Dissecting the Interplay of Attention Paths in a Statistical Mechanics Theory of Transformers
2405.15926
0
0
Abstract
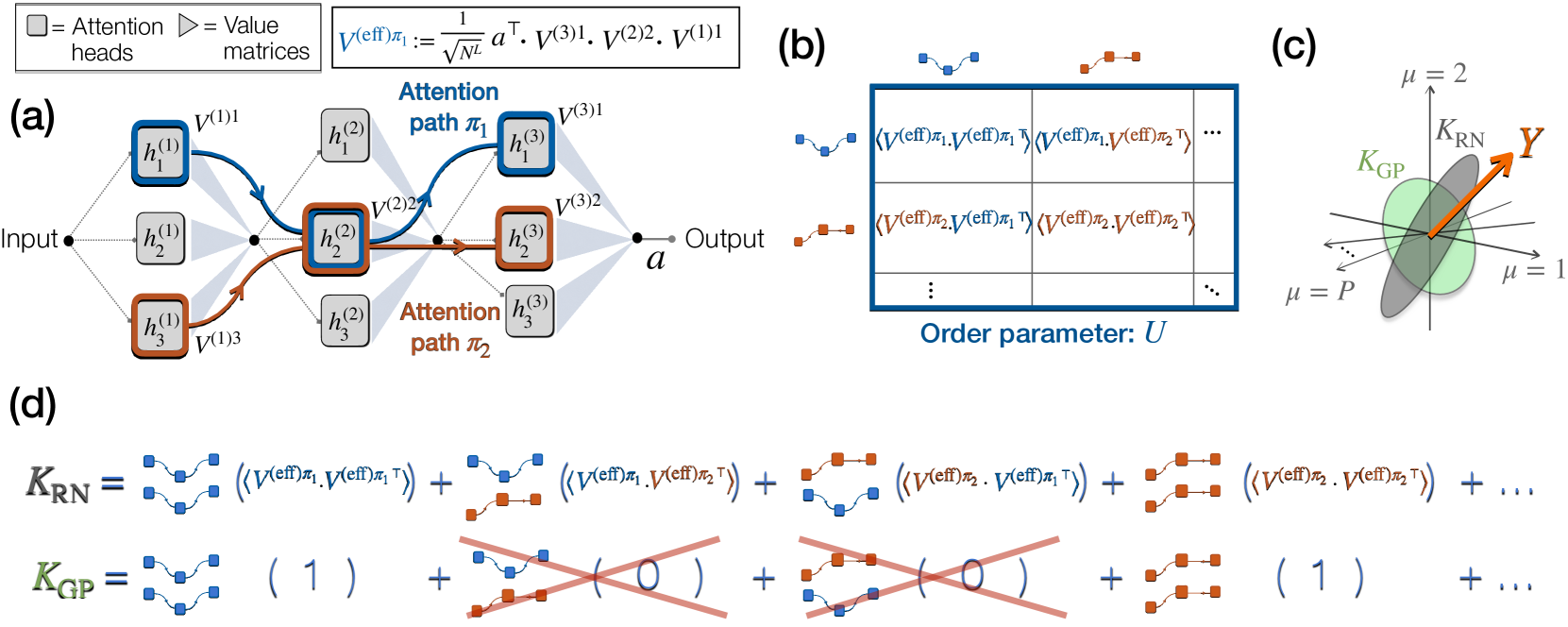
Despite the remarkable empirical performance of Transformers, their theoretical understanding remains elusive. Here, we consider a deep multi-head self-attention network, that is closely related to Transformers yet analytically tractable. We develop a statistical mechanics theory of Bayesian learning in this model, deriving exact equations for the network's predictor statistics under the finite-width thermodynamic limit, i.e., $N,Prightarrowinfty$, $P/N=mathcal{O}(1)$, where $N$ is the network width and $P$ is the number of training examples. Our theory shows that the predictor statistics are expressed as a sum of independent kernels, each one pairing different 'attention paths', defined as information pathways through different attention heads across layers. The kernels are weighted according to a 'task-relevant kernel combination' mechanism that aligns the total kernel with the task labels. As a consequence, this interplay between attention paths enhances generalization performance. Experiments confirm our findings on both synthetic and real-world sequence classification tasks. Finally, our theory explicitly relates the kernel combination mechanism to properties of the learned weights, allowing for a qualitative transfer of its insights to models trained via gradient descent. As an illustration, we demonstrate an efficient size reduction of the network, by pruning those attention heads that are deemed less relevant by our theory.
Create account to get full access
Overview
- The paper presents a statistical mechanics theory for understanding the interplay of attention paths in Transformer models.
- It aims to provide a deeper understanding of how attention mechanisms work in these language models.
- The approach involves mapping attention mechanisms to a generalized Potts model, allowing for the study of attention paths and their interactions.
Plain English Explanation
Transformer models have become highly influential in natural language processing, powering many state-of-the-art language models. A key component of these models is the attention mechanism, which allows them to focus on the most relevant parts of the input when generating output. However, the inner workings of attention can be complex and not fully understood.
This paper proposes a novel approach to studying attention in Transformers by mapping attention mechanisms to a generalized Potts model. The Potts model is a statistical physics concept that can be used to model the interactions between different components in a system. By mapping attention to this framework, the researchers are able to analyze the various "attention paths" that form within the model and how they interact with each other.
This allows for a deeper understanding of how attention mechanisms work in Transformer architectures and the expressive power of the different attention mechanisms employed. The researchers draw connections to previous work on attention as a recurrent neural network and the integration of relational and sensory information in Transformers.
By taking this statistical mechanics approach, the paper provides new insights into the fundamental workings of attention in Transformer models, which could inform the design of future language models and other attention-based architectures.
Technical Explanation
The paper begins by mapping attention mechanisms in Transformer models to a generalized Potts model, a statistical physics concept used to study interacting systems. This allows the researchers to analyze the "attention paths" that form within the model and how they interact with each other.
The authors derive a mathematical framework for this mapping, showing how attention weights can be related to the spin interactions in a Potts model. This enables them to study properties such as the number of attention paths, their lengths, and their interactions.
Through this analysis, the paper reveals several key insights about attention in Transformers. It shows how different attention mechanisms, such as self-attention and cross-attention, can be understood as distinct "phases" in the Potts model. The researchers also demonstrate how the attention paths can be used to disentangle the integration of relational and sensory information within the Transformer architecture.
Furthermore, the paper explores the expressive power of the different attention mechanisms and how they relate to previous work modeling attention as a recurrent neural network.
Critical Analysis
The paper provides a novel and insightful approach to understanding attention mechanisms in Transformer models. By mapping attention to a statistical physics framework, the researchers are able to gain new perspectives on how these models operate.
One potential limitation of the work is the complexity of the Potts model formulation, which may make it challenging for some readers to fully grasp the underlying concepts. The authors could have provided more accessible analogies or examples to help bridge the gap between the technical details and the broader implications.
Additionally, while the paper presents several interesting findings, it does not fully explore the practical implications of these insights. It would be valuable to see how this theoretical understanding of attention could be leveraged to improve the design or performance of Transformer-based models in real-world applications.
Another area for further research could be the exploration of attention mechanisms beyond the Transformer architecture, such as in other neural network models that rely on attention. Extending this statistical mechanics approach to a broader range of attention-based systems could yield additional insights.
Conclusion
This paper offers a novel statistical mechanics perspective on attention mechanisms in Transformer models. By mapping attention to a generalized Potts model, the researchers are able to gain new insights into the interplay of attention paths and the integration of relational and sensory information within these architectures.
The findings presented in the paper contribute to a deeper understanding of the fundamental workings of attention, which could inform the design of future language models and other attention-based systems. While the technical details may be complex, the core ideas and their potential implications are significant for the field of natural language processing and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Mapping of attention mechanisms to a generalized Potts model
Riccardo Rende, Federica Gerace, Alessandro Laio, Sebastian Goldt
0
0
Transformers are neural networks that revolutionized natural language processing and machine learning. They process sequences of inputs, like words, using a mechanism called self-attention, which is trained via masked language modeling (MLM). In MLM, a word is randomly masked in an input sequence, and the network is trained to predict the missing word. Despite the practical success of transformers, it remains unclear what type of data distribution self-attention can learn efficiently. Here, we show analytically that if one decouples the treatment of word positions and embeddings, a single layer of self-attention learns the conditionals of a generalized Potts model with interactions between sites and Potts colors. Moreover, we show that training this neural network is exactly equivalent to solving the inverse Potts problem by the so-called pseudo-likelihood method, well known in statistical physics. Using this mapping, we compute the generalization error of self-attention in a model scenario analytically using the replica method.
4/5/2024

Dynamical Mean-Field Theory of Self-Attention Neural Networks
'Angel Poc-L'opez, Miguel Aguilera
0
0
Transformer-based models have demonstrated exceptional performance across diverse domains, becoming the state-of-the-art solution for addressing sequential machine learning problems. Even though we have a general understanding of the fundamental components in the transformer architecture, little is known about how they operate or what are their expected dynamics. Recently, there has been an increasing interest in exploring the relationship between attention mechanisms and Hopfield networks, promising to shed light on the statistical physics of transformer networks. However, to date, the dynamical regimes of transformer-like models have not been studied in depth. In this paper, we address this gap by using methods for the study of asymmetric Hopfield networks in nonequilibrium regimes --namely path integral methods over generating functionals, yielding dynamics governed by concurrent mean-field variables. Assuming 1-bit tokens and weights, we derive analytical approximations for the behavior of large self-attention neural networks coupled to a softmax output, which become exact in the large limit size. Our findings reveal nontrivial dynamical phenomena, including nonequilibrium phase transitions associated with chaotic bifurcations, even for very simple configurations with a few encoded features and a very short context window. Finally, we discuss the potential of our analytic approach to improve our understanding of the inner workings of transformer models, potentially reducing computational training costs and enhancing model interpretability.
6/12/2024
🖼️
Attention as a Hypernetwork
Simon Schug, Seijin Kobayashi, Yassir Akram, Jo~ao Sacramento, Razvan Pascanu
0
0
Transformers can under some circumstances generalize to novel problem instances whose constituent parts might have been encountered during training but whose compositions have not. What mechanisms underlie this ability for compositional generalization? By reformulating multi-head attention as a hypernetwork, we reveal that a low-dimensional latent code specifies key-query specific operations. We find empirically that this latent code is highly structured, capturing information about the subtasks performed by the network. Using the framework of attention as a hypernetwork we further propose a simple modification of multi-head linear attention that strengthens the ability for compositional generalization on a range of abstract reasoning tasks. In particular, we introduce a symbolic version of the Raven Progressive Matrices human intelligence test on which we demonstrate how scaling model size and data enables compositional generalization and gives rise to a functionally structured latent code in the transformer.
6/24/2024

Attention Meets Post-hoc Interpretability: A Mathematical Perspective
Gianluigi Lopardo, Frederic Precioso, Damien Garreau
0
0
Attention-based architectures, in particular transformers, are at the heart of a technological revolution. Interestingly, in addition to helping obtain state-of-the-art results on a wide range of applications, the attention mechanism intrinsically provides meaningful insights on the internal behavior of the model. Can these insights be used as explanations? Debate rages on. In this paper, we mathematically study a simple attention-based architecture and pinpoint the differences between post-hoc and attention-based explanations. We show that they provide quite different results, and that, despite their limitations, post-hoc methods are capable of capturing more useful insights than merely examining the attention weights.
6/18/2024