Disentangling the Prosody and Semantic Information with Pre-trained Model for In-Context Learning based Zero-Shot Voice Conversion

0
📈
Sign in to get full access
Overview
- The provided content is a rebuttal letter for a research paper, Paper 184.
- The letter addresses comments and questions from the paper's reviewers, specifically Reviewer #2.
- The letter provides further explanations and clarifications to address the reviewers' concerns.
Plain English Explanation
The researchers who authored Paper 184 have received feedback from the reviewers. In this rebuttal letter, they are responding to the comments and questions raised by Reviewer #2.
The main points they are addressing include:
- Conducting an ablation study to understand the impact of the ICL algorithm, model structure, and training objectives
- Providing more details on the dataset and the data collection process
- Clarifying the motivations and potential real-world applications of their research
By addressing these concerns, the researchers aim to strengthen the presentation of their work and provide a more comprehensive understanding of their findings.
Technical Explanation
The rebuttal letter begins by thanking the reviewers for their recognition of the paper. The authors then proceed to address the specific comments and questions raised by Reviewer #2.
Firstly, Reviewer #2 requested an ablation study to understand the individual contributions of the ICL algorithm, model structure, and training objectives. The authors indicate that they will conduct this analysis and include the results in the revised paper.
Secondly, Reviewer #2 asked for more details on the dataset and data collection process. The authors state that they will provide this information to give the reviewers a better understanding of the data used in the study.
Finally, Reviewer #2 sought clarification on the motivations and potential real-world applications of the research. The authors promise to expand on these aspects in the revised version of the paper to better communicate the significance and impact of their work.
Critical Analysis
The rebuttal letter demonstrates the researchers' willingness to address the reviewers' concerns and improve the quality of their paper. By conducting the requested ablation study and providing more detailed information on the dataset and research motivations, the authors are taking steps to strengthen the technical rigor and transparency of their work.
However, the letter does not mention any potential limitations or caveats of the research that were not addressed in the original paper. It would be helpful for the authors to acknowledge any remaining uncertainties or areas for further investigation to give the reviewers a more comprehensive understanding of the work's strengths and weaknesses.
Additionally, the letter could benefit from a more critical assessment of the reviewers' comments. While the authors are responsive to the requests, they could potentially challenge or question certain aspects of the feedback to demonstrate a deeper engagement with the research and its evaluation.
Conclusion
The rebuttal letter effectively communicates the researchers' plans to address the concerns raised by Reviewer #2 and improve the overall quality of Paper 184. By conducting the requested analyses and providing additional contextual information, the authors are taking steps to strengthen the technical rigor and clarity of their work.
To further enhance the rebuttal, the authors could consider incorporating a more critical analysis of the reviewers' comments and acknowledging any remaining limitations or areas for future research. This would demonstrate a deeper engagement with the research process and a commitment to continuous improvement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Disentangling the Prosody and Semantic Information with Pre-trained Model for In-Context Learning based Zero-Shot Voice Conversion
Zhengyang Chen, Shuai Wang, Mingyang Zhang, Xuechen Liu, Junichi Yamagishi, Yanmin Qian
Voice conversion (VC) aims to modify the speaker's timbre while retaining speech content. Previous approaches have tokenized the outputs from self-supervised into semantic tokens, facilitating disentanglement of speech content information. Recently, in-context learning (ICL) has emerged in text-to-speech (TTS) systems for effectively modeling specific characteristics such as timbre through context conditioning. This paper proposes an ICL capability enhanced VC system (ICL-VC) employing a mask and reconstruction training strategy based on flow-matching generative models. Augmented with semantic tokens, our experiments on the LibriTTS dataset demonstrate that ICL-VC improves speaker similarity. Additionally, we find that k-means is a versatile tokenization method applicable to various pre-trained models. However, the ICL-VC system faces challenges in preserving the prosody of the source speech. To mitigate this issue, we propose incorporating prosody embeddings extracted from a pre-trained emotion recognition model into our system. Integration of prosody embeddings notably enhances the system's capability to preserve source speech prosody, as validated on the Emotional Speech Database.
Read more9/11/2024
0
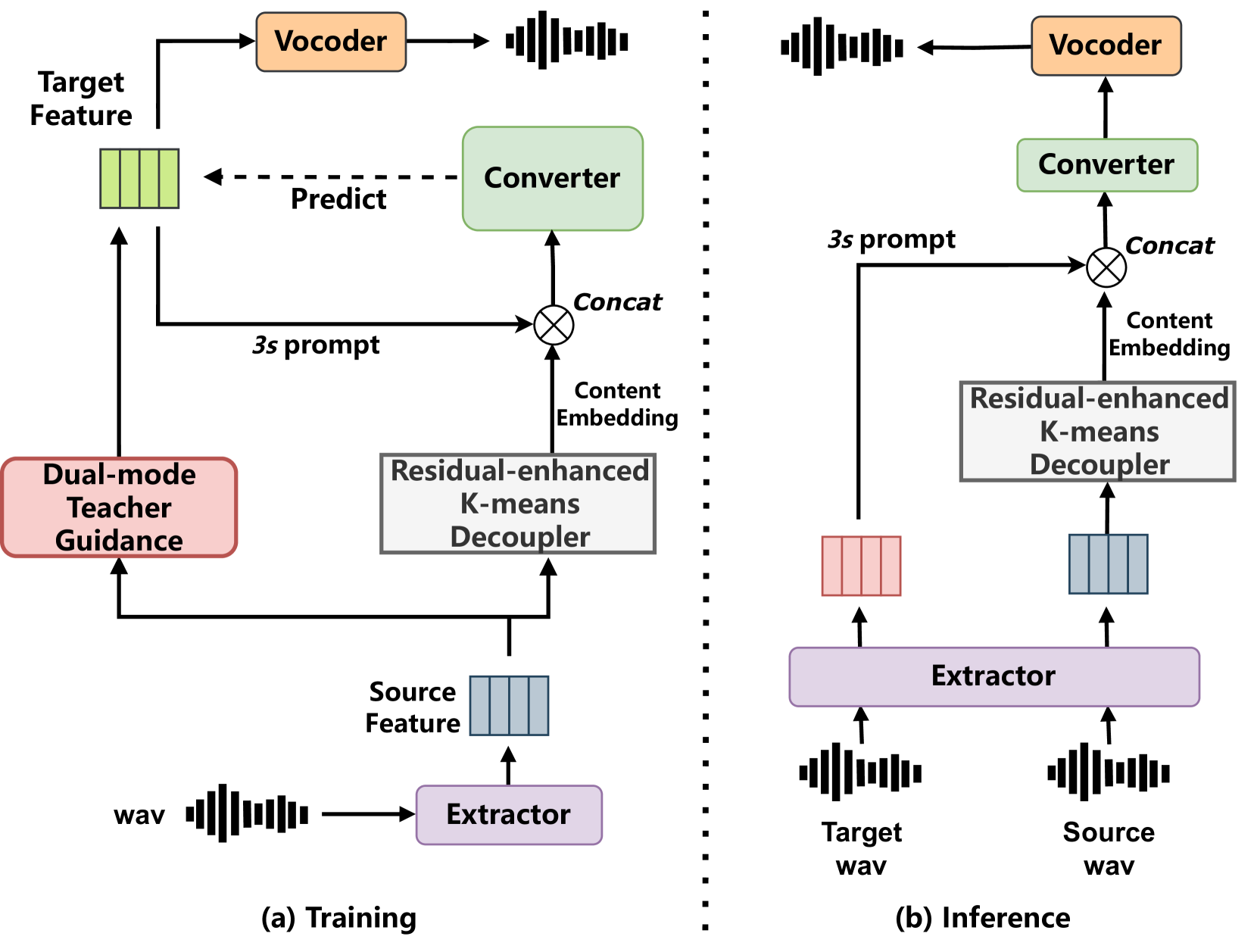
Vec-Tok-VC+: Residual-enhanced Robust Zero-shot Voice Conversion with Progressive Constraints in a Dual-mode Training Strategy
Linhan Ma, Xinfa Zhu, Yuanjun Lv, Zhichao Wang, Ziqian Wang, Wendi He, Hongbin Zhou, Lei Xie
Zero-shot voice conversion (VC) aims to transform source speech into arbitrary unseen target voice while keeping the linguistic content unchanged. Recent VC methods have made significant progress, but semantic losses in the decoupling process as well as training-inference mismatch still hinder conversion performance. In this paper, we propose Vec-Tok-VC+, a novel prompt-based zero-shot VC model improved from Vec-Tok Codec, achieving voice conversion given only a 3s target speaker prompt. We design a residual-enhanced K-Means decoupler to enhance the semantic content extraction with a two-layer clustering process. Besides, we employ teacher-guided refinement to simulate the conversion process to eliminate the training-inference mismatch, forming a dual-mode training strategy. Furthermore, we design a multi-codebook progressive loss function to constrain the layer-wise output of the model from coarse to fine to improve speaker similarity and content accuracy. Objective and subjective evaluations demonstrate that Vec-Tok-VC+ outperforms the strong baselines in naturalness, intelligibility, and speaker similarity.
Read more6/17/2024

0
StreamVoice: Streamable Context-Aware Language Modeling for Real-time Zero-Shot Voice Conversion
Zhichao Wang, Yuanzhe Chen, Xinsheng Wang, Lei Xie, Yuping Wang
Recent language model (LM) advancements have showcased impressive zero-shot voice conversion (VC) performance. However, existing LM-based VC models usually apply offline conversion from source semantics to acoustic features, demanding the complete source speech and limiting their deployment to real-time applications. In this paper, we introduce StreamVoice, a novel streaming LM-based model for zero-shot VC, facilitating real-time conversion given arbitrary speaker prompts and source speech. Specifically, to enable streaming capability, StreamVoice employs a fully causal context-aware LM with a temporal-independent acoustic predictor, while alternately processing semantic and acoustic features at each time step of autoregression which eliminates the dependence on complete source speech. To address the potential performance degradation from the incomplete context in streaming processing, we enhance the context-awareness of the LM through two strategies: 1) teacher-guided context foresight, using a teacher model to summarize the present and future semantic context during training to guide the model's forecasting for missing context; 2) semantic masking strategy, promoting acoustic prediction from preceding corrupted semantic and acoustic input, enhancing context-learning ability. Notably, StreamVoice is the first LM-based streaming zero-shot VC model without any future look-ahead. Experiments demonstrate StreamVoice's streaming conversion capability while achieving zero-shot performance comparable to non-streaming VC systems.
Read more7/22/2024

0
Zero-Shot Sing Voice Conversion: built upon clustering-based phoneme representations
Wangjin Zhou, Fengrun Zhang, Yiming Liu, Wenhao Guan, Yi Zhao, He Qu
This study presents an innovative Zero-Shot any-to-any Singing Voice Conversion (SVC) method, leveraging a novel clustering-based phoneme representation to effectively separate content, timbre, and singing style. This approach enables precise voice characteristic manipulation. We discovered that datasets with fewer recordings per artist are more susceptible to timbre leakage. Extensive testing on over 10,000 hours of singing and user feedback revealed our model significantly improves sound quality and timbre accuracy, aligning with our objectives and advancing voice conversion technology. Furthermore, this research advances zero-shot SVC and sets the stage for future work on discrete speech representation, emphasizing the preservation of rhyme.
Read more9/14/2024