ODGEN: Domain-specific Object Detection Data Generation with Diffusion Models

0
Sign in to get full access
Overview
- This paper presents a novel method called ODGEN (Object Detection Data Generation with Diffusion Models) for generating domain-specific object detection training data using diffusion models.
- ODGEN leverages diffusion models, a type of generative AI, to create realistic synthetic images of objects in specific domains, which can then be used to train object detection models.
- The key innovation is the ability to fine-tune the diffusion model on a small amount of domain-specific data to generate images tailored to a particular object detection task.
Plain English Explanation
ODGEN is a way to create fake images of objects that can be used to train AI models for object detection. Object detection is a task where an AI system tries to identify and locate specific objects in images or videos.
The key idea behind ODGEN is to use a type of AI called a diffusion model. Diffusion models are good at generating realistic-looking images by starting with random noise and gradually refining it. ODGEN takes a small set of example images from the specific domain you want to detect objects in, and uses that to fine-tune the diffusion model. This allows it to generate new synthetic images that look very similar to the real ones, but with the objects positioned in different ways.
Having this large set of synthetic training data can help object detection models learn better, especially when real-world data is scarce or expensive to collect. The paper shows that using ODGEN-generated images alongside real images can significantly improve the performance of object detectors on a variety of tasks, like finding cars in satellite imagery or detecting manufacturing defects.
The main benefit of ODGEN is its ability to efficiently create diverse, domain-specific training data that can boost the performance of object detection AI without requiring huge amounts of manual data collection and labeling. This makes it a useful tool for developing robust computer vision systems, especially in specialized domains.
Technical Explanation
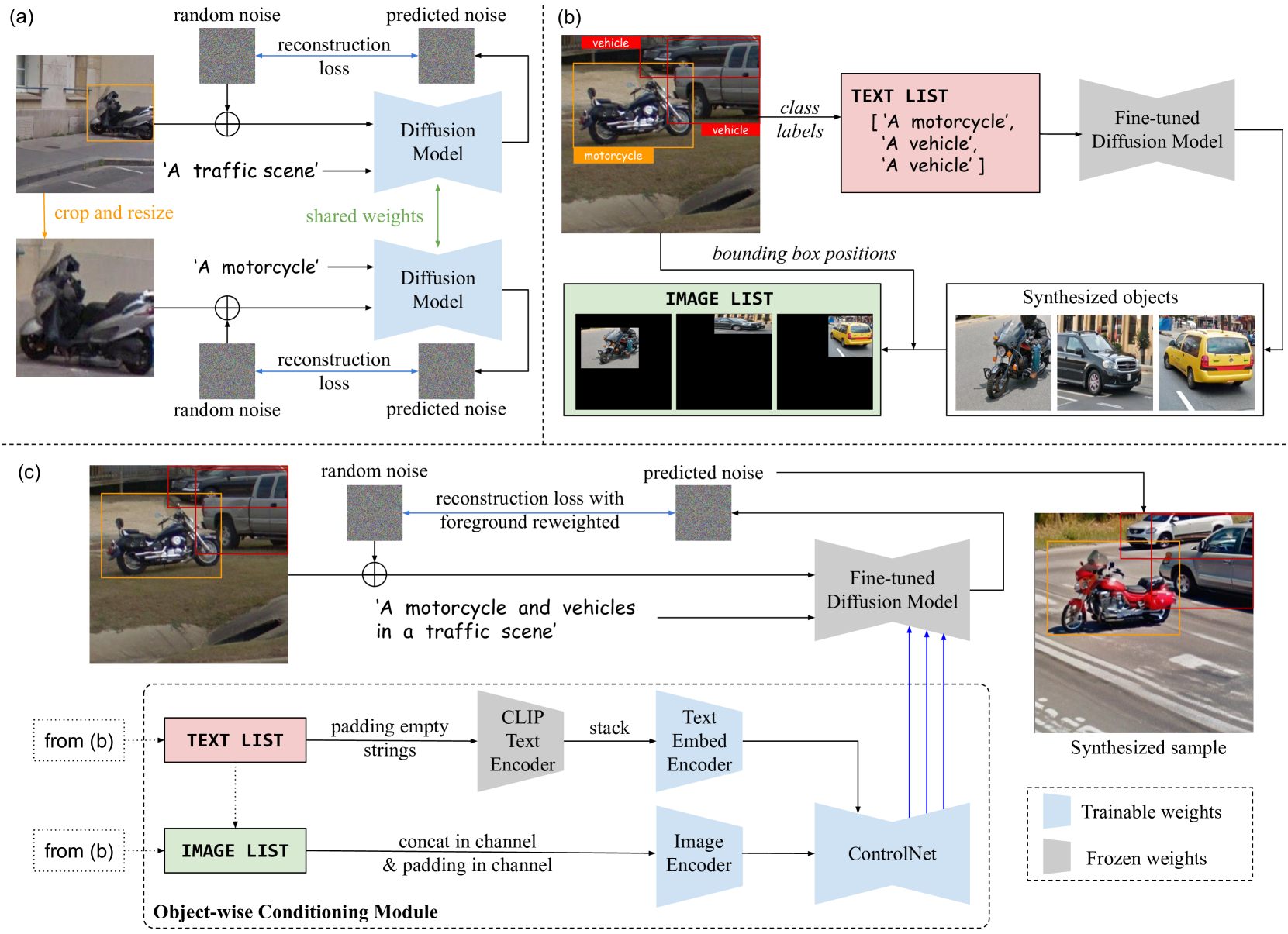
ODGEN works by fine-tuning a pre-trained diffusion model on a small dataset of domain-specific images. Diffusion models are a type of generative AI that can create realistic images by gradually transforming random noise into structured outputs.
The key innovation in ODGEN is using this fine-tuning process to adapt the diffusion model to a particular object detection task. The paper shows that by training on just a few hundred labeled images, ODGEN can generate a large and diverse set of synthetic images containing the target objects in various poses, backgrounds, and occlusions.
The authors evaluate ODGEN on several object detection benchmarks, including satellite imagery, manufacturing defect detection, and pedestrian detection. They demonstrate that combining the ODGEN-generated images with real training data can significantly improve the performance of state-of-the-art object detectors, surpassing prior data augmentation techniques like OverCome.
The paper also provides insights into the properties of the synthetic data produced by ODGEN, showing that it exhibits a close statistical match to the real data distribution while introducing beneficial diversity.
Critical Analysis
The ODGEN approach shows promising results, but the paper acknowledges some limitations. The fine-tuning process requires a small amount of labeled domain-specific data, which may not always be available, especially for emerging applications. The authors suggest exploring unsupervised techniques to further reduce the data requirements.
Additionally, while the generated images appear realistic, there may be subtle biases or artifacts introduced that could negatively impact the downstream object detection model. More rigorous testing of the generalization capabilities and robustness of ODGEN-trained detectors would be valuable.
Finally, the paper does not explore the potential for ODGEN to be used in a more interactive, human-in-the-loop setting, where users could provide feedback to refine the synthetic data generation process. Incorporating such interaction could further enhance the quality and usefulness of the generated training data.
Conclusion
Overall, the ODGEN framework represents an interesting and practical approach to leveraging diffusion models for data-efficient object detection model training. By generating domain-specific synthetic images, ODGEN can help overcome the data scarcity challenges that often hinder the development of robust computer vision systems, especially in specialized applications. As diffusion models continue to advance, techniques like ODGEN are likely to play an increasingly important role in accelerating the progress of AI-powered object detection and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ODGEN: Domain-specific Object Detection Data Generation with Diffusion Models
Jingyuan Zhu, Shiyu Li, Yuxuan Liu, Ping Huang, Jiulong Shan, Huimin Ma, Jian Yuan
Modern diffusion-based image generative models have made significant progress and become promising to enrich training data for the object detection task. However, the generation quality and the controllability for complex scenes containing multi-class objects and dense objects with occlusions remain limited. This paper presents ODGEN, a novel method to generate high-quality images conditioned on bounding boxes, thereby facilitating data synthesis for object detection. Given a domain-specific object detection dataset, we first fine-tune a pre-trained diffusion model on both cropped foreground objects and entire images to fit target distributions. Then we propose to control the diffusion model using synthesized visual prompts with spatial constraints and object-wise textual descriptions. ODGEN exhibits robustness in handling complex scenes and specific domains. Further, we design a dataset synthesis pipeline to evaluate ODGEN on 7 domain-specific benchmarks to demonstrate its effectiveness. Adding training data generated by ODGEN improves up to 25.3% [email protected]:.95 with object detectors like YOLOv5 and YOLOv7, outperforming prior controllable generative methods. In addition, we design an evaluation protocol based on COCO-2014 to validate ODGEN in general domains and observe an advantage up to 5.6% in [email protected]:.95 against existing methods.
Read more5/27/2024
📉
0
Discovery and Expansion of New Domains within Diffusion Models
Ye Zhu, Yu Wu, Duo Xu, Zhiwei Deng, Yan Yan, Olga Russakovsky
In this work, we study the generalization properties of diffusion models in a few-shot setup, introduce a novel tuning-free paradigm to synthesize the target out-of-domain (OOD) data, and demonstrate its advantages compared to existing methods in data-sparse scenarios with large domain gaps. Specifically, given a pre-trained model and a small set of images that are OOD relative to the model's training distribution, we explore whether the frozen model is able to generalize to this new domain. We begin by revealing that Denoising Diffusion Probabilistic Models (DDPMs) trained on single-domain images are already equipped with sufficient representation abilities to reconstruct arbitrary images from the inverted latent encoding following bi-directional deterministic diffusion and denoising trajectories. We then demonstrate through both theoretical and empirical perspectives that the OOD images establish Gaussian priors in latent spaces of the given model, and the inverted latent modes are separable from their initial training domain. We then introduce our novel tuning-free paradigm to synthesize new images of the target unseen domain by discovering qualified OOD latent encodings in the inverted noisy spaces. This is fundamentally different from the current paradigm that seeks to modify the denoising trajectory to achieve the same goal by tuning the model parameters. Extensive cross-model and domain experiments show that our proposed method can expand the latent space and generate unseen images via frozen DDPMs without impairing the quality of generation of their original domain. We also showcase a practical application of our proposed heuristic approach in dramatically different domains using astrophysical data, revealing the great potential of such a generalization paradigm in data spare fields such as scientific explorations.
Read more5/28/2024

0
Can OOD Object Detectors Learn from Foundation Models?
Jiahui Liu, Xin Wen, Shizhen Zhao, Yingxian Chen, Xiaojuan Qi
Out-of-distribution (OOD) object detection is a challenging task due to the absence of open-set OOD data. Inspired by recent advancements in text-to-image generative models, such as Stable Diffusion, we study the potential of generative models trained on large-scale open-set data to synthesize OOD samples, thereby enhancing OOD object detection. We introduce SyncOOD, a simple data curation method that capitalizes on the capabilities of large foundation models to automatically extract meaningful OOD data from text-to-image generative models. This offers the model access to open-world knowledge encapsulated within off-the-shelf foundation models. The synthetic OOD samples are then employed to augment the training of a lightweight, plug-and-play OOD detector, thus effectively optimizing the in-distribution (ID)/OOD decision boundaries. Extensive experiments across multiple benchmarks demonstrate that SyncOOD significantly outperforms existing methods, establishing new state-of-the-art performance with minimal synthetic data usage.
Read more9/10/2024

0
Diffusion for Out-of-Distribution Detection on Road Scenes and Beyond
Silvio Galesso, Philipp Schroppel, Hssan Driss, Thomas Brox
In recent years, research on out-of-distribution (OoD) detection for semantic segmentation has mainly focused on road scenes -- a domain with a constrained amount of semantic diversity. In this work, we challenge this constraint and extend the domain of this task to general natural images. To this end, we introduce: 1. the ADE-OoD benchmark, which is based on the ADE20k dataset and includes images from diverse domains with a high semantic diversity, and 2. a novel approach that uses Diffusion score matching for OoD detection (DOoD) and is robust to the increased semantic diversity. ADE-OoD features indoor and outdoor images, defines 150 semantic categories as in-distribution, and contains a variety of OoD objects. For DOoD, we train a diffusion model with an MLP architecture on semantic in-distribution embeddings and build on the score matching interpretation to compute pixel-wise OoD scores at inference time. On common road scene OoD benchmarks, DOoD performs on par or better than the state of the art, without using outliers for training or making assumptions about the data domain. On ADE-OoD, DOoD outperforms previous approaches, but leaves much room for future improvements.
Read more7/23/2024