SwiftBrush: One-Step Text-to-Image Diffusion Model with Variational Score Distillation
2312.05239
0
0
Abstract
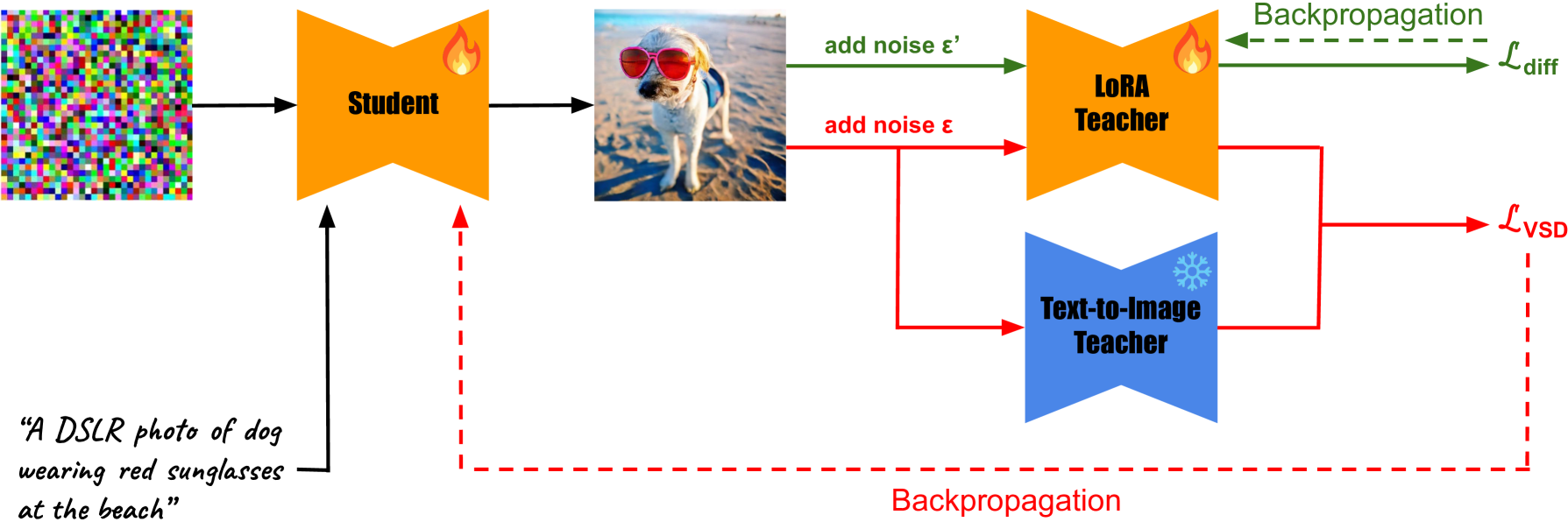
Despite their ability to generate high-resolution and diverse images from text prompts, text-to-image diffusion models often suffer from slow iterative sampling processes. Model distillation is one of the most effective directions to accelerate these models. However, previous distillation methods fail to retain the generation quality while requiring a significant amount of images for training, either from real data or synthetically generated by the teacher model. In response to this limitation, we present a novel image-free distillation scheme named $textbf{SwiftBrush}$. Drawing inspiration from text-to-3D synthesis, in which a 3D neural radiance field that aligns with the input prompt can be obtained from a 2D text-to-image diffusion prior via a specialized loss without the use of any 3D data ground-truth, our approach re-purposes that same loss for distilling a pretrained multi-step text-to-image model to a student network that can generate high-fidelity images with just a single inference step. In spite of its simplicity, our model stands as one of the first one-step text-to-image generators that can produce images of comparable quality to Stable Diffusion without reliance on any training image data. Remarkably, SwiftBrush achieves an FID score of $textbf{16.67}$ and a CLIP score of $textbf{0.29}$ on the COCO-30K benchmark, achieving competitive results or even substantially surpassing existing state-of-the-art distillation techniques.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents "SwiftBrush", a one-step text-to-image diffusion model that uses a novel technique called "Variational Score Distillation" to generate high-quality images from text descriptions.
- The model aims to address the limitations of existing text-to-image generation models, which often require multiple steps or complex architectures.
- SwiftBrush is designed to be efficient and easy to use, making it a promising approach for applications that require fast and accurate text-to-image generation.
Plain English Explanation
The paper introduces a new text-to-image generation model called "SwiftBrush" that can create images from text descriptions in a single step. This is different from many existing models, which require multiple steps or have complex architectures.
The key innovation in SwiftBrush is a technique called "Variational Score Distillation". This allows the model to generate high-quality images while being more efficient and easier to use than other approaches. The authors designed SwiftBrush to be fast and accurate, making it potentially useful for applications that need quick and reliable text-to-image generation, such as image editing or content creation.
Technical Explanation
The core of the SwiftBrush model is a diffusion-based text-to-image generation framework that uses a novel "Variational Score Distillation" technique. This approach aims to improve the efficiency and performance of the model compared to previous diffusion-based text-to-image models.
The key elements of the SwiftBrush architecture include:
- A text encoder that maps input text to a latent representation
- A diffusion model that generates images from the text latent representation
- The "Variational Score Distillation" module, which helps the model generate high-quality images in a single step
The authors evaluate SwiftBrush on several benchmark datasets and show that it outperforms state-of-the-art text-to-image generation models in terms of both image quality and generation speed. They also provide detailed ablation studies to understand the contributions of the various components of the model.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated text-to-image generation model. The authors have addressed key limitations of existing approaches by introducing the novel "Variational Score Distillation" technique, which appears to be a promising direction for improving the efficiency and performance of diffusion-based text-to-image models.
However, the paper does not discuss potential limitations or caveats of the SwiftBrush model. For example, it would be helpful to understand the model's performance on more diverse or challenging datasets, or how it might handle edge cases or inputs that are outside the training distribution.
Additionally, the paper does not explore the broader implications or potential societal impacts of the technology, such as issues related to content generation, bias, or ethical considerations. Further research and discussion in these areas would be valuable.
Conclusion
The SwiftBrush model presented in this paper represents an important advancement in the field of text-to-image generation. By introducing the "Variational Score Distillation" technique, the authors have demonstrated a way to improve the efficiency and performance of diffusion-based models, making them more practical for real-world applications.
The results of the study are promising, and the SwiftBrush model has the potential to enable new and more accessible applications that rely on high-quality, fast text-to-image generation. As the field of generative AI continues to evolve, research like this will be crucial in developing more robust and reliable models that can be responsibly deployed to benefit society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
Discffusion: Discriminative Diffusion Models as Few-shot Vision and Language Learners
Xuehai He, Weixi Feng, Tsu-Jui Fu, Varun Jampani, Arjun Akula, Pradyumna Narayana, Sugato Basu, William Yang Wang, Xin Eric Wang
0
0
Diffusion models, such as Stable Diffusion, have shown incredible performance on text-to-image generation. Since text-to-image generation often requires models to generate visual concepts with fine-grained details and attributes specified in text prompts, can we leverage the powerful representations learned by pre-trained diffusion models for discriminative tasks such as image-text matching? To answer this question, we propose a novel approach, Discriminative Stable Diffusion (DSD), which turns pre-trained text-to-image diffusion models into few-shot discriminative learners. Our approach mainly uses the cross-attention score of a Stable Diffusion model to capture the mutual influence between visual and textual information and fine-tune the model via efficient attention-based prompt learning to perform image-text matching. By comparing DSD with state-of-the-art methods on several benchmark datasets, we demonstrate the potential of using pre-trained diffusion models for discriminative tasks with superior results on few-shot image-text matching.
4/26/2024

EdgeFusion: On-Device Text-to-Image Generation
Thibault Castells, Hyoung-Kyu Song, Tairen Piao, Shinkook Choi, Bo-Kyeong Kim, Hanyoung Yim, Changgwun Lee, Jae Gon Kim, Tae-Ho Kim
0
0
The intensive computational burden of Stable Diffusion (SD) for text-to-image generation poses a significant hurdle for its practical application. To tackle this challenge, recent research focuses on methods to reduce sampling steps, such as Latent Consistency Model (LCM), and on employing architectural optimizations, including pruning and knowledge distillation. Diverging from existing approaches, we uniquely start with a compact SD variant, BK-SDM. We observe that directly applying LCM to BK-SDM with commonly used crawled datasets yields unsatisfactory results. It leads us to develop two strategies: (1) leveraging high-quality image-text pairs from leading generative models and (2) designing an advanced distillation process tailored for LCM. Through our thorough exploration of quantization, profiling, and on-device deployment, we achieve rapid generation of photo-realistic, text-aligned images in just two steps, with latency under one second on resource-limited edge devices.
4/19/2024

Your Student is Better Than Expected: Adaptive Teacher-Student Collaboration for Text-Conditional Diffusion Models
Nikita Starodubcev, Artem Fedorov, Artem Babenko, Dmitry Baranchuk
0
0
Knowledge distillation methods have recently shown to be a promising direction to speedup the synthesis of large-scale diffusion models by requiring only a few inference steps. While several powerful distillation methods were recently proposed, the overall quality of student samples is typically lower compared to the teacher ones, which hinders their practical usage. In this work, we investigate the relative quality of samples produced by the teacher text-to-image diffusion model and its distilled student version. As our main empirical finding, we discover that a noticeable portion of student samples exhibit superior fidelity compared to the teacher ones, despite the approximate nature of the student. Based on this finding, we propose an adaptive collaboration between student and teacher diffusion models for effective text-to-image synthesis. Specifically, the distilled model produces the initial sample, and then an oracle decides whether it needs further improvements with a slow teacher model. Extensive experiments demonstrate that the designed pipeline surpasses state-of-the-art text-to-image alternatives for various inference budgets in terms of human preference. Furthermore, the proposed approach can be naturally used in popular applications such as text-guided image editing and controllable generation.
4/8/2024
Diffusion Time-step Curriculum for One Image to 3D Generation
Xuanyu Yi, Zike Wu, Qingshan Xu, Pan Zhou, Joo-Hwee Lim, Hanwang Zhang
0
0
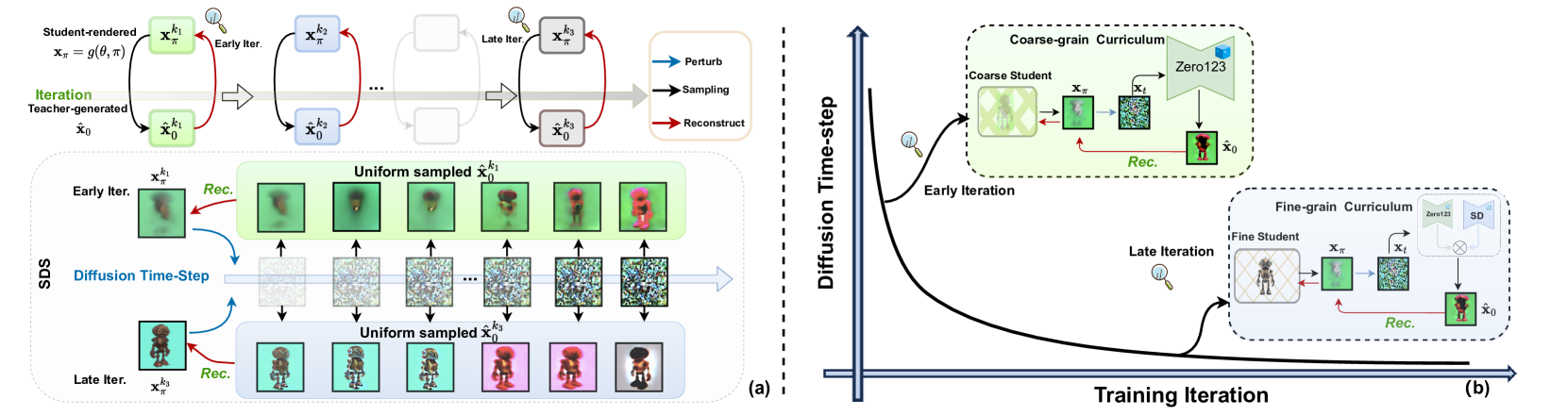
Score distillation sampling~(SDS) has been widely adopted to overcome the absence of unseen views in reconstructing 3D objects from a textbf{single} image. It leverages pre-trained 2D diffusion models as teacher to guide the reconstruction of student 3D models. Despite their remarkable success, SDS-based methods often encounter geometric artifacts and texture saturation. We find out the crux is the overlooked indiscriminate treatment of diffusion time-steps during optimization: it unreasonably treats the student-teacher knowledge distillation to be equal at all time-steps and thus entangles coarse-grained and fine-grained modeling. Therefore, we propose the Diffusion Time-step Curriculum one-image-to-3D pipeline (DTC123), which involves both the teacher and student models collaborating with the time-step curriculum in a coarse-to-fine manner. Extensive experiments on NeRF4, RealFusion15, GSO and Level50 benchmark demonstrate that DTC123 can produce multi-view consistent, high-quality, and diverse 3D assets. Codes and more generation demos will be released in https://github.com/yxymessi/DTC123.
5/6/2024