Discovery and Expansion of New Domains within Diffusion Models
2310.09213
0
0
📉
Abstract
In this work, we study the generalization properties of diffusion models in a few-shot setup, introduce a novel tuning-free paradigm to synthesize the target out-of-domain (OOD) data, and demonstrate its advantages compared to existing methods in data-sparse scenarios with large domain gaps. Specifically, given a pre-trained model and a small set of images that are OOD relative to the model's training distribution, we explore whether the frozen model is able to generalize to this new domain. We begin by revealing that Denoising Diffusion Probabilistic Models (DDPMs) trained on single-domain images are already equipped with sufficient representation abilities to reconstruct arbitrary images from the inverted latent encoding following bi-directional deterministic diffusion and denoising trajectories. We then demonstrate through both theoretical and empirical perspectives that the OOD images establish Gaussian priors in latent spaces of the given model, and the inverted latent modes are separable from their initial training domain. We then introduce our novel tuning-free paradigm to synthesize new images of the target unseen domain by discovering qualified OOD latent encodings in the inverted noisy spaces. This is fundamentally different from the current paradigm that seeks to modify the denoising trajectory to achieve the same goal by tuning the model parameters. Extensive cross-model and domain experiments show that our proposed method can expand the latent space and generate unseen images via frozen DDPMs without impairing the quality of generation of their original domain. We also showcase a practical application of our proposed heuristic approach in dramatically different domains using astrophysical data, revealing the great potential of such a generalization paradigm in data spare fields such as scientific explorations.
Create account to get full access
Overview
- This paper explores the generalization capabilities of diffusion models in a few-shot learning setup.
- It introduces a novel tuning-free paradigm to synthesize target out-of-domain (OOD) data without modifying the pre-trained model.
- The proposed approach demonstrates advantages over existing methods in data-sparse scenarios with large domain gaps.
Plain English Explanation
In this work, the researchers investigate whether pre-trained diffusion models can be used to generate images from new domains that are different from their original training data. Typically, when you want to use a machine learning model to generate images in a new domain, you need to fine-tune or modify the model parameters to adapt it to the new data. However, the researchers found a way to generate new images without having to change the model itself.
The key insight is that the latent space (the internal representation) of the pre-trained diffusion model already contains enough information to reconstruct images from different domains. By inverting the diffusion process and discovering qualified latent encodings in the noisy space, the researchers were able to generate new images without modifying the model. This is a significant departure from the standard approach of tuning the model parameters to achieve the same goal, as outlined in papers like ODGEN and Non-Stationary Domain Generalization.
The researchers demonstrate the effectiveness of their tuning-free paradigm through extensive experiments across various models and domains, including a practical application in the field of astrophysics. This suggests that their approach has great potential for enabling data-sparse generalization in scientific explorations and other domains with limited available data.
Technical Explanation
The researchers begin by revealing that Denoising Diffusion Probabilistic Models (DDPMs) trained on single-domain images already possess sufficient representation abilities to reconstruct arbitrary images from the inverted latent encoding. They then demonstrate, both theoretically and empirically, that the OOD images establish Gaussian priors in the latent spaces of the given model, and the inverted latent modes are separable from their initial training domain.
Building on these insights, the researchers introduce their novel tuning-free paradigm to synthesize new images of the target unseen domain. This approach involves discovering qualified OOD latent encodings in the inverted noisy spaces, rather than modifying the denoising trajectory as in the current paradigm.
Through extensive cross-model and domain experiments, the researchers show that their proposed method can expand the latent space and generate unseen images via frozen DDPMs without impairing the quality of generation of their original domain. They also showcase a practical application of their heuristic approach in the domain of astrophysical data, demonstrating the potential of such a generalization paradigm in data-sparse fields.
Critical Analysis
The researchers acknowledge the limitations of their approach, noting that it relies on the assumption that the target OOD images establish Gaussian priors in the latent space of the pre-trained model. While this assumption holds true in their experiments, it may not always be the case, especially for more complex or diverse target domains.
Additionally, the paper does not explore the limits of the tuning-free paradigm in terms of the degree of domain shift or the number of OOD samples required for successful generation. Further research is needed to understand the boundaries of this approach and its applicability to a wider range of scenarios, including the potential integration with other out-of-distribution detection or domain generalization techniques.
Moreover, the researchers focus primarily on image generation, and it would be valuable to investigate whether their tuning-free paradigm could be extended to other modalities, such as text-to-image generation, to further demonstrate its versatility and broader applicability.
Conclusion
This paper presents a novel tuning-free approach to synthesizing out-of-domain data using pre-trained diffusion models. By leveraging the inherent representation abilities of these models and discovering qualified latent encodings in the inverted noisy spaces, the researchers demonstrate the potential for data-sparse generalization without the need for model modification.
The implications of this work extend beyond image generation, as the proposed paradigm could potentially be applied to other domains and tasks, potentially enabling more efficient and accessible data-driven exploration in various scientific and real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

GDA: Generalized Diffusion for Robust Test-time Adaptation
Yun-Yun Tsai, Fu-Chen Chen, Albert Y. C. Chen, Junfeng Yang, Che-Chun Su, Min Sun, Cheng-Hao Kuo
0
0
Machine learning models struggle with generalization when encountering out-of-distribution (OOD) samples with unexpected distribution shifts. For vision tasks, recent studies have shown that test-time adaptation employing diffusion models can achieve state-of-the-art accuracy improvements on OOD samples by generating new samples that align with the model's domain without the need to modify the model's weights. Unfortunately, those studies have primarily focused on pixel-level corruptions, thereby lacking the generalization to adapt to a broader range of OOD types. We introduce Generalized Diffusion Adaptation (GDA), a novel diffusion-based test-time adaptation method robust against diverse OOD types. Specifically, GDA iteratively guides the diffusion by applying a marginal entropy loss derived from the model, in conjunction with style and content preservation losses during the reverse sampling process. In other words, GDA considers the model's output behavior with the semantic information of the samples as a whole, which can reduce ambiguity in downstream tasks during the generation process. Evaluation across various popular model architectures and OOD benchmarks shows that GDA consistently outperforms prior work on diffusion-driven adaptation. Notably, it achieves the highest classification accuracy improvements, ranging from 4.4% to 5.02% on ImageNet-C and 2.5% to 7.4% on Rendition, Sketch, and Stylized benchmarks. This performance highlights GDA's generalization to a broader range of OOD benchmarks.
4/3/2024

Going beyond compositional generalization, DDPMs can produce zero-shot interpolation
Justin Deschenaux, Igor Krawczuk, Grigorios Chrysos, Volkan Cevher
0
0
Denoising Diffusion Probabilistic Models (DDPMs) exhibit remarkable capabilities in image generation, with studies suggesting that they can generalize by composing latent factors learned from the training data. In this work, we go further and study DDPMs trained on strictly separate subsets of the data distribution with large gaps on the support of the latent factors. We show that such a model can effectively generate images in the unexplored, intermediate regions of the distribution. For instance, when trained on clearly smiling and non-smiling faces, we demonstrate a sampling procedure which can generate slightly smiling faces without reference images (zero-shot interpolation). We replicate these findings for other attributes as well as other datasets. $href{https://github.com/jdeschena/ddpm-zero-shot-interpolation}{text{Our code is available on GitHub.}}$
5/30/2024
Exploiting Diffusion Prior for Out-of-Distribution Detection
Armando Zhu, Jiabei Liu, Keqin Li, Shuying Dai, Bo Hong, Peng Zhao, Changsong Wei
0
0
Out-of-distribution (OOD) detection is crucial for deploying robust machine learning models, especially in areas where security is critical. However, traditional OOD detection methods often fail to capture complex data distributions from large scale date. In this paper, we present a novel approach for OOD detection that leverages the generative ability of diffusion models and the powerful feature extraction capabilities of CLIP. By using these features as conditional inputs to a diffusion model, we can reconstruct the images after encoding them with CLIP. The difference between the original and reconstructed images is used as a signal for OOD identification. The practicality and scalability of our method is increased by the fact that it does not require class-specific labeled ID data, as is the case with many other methods. Extensive experiments on several benchmark datasets demonstrates the robustness and effectiveness of our method, which have significantly improved the detection accuracy.
6/18/2024
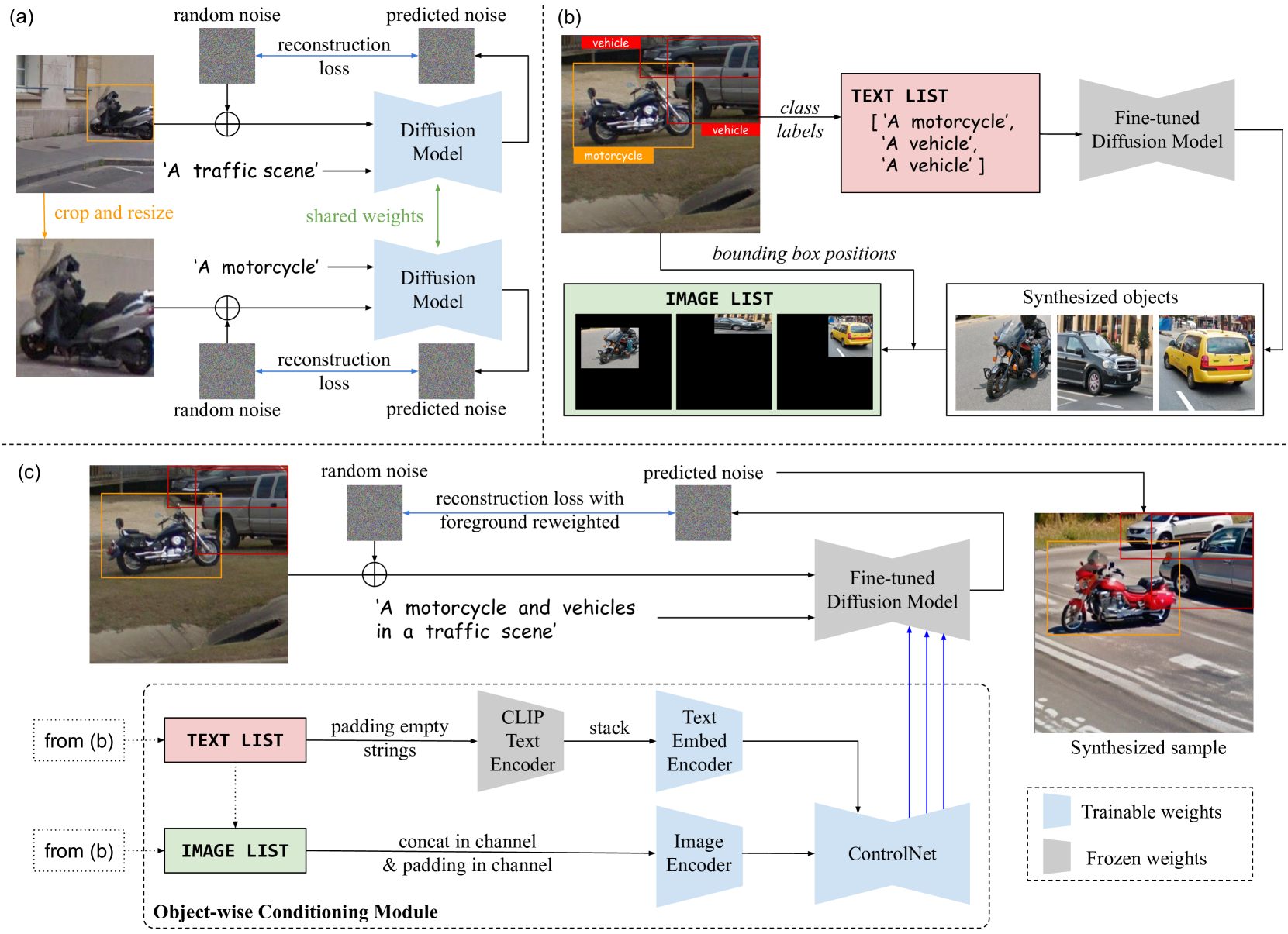
ODGEN: Domain-specific Object Detection Data Generation with Diffusion Models
Jingyuan Zhu, Shiyu Li, Yuxuan Liu, Ping Huang, Jiulong Shan, Huimin Ma, Jian Yuan
0
0
Modern diffusion-based image generative models have made significant progress and become promising to enrich training data for the object detection task. However, the generation quality and the controllability for complex scenes containing multi-class objects and dense objects with occlusions remain limited. This paper presents ODGEN, a novel method to generate high-quality images conditioned on bounding boxes, thereby facilitating data synthesis for object detection. Given a domain-specific object detection dataset, we first fine-tune a pre-trained diffusion model on both cropped foreground objects and entire images to fit target distributions. Then we propose to control the diffusion model using synthesized visual prompts with spatial constraints and object-wise textual descriptions. ODGEN exhibits robustness in handling complex scenes and specific domains. Further, we design a dataset synthesis pipeline to evaluate ODGEN on 7 domain-specific benchmarks to demonstrate its effectiveness. Adding training data generated by ODGEN improves up to 25.3% [email protected]:.95 with object detectors like YOLOv5 and YOLOv7, outperforming prior controllable generative methods. In addition, we design an evaluation protocol based on COCO-2014 to validate ODGEN in general domains and observe an advantage up to 5.6% in [email protected]:.95 against existing methods.
5/27/2024