Vec-Tok-VC+: Residual-enhanced Robust Zero-shot Voice Conversion with Progressive Constraints in a Dual-mode Training Strategy

0
Sign in to get full access
Overview
- This paper presents a novel voice conversion (VC) model called "Vec-Tok-VC+" that aims to address the challenges of zero-shot VC, where the model can convert speech from a source speaker to a target speaker without any parallel training data.
- The key innovations of Vec-Tok-VC+ include a residual-enhanced architecture, progressive constraints, and a dual-mode training strategy that leverages both vector-based and token-based representations.
- The proposed approach demonstrates improved robustness and performance compared to existing zero-shot VC methods, as shown through extensive experiments.
Plain English Explanation
Voice conversion (VC) is the task of transforming the voice of one person (the source speaker) to sound like another person (the target speaker). This can be useful for applications like dubbing, accessibility, and even creative expression. However, traditional VC methods often require a large amount of parallel data, where the same sentences are recorded by both the source and target speakers. This can be difficult and expensive to obtain.
The Vec-Tok-VC+ model introduced in this paper aims to solve this problem by enabling zero-shot VC, which means the model can convert speech from a source speaker to a target speaker without any parallel data. The key innovations in this model include:
-
Residual-enhanced architecture: The model incorporates skip connections and residual blocks to better preserve important features during the transformation process. This helps maintain the quality and identity of the converted speech.
-
Progressive constraints: The training process starts with looser constraints and gradually tightens them, helping the model learn more effective and robust conversions.
-
Dual-mode training: The model is trained on both vector-based and token-based representations of the speech, allowing it to capture different aspects of the audio and speak more naturally.
Through extensive experiments, the researchers show that Vec-Tok-VC+ outperforms existing zero-shot VC methods in terms of speech quality, speaker similarity, and robustness to background noise. This is an important step forward in making VC more accessible and practical for a wider range of applications.
Technical Explanation
The Vec-Tok-VC+ model proposed in this paper builds upon previous work on zero-shot voice conversion and iterative refinement using self-supervision. It introduces several key innovations to address the challenges of zero-shot VC:
-
Residual-enhanced architecture: The model uses skip connections and residual blocks to better preserve important features during the conversion process. This helps maintain the quality and identity of the converted speech, as demonstrated in Multi-Level Temporal-Channel Speaker Retrieval for Zero-Shot Voice Conversion.
-
Progressive constraints: The training process starts with looser constraints and gradually tightens them, helping the model learn more effective and robust conversions. This is similar to the approach used in Noise-Robust Voice Conversion by Conditional Denoising.
-
Dual-mode training: The model is trained on both vector-based and token-based representations of the speech, allowing it to capture different aspects of the audio and speak more naturally. This is inspired by the MAIN-VC model's use of multiple speech representations.
The researchers evaluate the Vec-Tok-VC+ model on a range of zero-shot VC tasks, including speaker similarity, speech quality, and robustness to background noise. The results demonstrate significant improvements over existing zero-shot VC methods, highlighting the effectiveness of the proposed approach.
Critical Analysis
The Vec-Tok-VC+ model presented in this paper is a promising advancement in the field of zero-shot voice conversion. The researchers have carefully designed the model architecture and training strategy to address key challenges in this domain, and the experimental results are impressive.
One potential limitation is the reliance on relatively large pretrained models, such as the vector-based speech representation and token-based language model. While these components provide powerful capabilities, they may also introduce additional complexity and computational requirements. It would be interesting to see if the core innovations of Vec-Tok-VC+ could be applied to more lightweight or efficient model designs.
Additionally, the paper does not provide a detailed analysis of the model's limitations or failure cases. Understanding the scenarios where the model struggles or produces suboptimal results could inform future research directions and help identify areas for improvement.
Overall, the Vec-Tok-VC+ model represents a significant step forward in zero-shot voice conversion, and the researchers have made a valuable contribution to the field. Further exploration of the model's strengths, weaknesses, and potential applications could lead to even more impactful advancements in this important area of speech technology.
Conclusion
The Vec-Tok-VC+ model introduced in this paper tackles the challenge of zero-shot voice conversion, where a speech conversion system can transform the voice of one speaker to sound like another without any parallel training data. The key innovations of this model include a residual-enhanced architecture, progressive constraints, and a dual-mode training strategy that leverages both vector-based and token-based speech representations.
Through extensive experiments, the researchers have demonstrated that Vec-Tok-VC+ outperforms existing zero-shot VC methods in terms of speech quality, speaker similarity, and robustness to background noise. This represents an important advancement in the field of voice conversion, potentially enabling a wider range of applications, from dubbing and accessibility to creative expression.
While the model shows promising results, there are opportunities for further exploration, such as investigating more efficient model designs and analyzing the model's limitations and failure cases. Continued research in this direction could lead to even more impactful developments in zero-shot voice conversion, ultimately benefiting a broad range of users and use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Vec-Tok-VC+: Residual-enhanced Robust Zero-shot Voice Conversion with Progressive Constraints in a Dual-mode Training Strategy
Linhan Ma, Xinfa Zhu, Yuanjun Lv, Zhichao Wang, Ziqian Wang, Wendi He, Hongbin Zhou, Lei Xie
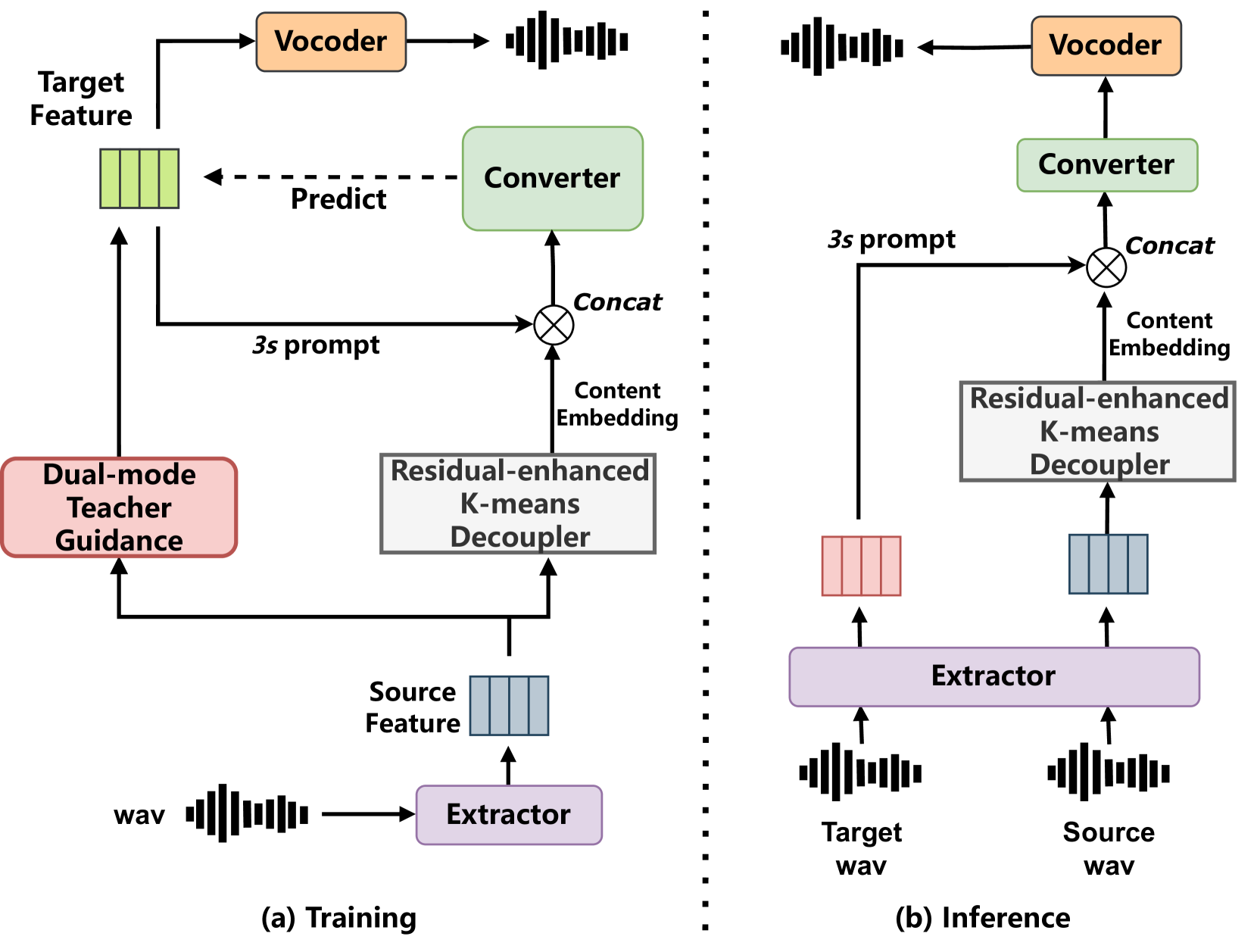
Zero-shot voice conversion (VC) aims to transform source speech into arbitrary unseen target voice while keeping the linguistic content unchanged. Recent VC methods have made significant progress, but semantic losses in the decoupling process as well as training-inference mismatch still hinder conversion performance. In this paper, we propose Vec-Tok-VC+, a novel prompt-based zero-shot VC model improved from Vec-Tok Codec, achieving voice conversion given only a 3s target speaker prompt. We design a residual-enhanced K-Means decoupler to enhance the semantic content extraction with a two-layer clustering process. Besides, we employ teacher-guided refinement to simulate the conversion process to eliminate the training-inference mismatch, forming a dual-mode training strategy. Furthermore, we design a multi-codebook progressive loss function to constrain the layer-wise output of the model from coarse to fine to improve speaker similarity and content accuracy. Objective and subjective evaluations demonstrate that Vec-Tok-VC+ outperforms the strong baselines in naturalness, intelligibility, and speaker similarity.
Read more6/17/2024
📈
0
Disentangling the Prosody and Semantic Information with Pre-trained Model for In-Context Learning based Zero-Shot Voice Conversion
Zhengyang Chen, Shuai Wang, Mingyang Zhang, Xuechen Liu, Junichi Yamagishi, Yanmin Qian
Voice conversion (VC) aims to modify the speaker's timbre while retaining speech content. Previous approaches have tokenized the outputs from self-supervised into semantic tokens, facilitating disentanglement of speech content information. Recently, in-context learning (ICL) has emerged in text-to-speech (TTS) systems for effectively modeling specific characteristics such as timbre through context conditioning. This paper proposes an ICL capability enhanced VC system (ICL-VC) employing a mask and reconstruction training strategy based on flow-matching generative models. Augmented with semantic tokens, our experiments on the LibriTTS dataset demonstrate that ICL-VC improves speaker similarity. Additionally, we find that k-means is a versatile tokenization method applicable to various pre-trained models. However, the ICL-VC system faces challenges in preserving the prosody of the source speech. To mitigate this issue, we propose incorporating prosody embeddings extracted from a pre-trained emotion recognition model into our system. Integration of prosody embeddings notably enhances the system's capability to preserve source speech prosody, as validated on the Emotional Speech Database.
Read more9/11/2024

0
DualVC 3: Leveraging Language Model Generated Pseudo Context for End-to-end Low Latency Streaming Voice Conversion
Ziqian Ning, Shuai Wang, Pengcheng Zhu, Zhichao Wang, Jixun Yao, Lei Xie, Mengxiao Bi
Streaming voice conversion has become increasingly popular for its potential in real-time applications. The recently proposed DualVC 2 has achieved robust and high-quality streaming voice conversion with a latency of about 180ms. Nonetheless, the recognition-synthesis framework hinders end-to-end optimization, and the instability of automatic speech recognition (ASR) model with short chunks makes it challenging to further reduce latency. To address these issues, we propose an end-to-end model, DualVC 3. With speaker-independent semantic tokens to guide the training of the content encoder, the dependency on ASR is removed and the model can operate under extremely small chunks, with cascading errors eliminated. A language model is trained on the content encoder output to produce pseudo context by iteratively predicting future frames, providing more contextual information for the decoder to improve conversion quality. Experimental results demonstrate that DualVC 3 achieves comparable performance to DualVC 2 in subjective and objective metrics, with a latency of only 50 ms.
Read more6/13/2024

0
StreamVoice+: Evolving into End-to-end Streaming Zero-shot Voice Conversion
Zhichao Wang, Yuanzhe Chen, Xinsheng Wang, Lei Xie, Yuping Wang
StreamVoice has recently pushed the boundaries of zero-shot voice conversion (VC) in the streaming domain. It uses a streamable language model (LM) with a context-aware approach to convert semantic features from automatic speech recognition (ASR) into acoustic features with the desired speaker timbre. Despite its innovations, StreamVoice faces challenges due to its dependency on a streaming ASR within a cascaded framework, which complicates system deployment and optimization, affects VC system's design and performance based on the choice of ASR, and struggles with conversion stability when faced with low-quality semantic inputs. To overcome these limitations, we introduce StreamVoice+, an enhanced LM-based end-to-end streaming framework that operates independently of streaming ASR. StreamVoice+ integrates a semantic encoder and a connector with the original StreamVoice framework, now trained using a non-streaming ASR. This model undergoes a two-stage training process: initially, the StreamVoice backbone is pre-trained for voice conversion and the semantic encoder for robust semantic extraction. Subsequently, the system is fine-tuned end-to-end, incorporating a LoRA matrix to activate comprehensive streaming functionality. Furthermore, StreamVoice+ mainly introduces two strategic enhancements to boost conversion quality: a residual compensation mechanism in the connector to ensure effective semantic transmission and a self-refinement strategy that leverages pseudo-parallel speech pairs generated by the conversion backbone to improve speech decoupling. Experiments demonstrate that StreamVoice+ not only achieves higher naturalness and speaker similarity in voice conversion than its predecessor but also provides versatile support for both streaming and non-streaming conversion scenarios.
Read more8/6/2024