Discounted Pseudocosts in MILP

0
🎯
Sign in to get full access
Overview
- This paper explores the use of discounted pseudocosts in mixed-integer linear programming (MILP) optimization problems.
- Pseudocosts are estimates of the objective function value for variables that are temporarily fixed to integer values, which can help guide the branch-and-bound algorithm used to solve MILP problems.
- The authors propose a new method for computing discounted pseudocosts that aims to improve the performance of MILP solvers.
Plain English Explanation
Mixed-integer linear programming (MILP) is a powerful optimization technique used to solve complex problems involving both continuous and discrete variables. When solving a MILP problem, a common approach is to use a branch-and-bound algorithm, which explores different combinations of integer variable values.
To guide this exploration, MILP solvers often use
This paper proposes a new method for computing
The key idea is that the further a variable is from its optimal integer value, the less informative its pseudocost will be. By discounting these less reliable pseudocosts, the method aims to focus the branch-and-bound algorithm on the more promising parts of the search space.
Technical Explanation
The paper first provides an overview of the MILP optimization problem and the role of pseudocosts in branch-and-bound algorithms. The authors then introduce their
- When a variable is branched on, the algorithm computes a pseudocost estimate for each of the two child nodes.
- These pseudocost estimates are then discounted based on the distance between the current fractional value of the variable and its optimal integer value.
- The discounted pseudocosts are used to guide the branch-and-bound algorithm, prioritizing branches with more reliable pseudocost estimates.
The authors evaluate their method on a set of standard MILP benchmark problems and compare its performance to that of a traditional MILP solver. They show that the discounted pseudocost approach can lead to significant improvements in solution times, particularly for problems with a large number of integer variables.
Critical Analysis
The paper presents a novel and well-motivated approach for improving the performance of MILP solvers. The use of discounted pseudocosts is a logical extension of the existing pseudocost concept and seems to offer tangible benefits.
One potential limitation is that the method relies on having a good estimate of the optimal integer value for each variable. In practice, this information may not always be readily available, which could limit the effectiveness of the approach.
Additionally, the paper only evaluates the method on a set of standard benchmark problems. It would be interesting to see how it performs on more diverse and challenging MILP instances, particularly those arising from real-world applications.
Overall, the discounted pseudocost method appears to be a promising technique that could help advance the state of the art in MILP optimization. Further research and validation on a wider range of problems would be valuable to fully assess the method's capabilities and limitations.
Conclusion
This paper presents a novel approach for computing discounted pseudocosts in the context of mixed-integer linear programming (MILP) optimization. By applying a discount factor to pseudocost estimates based on the distance from the optimal integer value, the method aims to focus the branch-and-bound algorithm on the most promising parts of the search space.
The authors demonstrate that this discounted pseudocost approach can lead to significant improvements in solution times for standard MILP benchmark problems, particularly for instances with a large number of integer variables. While the method shows promise, further research is needed to evaluate its performance on a wider range of MILP problems and real-world applications.
Overall, the discounted pseudocost technique represents an interesting contribution to the field of MILP optimization, with the potential to enhance the efficiency and effectiveness of MILP solvers in a variety of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎯
0
Discounted Pseudocosts in MILP
Krunal Kishor Patel
In this article, we introduce the concept of discounted pseudocosts, inspired by discounted total reward in reinforcement learning, and explore their application in mixed-integer linear programming (MILP). Traditional pseudocosts estimate changes in the objective function due to variable bound changes during the branch-and-bound process. By integrating reinforcement learning concepts, we propose a novel approach incorporating a forward-looking perspective into pseudocost estimation. We present the motivation behind discounted pseudocosts and discuss how they represent the anticipated reward for branching after one level of exploration in the MILP problem space. Initial experiments on MIPLIB 2017 benchmark instances demonstrate the potential of discounted pseudocosts to enhance branching strategies and accelerate the solution process for challenging MILP problems.
Read more7/10/2024
0
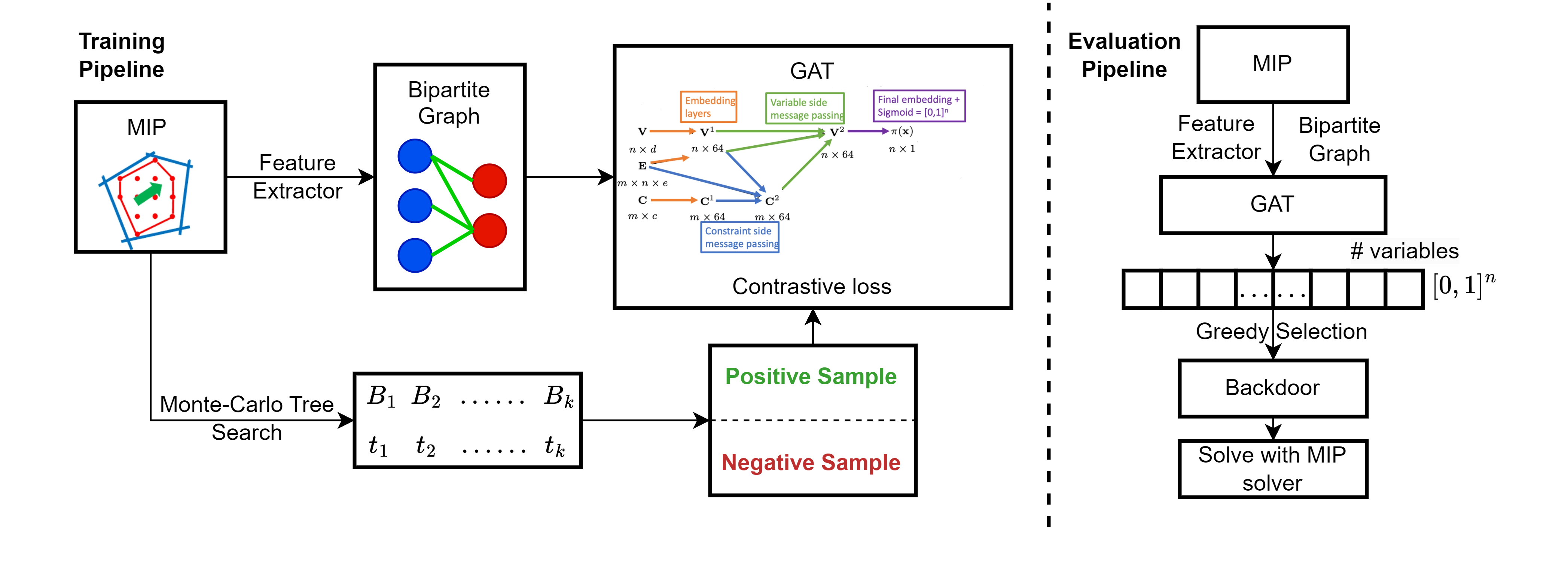
Learning Backdoors for Mixed Integer Linear Programs with Contrastive Learning
Junyang Cai, Taoan Huang, Bistra Dilkina
Many real-world problems can be efficiently modeled as Mixed Integer Linear Programs (MILPs) and solved with the Branch-and-Bound method. Prior work has shown the existence of MILP backdoors, small sets of variables such that prioritizing branching on them when possible leads to faster running times. However, finding high-quality backdoors that improve running times remains an open question. Previous work learns to estimate the relative solver speed of randomly sampled backdoors through ranking and then decide whether to use the highest-ranked backdoor candidate. In this paper, we utilize the Monte-Carlo tree search method to collect backdoors for training, rather than relying on random sampling, and adapt a contrastive learning framework to train a Graph Attention Network model to predict backdoors. Our method, evaluated on several common MILP problem domains, demonstrates performance improvements over both Gurobi and previous models.
Read more8/2/2024

0
On shallow planning under partial observability
Randy Lefebvre, Audrey Durand
Formulating a real-world problem under the Reinforcement Learning framework involves non-trivial design choices, such as selecting a discount factor for the learning objective (discounted cumulative rewards), which articulates the planning horizon of the agent. This work investigates the impact of the discount factor on the biasvariance trade-off given structural parameters of the underlying Markov Decision Process. Our results support the idea that a shorter planning horizon might be beneficial, especially under partial observability.
Read more7/23/2024
0
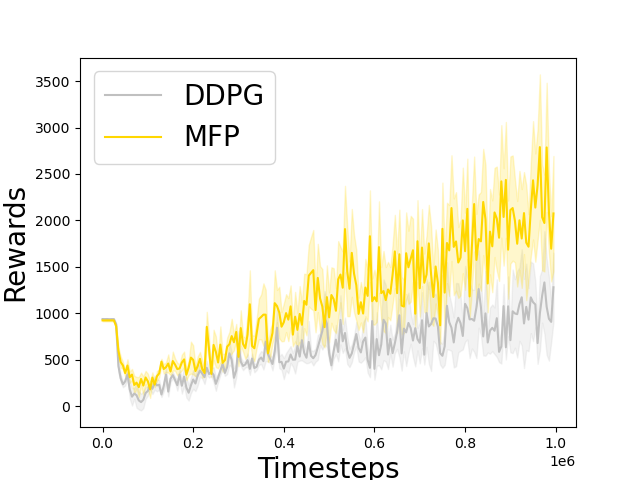
Markov flow policy -- deep MC
Nitsan Soffair, Gilad Katz
Discounted algorithms often encounter evaluation errors due to their reliance on short-term estimations, which can impede their efficacy in addressing simple, short-term tasks and impose undesired temporal discounts ((gamma)). Interestingly, these algorithms are often tested without applying a discount, a phenomenon we refer as the textit{train-test bias}. In response to these challenges, we propose the Markov Flow Policy, which utilizes a non-negative neural network flow to enable comprehensive forward-view predictions. Through integration into the TD7 codebase and evaluation using the MuJoCo benchmark, we observe significant performance improvements, positioning MFP as a straightforward, practical, and easily implementable solution within the domain of average rewards algorithms.
Read more9/2/2024