Discffusion: Discriminative Diffusion Models as Few-shot Vision and Language Learners
2305.10722
0
0
👀
Abstract
Diffusion models, such as Stable Diffusion, have shown incredible performance on text-to-image generation. Since text-to-image generation often requires models to generate visual concepts with fine-grained details and attributes specified in text prompts, can we leverage the powerful representations learned by pre-trained diffusion models for discriminative tasks such as image-text matching? To answer this question, we propose a novel approach, Discriminative Stable Diffusion (DSD), which turns pre-trained text-to-image diffusion models into few-shot discriminative learners. Our approach mainly uses the cross-attention score of a Stable Diffusion model to capture the mutual influence between visual and textual information and fine-tune the model via efficient attention-based prompt learning to perform image-text matching. By comparing DSD with state-of-the-art methods on several benchmark datasets, we demonstrate the potential of using pre-trained diffusion models for discriminative tasks with superior results on few-shot image-text matching.
Create account to get full access
Overview
- This paper explores using pre-trained diffusion models, like Stable Diffusion, for discriminative tasks such as image-text matching.
- The proposed approach, called Discriminative Stable Diffusion (DSD), fine-tunes the pre-trained diffusion model using efficient attention-based prompt learning to perform image-text matching.
- The key idea is to leverage the powerful representations learned by diffusion models for tasks beyond just text-to-image generation.
Plain English Explanation
Diffusion models have shown incredible abilities in generating images from text descriptions. These models learn to understand the relationship between visual concepts and their textual representations. [Discriminative Stable Diffusion (DSD)] aims to take advantage of this learned understanding and apply it to the task of matching images and their corresponding text descriptions.
The core idea is to use the cross-attention scores within the diffusion model to capture the mutual influence between visual and textual information. By fine-tuning the model through efficient attention-based prompt learning, the researchers were able to adapt the pre-trained diffusion model to excel at the image-text matching task, even with limited training data.
This approach is valuable because it allows us to reuse the powerful visual and language understanding capabilities of diffusion models, like Stable Diffusion, and apply them to new problems beyond just image generation. This could lead to more efficient and effective models for tasks like image-text retrieval, visual question answering, and other discriminative tasks where understanding the relationship between images and text is crucial.
Technical Explanation
The key technical contribution of this paper is the Discriminative Stable Diffusion (DSD) approach, which repurposes a pre-trained text-to-image diffusion model like Stable Diffusion for the task of image-text matching.
The main steps are:
- Leveraging Cross-Attention: The researchers use the cross-attention scores within the diffusion model to capture the mutual influence between visual and textual information. This allows the model to learn the correspondence between image features and their textual descriptions.
- Attention-based Prompt Learning: The pre-trained diffusion model is fine-tuned using efficient attention-based prompt learning. This involves learning a set of prompts that can be used to adapt the model's behavior for the image-text matching task, without requiring significant changes to the model architecture.
By using this approach, the researchers were able to achieve superior performance on several benchmark datasets for few-shot image-text matching, compared to state-of-the-art methods. This demonstrates the potential of repurposing powerful diffusion models for a wide range of discriminative tasks, beyond just text-to-image generation.
Critical Analysis
The paper presents a compelling approach to leveraging pre-trained diffusion models for discriminative tasks. However, a few potential limitations and areas for further research are worth considering:
-
Generalization Capabilities: While the paper showcases strong performance on the evaluated benchmark datasets, it's unclear how well the DSD approach would generalize to more diverse or challenging image-text matching scenarios. Further testing on a broader range of datasets would be valuable.
-
Computational Efficiency: The paper does not provide a detailed analysis of the computational cost and training time required for the DSD approach. As the fine-tuning process involves attention-based prompt learning, the efficiency of this approach compared to other fine-tuning strategies could be an important consideration.
-
Interpretability and Transparency: The paper does not delve into the interpretability of the DSD model's decision-making process. Providing more insights into how the model arrives at its image-text matching decisions could help build trust and understanding in real-world applications.
-
Comparison to End-to-End Approaches: The paper focuses on repurposing pre-trained diffusion models, but it would be interesting to compare the DSD approach to end-to-end models trained specifically for image-text matching tasks, such as CLIP or ALIGN.
Overall, the Discriminative Stable Diffusion (DSD) approach presents a promising direction for leveraging the capabilities of diffusion models beyond just text-to-image generation. Further research and exploration in this area could lead to more efficient and effective models for a wide range of discriminative tasks involving images and text.
Conclusion
This paper introduces Discriminative Stable Diffusion (DSD), a novel approach that repurposes pre-trained text-to-image diffusion models, such as Stable Diffusion, for the task of image-text matching. By leveraging the cross-attention scores within the diffusion model and fine-tuning the model through efficient attention-based prompt learning, the researchers were able to achieve superior performance on several benchmark datasets for few-shot image-text matching.
The key insight of this work is the ability to harness the powerful visual and language understanding capabilities of diffusion models and apply them to discriminative tasks beyond just image generation. This opens up exciting possibilities for more efficient and effective models in areas like image-text retrieval, visual question answering, and other applications where understanding the relationship between images and text is crucial.
As diffusion models continue to advance and demonstrate their versatility, approaches like DSD could become increasingly valuable in the field of artificial intelligence, enabling more seamless integration of visual and textual understanding for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Pre-trained Text-to-Image Diffusion Models Are Versatile Representation Learners for Control
Gunshi Gupta, Karmesh Yadav, Yarin Gal, Dhruv Batra, Zsolt Kira, Cong Lu, Tim G. J. Rudner
0
0
Embodied AI agents require a fine-grained understanding of the physical world mediated through visual and language inputs. Such capabilities are difficult to learn solely from task-specific data. This has led to the emergence of pre-trained vision-language models as a tool for transferring representations learned from internet-scale data to downstream tasks and new domains. However, commonly used contrastively trained representations such as in CLIP have been shown to fail at enabling embodied agents to gain a sufficiently fine-grained scene understanding -- a capability vital for control. To address this shortcoming, we consider representations from pre-trained text-to-image diffusion models, which are explicitly optimized to generate images from text prompts and as such, contain text-conditioned representations that reflect highly fine-grained visuo-spatial information. Using pre-trained text-to-image diffusion models, we construct Stable Control Representations which allow learning downstream control policies that generalize to complex, open-ended environments. We show that policies learned using Stable Control Representations are competitive with state-of-the-art representation learning approaches across a broad range of simulated control settings, encompassing challenging manipulation and navigation tasks. Most notably, we show that Stable Control Representations enable learning policies that exhibit state-of-the-art performance on OVMM, a difficult open-vocabulary navigation benchmark.
5/10/2024

Plug-and-Play Diffusion Distillation
Yi-Ting Hsiao, Siavash Khodadadeh, Kevin Duarte, Wei-An Lin, Hui Qu, Mingi Kwon, Ratheesh Kalarot
0
0
Diffusion models have shown tremendous results in image generation. However, due to the iterative nature of the diffusion process and its reliance on classifier-free guidance, inference times are slow. In this paper, we propose a new distillation approach for guided diffusion models in which an external lightweight guide model is trained while the original text-to-image model remains frozen. We show that our method reduces the inference computation of classifier-free guided latent-space diffusion models by almost half, and only requires 1% trainable parameters of the base model. Furthermore, once trained, our guide model can be applied to various fine-tuned, domain-specific versions of the base diffusion model without the need for additional training: this plug-and-play functionality drastically improves inference computation while maintaining the visual fidelity of generated images. Empirically, we show that our approach is able to produce visually appealing results and achieve a comparable FID score to the teacher with as few as 8 to 16 steps.
6/17/2024
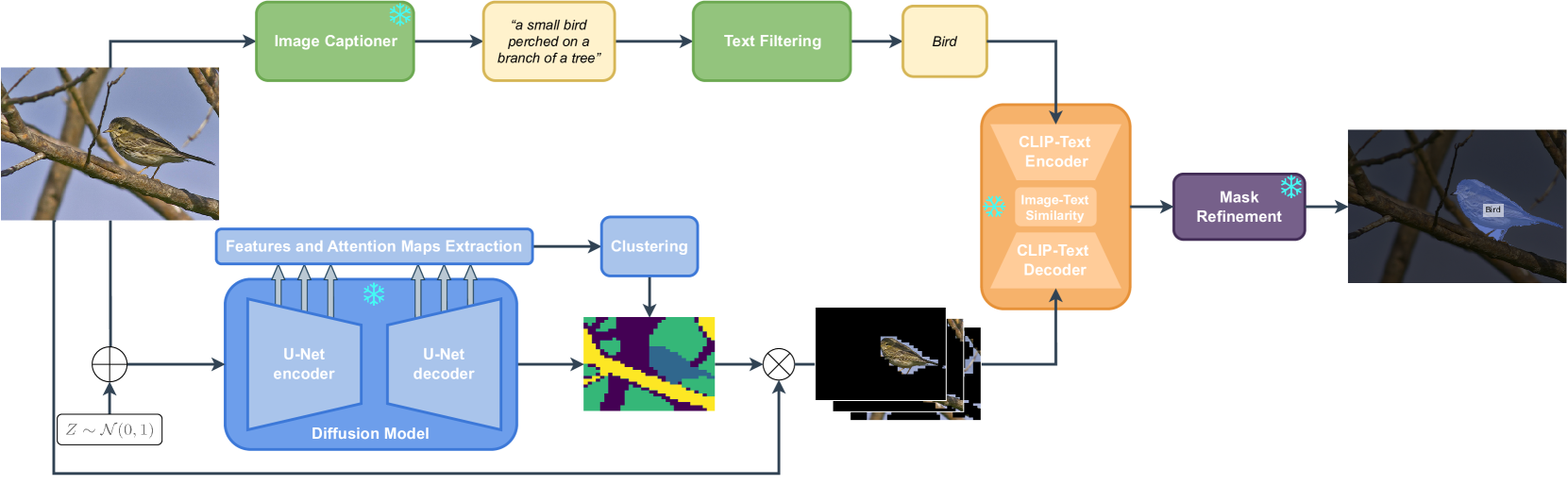
FreeSeg-Diff: Training-Free Open-Vocabulary Segmentation with Diffusion Models
Barbara Toniella Corradini, Mustafa Shukor, Paul Couairon, Guillaume Couairon, Franco Scarselli, Matthieu Cord
0
0
Foundation models have exhibited unprecedented capabilities in tackling many domains and tasks. Models such as CLIP are currently widely used to bridge cross-modal representations, and text-to-image diffusion models are arguably the leading models in terms of realistic image generation. Image generative models are trained on massive datasets that provide them with powerful internal spatial representations. In this work, we explore the potential benefits of such representations, beyond image generation, in particular, for dense visual prediction tasks. We focus on the task of image segmentation, which is traditionally solved by training models on closed-vocabulary datasets, with pixel-level annotations. To avoid the annotation cost or training large diffusion models, we constraint our setup to be zero-shot and training-free. In a nutshell, our pipeline leverages different and relatively small-sized, open-source foundation models for zero-shot open-vocabulary segmentation. The pipeline is as follows: the image is passed to both a captioner model (i.e. BLIP) and a diffusion model (i.e., Stable Diffusion Model) to generate a text description and visual representation, respectively. The features are clustered and binarized to obtain class agnostic masks for each object. These masks are then mapped to a textual class, using the CLIP model to support open-vocabulary. Finally, we add a refinement step that allows to obtain a more precise segmentation mask. Our approach (dubbed FreeSeg-Diff), which does not rely on any training, outperforms many training-based approaches on both Pascal VOC and COCO datasets. In addition, we show very competitive results compared to the recent weakly-supervised segmentation approaches. We provide comprehensive experiments showing the superiority of diffusion model features compared to other pretrained models. Project page: https://bcorrad.github.io/freesegdiff/
4/1/2024

MS-Diffusion: Multi-subject Zero-shot Image Personalization with Layout Guidance
X. Wang, Siming Fu, Qihan Huang, Wanggui He, Hao Jiang
0
0
Recent advancements in text-to-image generation models have dramatically enhanced the generation of photorealistic images from textual prompts, leading to an increased interest in personalized text-to-image applications, particularly in multi-subject scenarios. However, these advances are hindered by two main challenges: firstly, the need to accurately maintain the details of each referenced subject in accordance with the textual descriptions; and secondly, the difficulty in achieving a cohesive representation of multiple subjects in a single image without introducing inconsistencies. To address these concerns, our research introduces the MS-Diffusion framework for layout-guided zero-shot image personalization with multi-subjects. This innovative approach integrates grounding tokens with the feature resampler to maintain detail fidelity among subjects. With the layout guidance, MS-Diffusion further improves the cross-attention to adapt to the multi-subject inputs, ensuring that each subject condition acts on specific areas. The proposed multi-subject cross-attention orchestrates harmonious inter-subject compositions while preserving the control of texts. Comprehensive quantitative and qualitative experiments affirm that this method surpasses existing models in both image and text fidelity, promoting the development of personalized text-to-image generation.
6/12/2024