Soft Masked Mamba Diffusion Model for CT to MRI Conversion

0
Sign in to get full access
Overview
- This paper introduces a new diffusion model called the Soft Masked Mamba Diffusion (SMMD) model for converting CT (Computed Tomography) images to MRI (Magnetic Resonance Imaging) images.
- The model uses a soft masking technique to selectively apply the diffusion process to different regions of the input CT image, improving the quality of the generated MRI images.
- The SMMD model outperforms existing state-of-the-art methods for CT to MRI conversion, demonstrating its effectiveness and potential applications in medical imaging.
Plain English Explanation
The paper presents a new Soft Masked Mamba Diffusion (SMMD) model for converting CT scans to MRI images. CT and MRI are two different medical imaging techniques that provide complementary information about the human body. However, converting between the two can be challenging.
The SMMD model uses a "soft masking" approach to selectively apply a diffusion process to different regions of the input CT image. This helps the model focus on the most important parts of the image and generate a more accurate MRI output. The diffusion process is inspired by the Mamba diffusion model, which has been shown to be effective for medical image generation.
The researchers tested the SMMD model on a dataset of CT and MRI image pairs and found that it outperformed other state-of-the-art methods for CT to MRI conversion. This suggests the SMMD model could be a valuable tool for medical professionals who need to convert between these two imaging modalities, for example, when planning treatments or analyzing patient data.
Technical Explanation
The Soft Masked Mamba Diffusion (SMMD) model builds upon the success of the Mamba diffusion model for medical image generation. It introduces a soft masking technique to selectively apply the diffusion process to different regions of the input CT image, improving the quality of the generated MRI images.
The key elements of the SMMD model include:
-
Soft Masking: The model generates a soft mask that assigns different weights to different regions of the input CT image. This allows the diffusion process to focus more on the important regions, resulting in a more accurate MRI output.
-
Mamba Diffusion: The core of the SMMD model is the Mamba diffusion process, which has been shown to be effective for generating high-quality medical images.
-
Architecture: The SMMD model uses a U-Net-based architecture to encode the input CT image and generate the soft mask and the final MRI output.
The researchers evaluated the SMMD model on a dataset of paired CT and MRI images and found that it outperformed other state-of-the-art methods for CT to MRI conversion. This suggests the SMMD model could be a valuable tool for medical professionals working with these imaging modalities.
Critical Analysis
The paper presents a compelling approach to the challenging problem of CT to MRI conversion, but it also acknowledges several limitations and areas for further research:
- The dataset used for evaluation is relatively small, and the model's performance on larger, more diverse datasets is yet to be explored.
- The soft masking technique, while effective, may not be optimal for all types of medical images or applications. Exploring alternative masking strategies could lead to further improvements.
- The Mamba diffusion process used in the SMMD model is a complex and computationally intensive process. Investigating ways to optimize its efficiency could make the model more practical for real-world deployment.
- The paper does not address the model's robustness to variations in imaging protocols, patient characteristics, or other factors that could impact its performance in clinical settings.
Overall, the SMMD model represents an exciting development in medical image conversion, but further research and validation will be necessary to fully assess its potential and limitations.
Conclusion
The Soft Masked Mamba Diffusion (SMMD) model introduced in this paper offers a novel approach to converting CT images to MRI images. By leveraging a soft masking technique and the Mamba diffusion process, the SMMD model outperforms existing state-of-the-art methods for this task.
The successful application of the SMMD model to CT to MRI conversion suggests its potential for broader use in medical imaging, such as efficient 3D shape generation or bidirectional state-space modeling. As the researchers continue to refine and validate the SMMD model, it could become an invaluable tool for medical professionals who need to work with different imaging modalities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Soft Masked Mamba Diffusion Model for CT to MRI Conversion
Zhenbin Wang, Lei Zhang, Lituan Wang, Zhenwei Zhang
Magnetic Resonance Imaging (MRI) and Computed Tomography (CT) are the predominant modalities utilized in the field of medical imaging. Although MRI capture the complexity of anatomical structures with greater detail than CT, it entails a higher financial costs and requires longer image acquisition times. In this study, we aim to train latent diffusion model for CT to MRI conversion, replacing the commonly-used U-Net or Transformer backbone with a State-Space Model (SSM) called Mamba that operates on latent patches. First, we noted critical oversights in the scan scheme of most Mamba-based vision methods, including inadequate attention to the spatial continuity of patch tokens and the lack of consideration for their varying importance to the target task. Secondly, extending from this insight, we introduce Diffusion Mamba (DiffMa), employing soft masked to integrate Cross-Sequence Attention into Mamba and conducting selective scan in a spiral manner. Lastly, extensive experiments demonstrate impressive performance by DiffMa in medical image generation tasks, with notable advantages in input scaling efficiency over existing benchmark models. The code and models are available at https://github.com/wongzbb/DiffMa-Diffusion-Mamba
Read more6/26/2024
🖼️
0
DiM: Diffusion Mamba for Efficient High-Resolution Image Synthesis
Yao Teng, Yue Wu, Han Shi, Xuefei Ning, Guohao Dai, Yu Wang, Zhenguo Li, Xihui Liu
Diffusion models have achieved great success in image generation, with the backbone evolving from U-Net to Vision Transformers. However, the computational cost of Transformers is quadratic to the number of tokens, leading to significant challenges when dealing with high-resolution images. In this work, we propose Diffusion Mamba (DiM), which combines the efficiency of Mamba, a sequence model based on State Space Models (SSM), with the expressive power of diffusion models for efficient high-resolution image synthesis. To address the challenge that Mamba cannot generalize to 2D signals, we make several architecture designs including multi-directional scans, learnable padding tokens at the end of each row and column, and lightweight local feature enhancement. Our DiM architecture achieves inference-time efficiency for high-resolution images. In addition, to further improve training efficiency for high-resolution image generation with DiM, we investigate weak-to-strong training strategy that pretrains DiM on low-resolution images ($256times 256$) and then finetune it on high-resolution images ($512 times 512$). We further explore training-free upsampling strategies to enable the model to generate higher-resolution images (e.g., $1024times 1024$ and $1536times 1536$) without further fine-tuning. Experiments demonstrate the effectiveness and efficiency of our DiM. The code of our work is available here: {url{https://github.com/tyshiwo1/DiM-DiffusionMamba/}}.
Read more7/11/2024
0
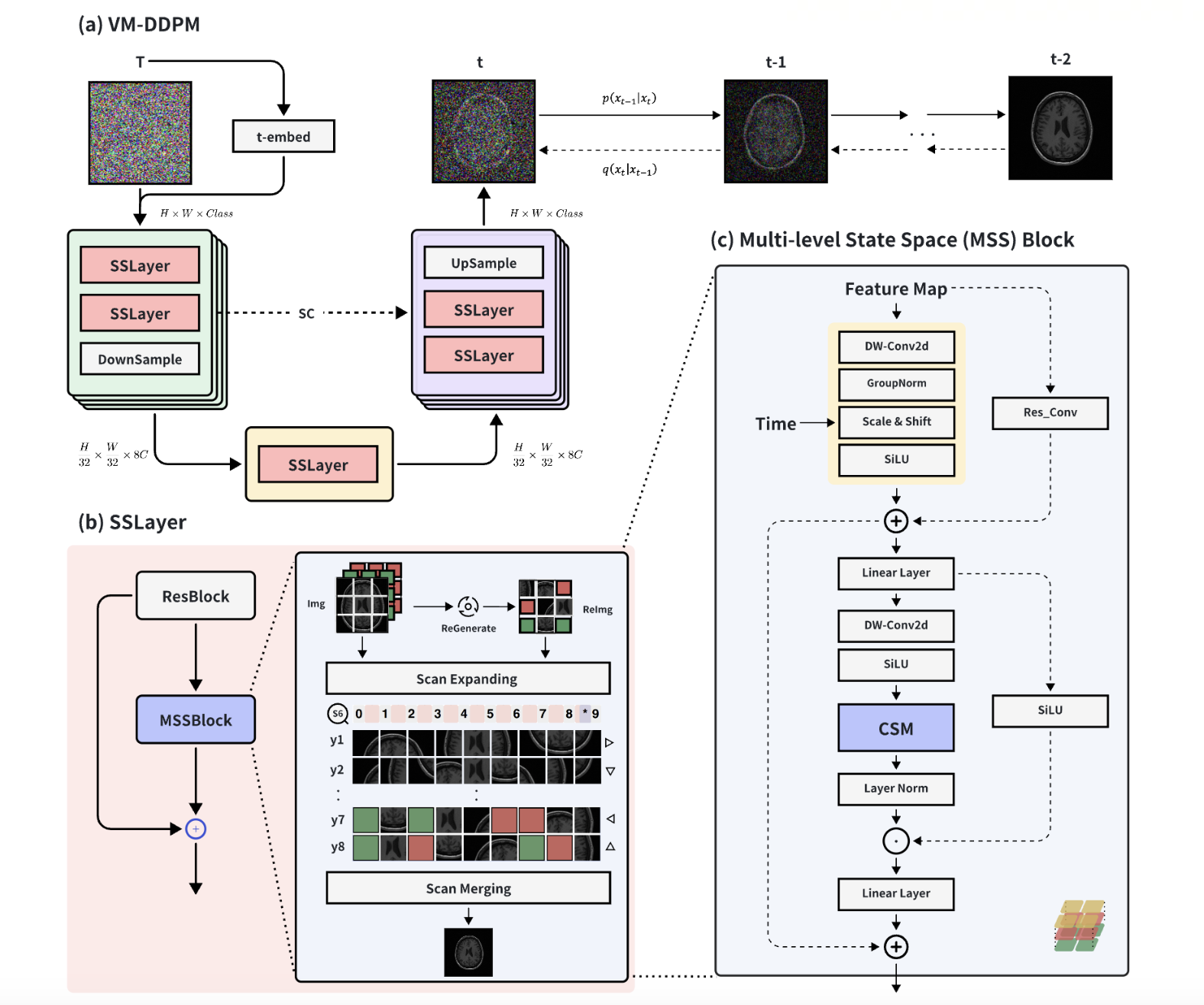
VM-DDPM: Vision Mamba Diffusion for Medical Image Synthesis
Zhihan Ju, Wanting Zhou
In the realm of smart healthcare, researchers enhance the scale and diversity of medical datasets through medical image synthesis. However, existing methods are limited by CNN local perception and Transformer quadratic complexity, making it difficult to balance structural texture consistency. To this end, we propose the Vision Mamba DDPM (VM-DDPM) based on State Space Model (SSM), fully combining CNN local perception and SSM global modeling capabilities, while maintaining linear computational complexity. Specifically, we designed a multi-level feature extraction module called Multi-level State Space Block (MSSBlock), and a basic unit of encoder-decoder structure called State Space Layer (SSLayer) for medical pathological images. Besides, we designed a simple, Plug-and-Play, zero-parameter Sequence Regeneration strategy for the Cross-Scan Module (CSM), which enabled the S6 module to fully perceive the spatial features of the 2D image and stimulate the generalization potential of the model. To our best knowledge, this is the first medical image synthesis model based on the SSM-CNN hybrid architecture. Our experimental evaluation on three datasets of different scales, i.e., ACDC, BraTS2018, and ChestXRay, as well as qualitative evaluation by radiologists, demonstrate that VM-DDPM achieves state-of-the-art performance.
Read more5/10/2024

0
LaMamba-Diff: Linear-Time High-Fidelity Diffusion Models Based on Local Attention and Mamba
Yunxiang Fu, Chaoqi Chen, Yizhou Yu
Recent Transformer-based diffusion models have shown remarkable performance, largely attributed to the ability of the self-attention mechanism to accurately capture both global and local contexts by computing all-pair interactions among input tokens. However, their quadratic complexity poses significant computational challenges for long-sequence inputs. Conversely, a recent state space model called Mamba offers linear complexity by compressing a filtered global context into a hidden state. Despite its efficiency, compression inevitably leads to information loss of fine-grained local dependencies among tokens, which are crucial for effective visual generative modeling. Motivated by these observations, we introduce Local Attentional Mamba (LaMamba) blocks that combine the strengths of self-attention and Mamba, capturing both global contexts and local details with linear complexity. Leveraging the efficient U-Net architecture, our model exhibits exceptional scalability and surpasses the performance of DiT across various model scales on ImageNet at 256x256 resolution, all while utilizing substantially fewer GFLOPs and a comparable number of parameters. Compared to state-of-the-art diffusion models on ImageNet 256x256 and 512x512, our largest model presents notable advantages, such as a reduction of up to 62% GFLOPs compared to DiT-XL/2, while achieving superior performance with comparable or fewer parameters. Our code is available at https://github.com/yunxiangfu2001/LaMamba-Diff.
Read more9/20/2024