called "Dimba" that can generate high-quality images efficiently.
- The model leverages a transformer-based architecture and a technique called "Mamba" to achieve state-of-the-art performance on various image generation benchmarks.
- The authors demonstrate Dimba's capabilities in generating diverse and realistic images across different domains, including scaling-diffusion-mamba-bidirectional-ssms-efficient-image, dim-diffusion-mamba-efficient-high-resolution-image, pointramba-hybrid-transformer-mamba-framework-point-cloud, and fusionmamba-dynamic-feature-enhancement-multimodal-image-fusion.
Plain English Explanation
The paper introduces a new type of AI model called "Dimba" that can create realistic-looking images. Dimba uses a unique combination of two different AI techniques: transformers and diffusion models.
Transformers are a type of AI model that can understand and generate language very well. Diffusion models are a newer type of AI that can create images by gradually adding noise to a simple starting image and then removing the noise in a clever way.
By combining these two techniques, the researchers were able to create an AI that can generate high-quality, diverse images across a variety of domains, from scaling-diffusion-mamba-bidirectional-ssms-efficient-image to pointramba-hybrid-transformer-mamba-framework-point-cloud. The key innovation is a technique called "Mamba" that helps the model generate images more efficiently.
Overall, this research represents an exciting advance in the field of AI-generated images, with Dimba showing the potential to create highly realistic and diverse images across many different applications.
Technical Explanation
The paper introduces a novel diffusion model architecture called "Dimba" that leverages transformer-based components and a technique called "Mamba" to achieve state-of-the-art performance on various image generation tasks.
The core Dimba model consists of a transformer-based encoder and a diffusion-based decoder. The transformer encoder takes the input image and encodes it into a compact representation, while the diffusion decoder progressively refines this representation to generate the final output image.
The key innovation in Dimba is the "Mamba" module, which the authors integrate into the diffusion decoder. Mamba improves the efficiency and stability of the diffusion process by introducing a bidirectional sampling scheme and a self-supervised masked attention mechanism. This allows Dimba to generate high-resolution images more quickly and with better fidelity compared to previous diffusion models.
The authors evaluate Dimba on a range of image generation benchmarks, including scaling-diffusion-mamba-bidirectional-ssms-efficient-image, dim-diffusion-mamba-efficient-high-resolution-image, pointramba-hybrid-transformer-mamba-framework-point-cloud, and fusionmamba-dynamic-feature-enhancement-multimodal-image-fusion. The results demonstrate Dimba's ability to generate diverse and realistic images across a variety of domains, outperforming previous state-of-the-art diffusion models.
Critical Analysis
The paper provides a thorough evaluation of the Dimba model and its performance across multiple benchmarks. However, the authors acknowledge several limitations and areas for future research.
One limitation is that the current Dimba model is primarily focused on unconditional image generation, and it would be valuable to explore its capabilities in conditional tasks, such as mambadfuse-mamba-based-dual-phase-model-multi, where the model generates images conditioned on additional input information.
Additionally, while the authors demonstrate Dimba's efficiency in generating high-resolution images, there may be opportunities to further improve its computational and memory efficiency, particularly for deployment in resource-constrained settings.
Another area for further research could be investigating the potential biases and limitations of the training data used to develop Dimba, and exploring techniques to mitigate any undesirable biases in the generated images.
Overall, the Dimba model represents an exciting advancement in the field of diffusion-based image generation, and the authors have provided a solid foundation for future research and development in this area.
Conclusion
The Dimba paper introduces a novel transformer-based diffusion model that can generate high-quality, diverse images across a variety of domains, including scaling-diffusion-mamba-bidirectional-ssms-efficient-image, dim-diffusion-mamba-efficient-high-resolution-image, pointramba-hybrid-transformer-mamba-framework-point-cloud, and fusionmamba-dynamic-feature-enhancement-multimodal-image-fusion.
The key innovations in Dimba are the integration of transformer-based components and the "Mamba" technique, which improve the efficiency and stability of the diffusion process. The results demonstrate Dimba's strong performance compared to previous state-of-the-art diffusion models, suggesting that this approach could have a significant impact on the field of AI-generated imagery and its many applications.
While the paper highlights several exciting aspects of the Dimba model, it also acknowledges limitations and areas for future research, such as exploring conditional image generation and improving computational efficiency. Addressing these challenges could further enhance the capabilities and real-world applicability of this innovative diffusion model.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Scaling Diffusion Mamba with Bidirectional SSMs for Efficient Image and Video Generation
Shentong Mo, Yapeng Tian
0
0
In recent developments, the Mamba architecture, known for its selective state space approach, has shown potential in the efficient modeling of long sequences. However, its application in image generation remains underexplored. Traditional diffusion transformers (DiT), which utilize self-attention blocks, are effective but their computational complexity scales quadratically with the input length, limiting their use for high-resolution images. To address this challenge, we introduce a novel diffusion architecture, Diffusion Mamba (DiM), which foregoes traditional attention mechanisms in favor of a scalable alternative. By harnessing the inherent efficiency of the Mamba architecture, DiM achieves rapid inference times and reduced computational load, maintaining linear complexity with respect to sequence length. Our architecture not only scales effectively but also outperforms existing diffusion transformers in both image and video generation tasks. The results affirm the scalability and efficiency of DiM, establishing a new benchmark for image and video generation techniques. This work advances the field of generative models and paves the way for further applications of scalable architectures.
5/28/2024
🖼️
DiM: Diffusion Mamba for Efficient High-Resolution Image Synthesis
Yao Teng, Yue Wu, Han Shi, Xuefei Ning, Guohao Dai, Yu Wang, Zhenguo Li, Xihui Liu
0
0
Diffusion models have achieved great success in image generation, with the backbone evolving from U-Net to Vision Transformers. However, the computational cost of Transformers is quadratic to the number of tokens, leading to significant challenges when dealing with high-resolution images. In this work, we propose Diffusion Mamba (DiM), which combines the efficiency of Mamba, a sequence model based on State Space Models (SSM), with the expressive power of diffusion models for efficient high-resolution image synthesis. To address the challenge that Mamba cannot generalize to 2D signals, we make several architecture designs including multi-directional scans, learnable padding tokens at the end of each row and column, and lightweight local feature enhancement. Our DiM architecture achieves inference-time efficiency for high-resolution images. In addition, to further improve training efficiency for high-resolution image generation with DiM, we investigate ``weak-to-strong'' training strategy that pretrains DiM on low-resolution images ($256times 256$) and then finetune it on high-resolution images ($512 times 512$). We further explore training-free upsampling strategies to enable the model to generate higher-resolution images (e.g., $1024times 1024$ and $1536times 1536$) without further fine-tuning. Experiments demonstrate the effectiveness and efficiency of our DiM.
5/24/2024
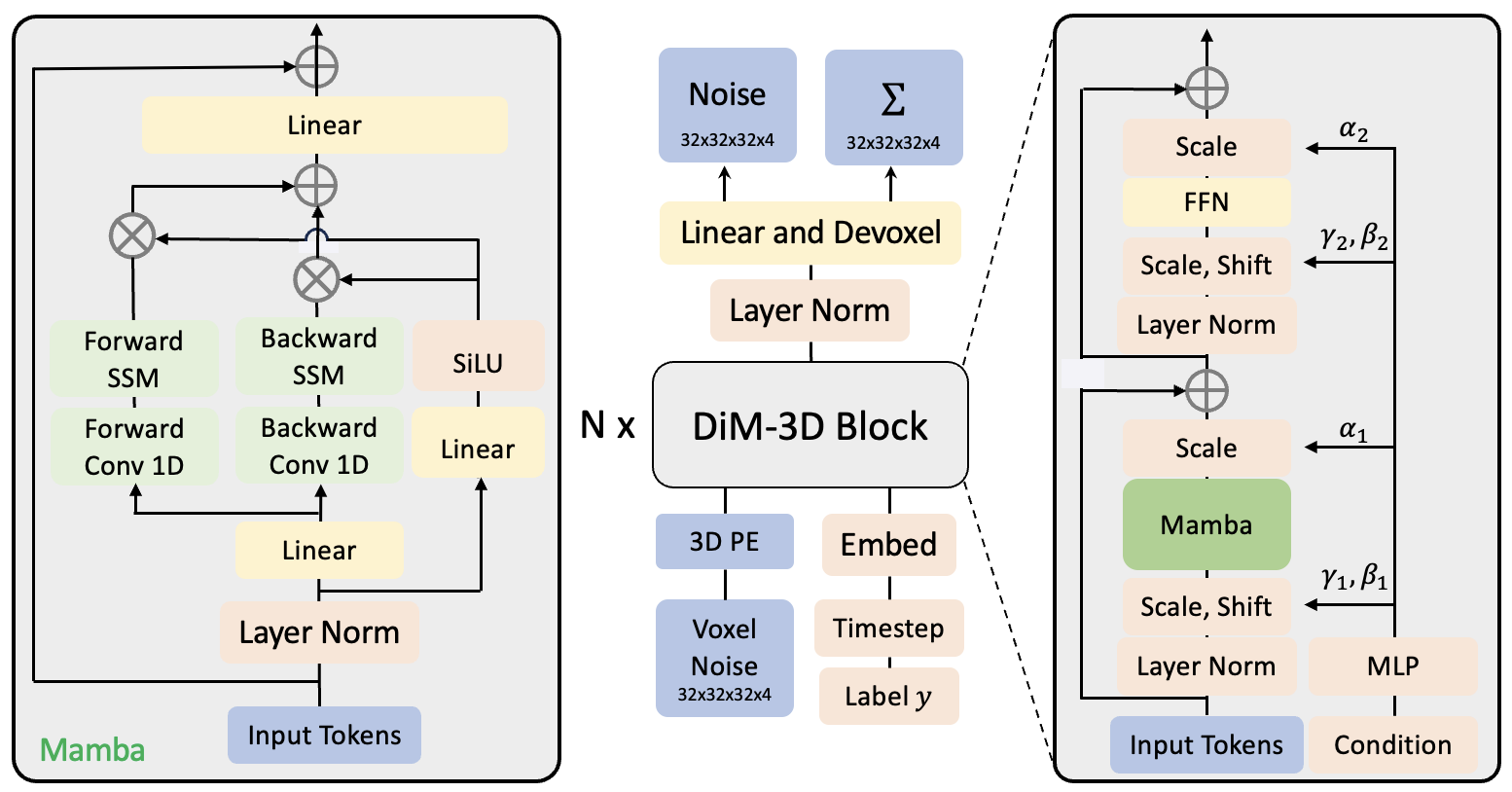
Efficient 3D Shape Generation via Diffusion Mamba with Bidirectional SSMs
Shentong Mo
0
0
Recent advancements in sequence modeling have led to the development of the Mamba architecture, noted for its selective state space approach, offering a promising avenue for efficient long sequence handling. However, its application in 3D shape generation, particularly at high resolutions, remains underexplored. Traditional diffusion transformers (DiT) with self-attention mechanisms, despite their potential, face scalability challenges due to the cubic complexity of attention operations as input length increases. This complexity becomes a significant hurdle when dealing with high-resolution voxel sizes. To address this challenge, we introduce a novel diffusion architecture tailored for 3D point clouds generation-Diffusion Mamba (DiM-3D). This architecture forgoes traditional attention mechanisms, instead utilizing the inherent efficiency of the Mamba architecture to maintain linear complexity with respect to sequence length. DiM-3D is characterized by fast inference times and substantially lower computational demands, quantified in reduced Gflops, thereby addressing the key scalability issues of prior models. Our empirical results on the ShapeNet benchmark demonstrate that DiM-3D achieves state-of-the-art performance in generating high-fidelity and diverse 3D shapes. Additionally, DiM-3D shows superior capabilities in tasks like 3D point cloud completion. This not only proves the model's scalability but also underscores its efficiency in generating detailed, high-resolution voxels necessary for advanced 3D shape modeling, particularly excelling in environments requiring high-resolution voxel sizes. Through these findings, we illustrate the exceptional scalability and efficiency of the Diffusion Mamba framework in 3D shape generation, setting a new standard for the field and paving the way for future explorations in high-resolution 3D modeling technologies.
6/10/2024
Soft Masked Mamba Diffusion Model for CT to MRI Conversion
Zhenbin Wang, Lei Zhang, Lituan Wang, Zhenwei Zhang
0
0
Magnetic Resonance Imaging (MRI) and Computed Tomography (CT) are the predominant modalities utilized in the field of medical imaging. Although MRI capture the complexity of anatomical structures with greater detail than CT, it entails a higher financial costs and requires longer image acquisition times. In this study, we aim to train latent diffusion model for CT to MRI conversion, replacing the commonly-used U-Net or Transformer backbone with a State-Space Model (SSM) called Mamba that operates on latent patches. First, we noted critical oversights in the scan scheme of most Mamba-based vision methods, including inadequate attention to the spatial continuity of patch tokens and the lack of consideration for their varying importance to the target task. Secondly, extending from this insight, we introduce Diffusion Mamba (DiffMa), employing soft masked to integrate Cross-Sequence Attention into Mamba and conducting selective scan in a spiral manner. Lastly, extensive experiments demonstrate impressive performance by DiffMa in medical image generation tasks, with notable advantages in input scaling efficiency over existing benchmark models. The code and models are available at https://github.com/wongzbb/DiffMa-Diffusion-Mamba
6/26/2024