Attention as a Hypernetwork
2406.05816
0
0
🖼️
Abstract
Transformers can under some circumstances generalize to novel problem instances whose constituent parts might have been encountered during training but whose compositions have not. What mechanisms underlie this ability for compositional generalization? By reformulating multi-head attention as a hypernetwork, we reveal that a low-dimensional latent code specifies key-query specific operations. We find empirically that this latent code is highly structured, capturing information about the subtasks performed by the network. Using the framework of attention as a hypernetwork we further propose a simple modification of multi-head linear attention that strengthens the ability for compositional generalization on a range of abstract reasoning tasks. In particular, we introduce a symbolic version of the Raven Progressive Matrices human intelligence test on which we demonstrate how scaling model size and data enables compositional generalization and gives rise to a functionally structured latent code in the transformer.
Create account to get full access
Overview
- Transformers can sometimes generalize to novel problem instances, even when the individual components have been encountered during training
- This ability for compositional generalization is not well understood
- The paper proposes a framework of "attention as a hypernetwork" to reveal the mechanisms underlying this capability
Plain English Explanation
Transformers are a type of artificial intelligence model that can be trained on a wide variety of tasks. In some cases, these models can take what they've learned and apply it to solve new problems, even if the specific combination of elements in the new problem hasn't been seen before. This ability, known as compositional generalization, is an important capability that allows AI systems to be more flexible and adaptable.
The researchers in this paper wanted to better understand how transformers are able to achieve this kind of compositional generalization. By reformulating multi-head attention as a hypernetwork, they discovered that a small amount of information - a "latent code" - is used to specify how the transformer should operate on the inputs. This latent code seems to capture important information about the subtasks the transformer needs to perform.
The researchers then proposed a simple modification to the transformer's attention mechanism that further enhances its ability to generalize compositionally. They tested this on a symbolic version of the Raven Progressive Matrices, a task that requires abstract reasoning. As the model size and training data were scaled up, the transformer was able to develop a structured internal representation that enabled it to solve these compositional reasoning problems.
Technical Explanation
The core of the paper's technical contribution is the framework of "attention as a hypernetwork." By reformulating multi-head attention in this way, the researchers revealed that a low-dimensional latent code is used to specify the key-query specific operations performed by the attention mechanism.
Empirically, the researchers found that this latent code is highly structured, capturing important information about the subtasks the transformer needs to perform. This structured latent representation appears to be a key enabler of the transformer's ability to achieve compositional generalization.
Building on this insight, the researchers propose a simple modification to the standard multi-head linear attention mechanism. This modification, which they call "Symbolic Attention," further strengthens the transformer's compositional generalization capabilities, as demonstrated on a symbolic version of the Raven Progressive Matrices task.
The Raven Progressive Matrices is a classic human intelligence test that requires abstract reasoning. By scaling up the model size and training data, the researchers showed that transformers can develop a functionally structured latent code that allows them to solve these compositional reasoning problems.
Critical Analysis
The paper provides a compelling framework for understanding the mechanisms underlying transformers' ability to achieve compositional generalization. The attention-as-a-hypernetwork perspective offers a novel way of thinking about the inner workings of these models, and the proposed Symbolic Attention modification is a promising direction for further improving their reasoning capabilities.
However, the paper does not address some potential limitations or caveats. For example, it's unclear how well the findings would generalize to more complex, real-world tasks, as the Raven Progressive Matrices task is relatively simple and abstract. Additionally, the paper does not explore the interplay between attention and statistical mechanics or the role of token mixing, which could provide additional insights into the nature of compositional generalization in transformers.
Further research is needed to fully understand the limitations of this approach and to explore the continuum of attention-based neural operators that might enable even more powerful compositional reasoning capabilities.
Conclusion
This paper presents a novel framework for understanding the mechanisms underlying transformers' ability to achieve compositional generalization. By reformulating multi-head attention as a hypernetwork, the researchers revealed a structured latent code that appears to be a key enabler of this capability.
The proposed Symbolic Attention modification further enhances transformers' compositional reasoning abilities, as demonstrated on a symbolic version of the Raven Progressive Matrices task. As model size and training data are scaled up, transformers can develop a functionally structured internal representation that allows them to solve these abstract reasoning problems.
While more research is needed to fully understand the limitations and broader implications of this approach, this paper makes an important contribution to our understanding of the inner workings of transformers and their potential for achieving more flexible, adaptable, and compositionally-aware artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

What Matters in Transformers? Not All Attention is Needed
Shwai He, Guoheng Sun, Zheyu Shen, Ang Li
0
0
Scaling Transformer-based large language models (LLMs) has demonstrated promising performance across various tasks. However, this scaling also introduces redundant structures, posing challenges for real-world deployment. Despite some recognition of redundancy in LLMs, the variability of redundancy across different structures, such as MLP and Attention layers, is under-explored. In this work, we investigate the varying redundancy across different modules within Transformers, including Blocks, MLP, and Attention layers, using a similarity-based metric. This metric operates on the premise that redundant structures produce outputs highly similar to their inputs. Surprisingly, while attention layers are essential for transformers and distinguish them from other mainstream architectures, we found that a large proportion of attention layers exhibit excessively high similarity and can be safely pruned without degrading performance, leading to reduced memory and computation costs. Additionally, we further propose a method that jointly drops Attention and MLP layers, achieving improved performance and dropping ratios. Extensive experiments demonstrate the effectiveness of our methods, e.g., Llama-3-70B maintains comparable performance even after pruning half of the attention layers. Our findings provide valuable insights for future network architecture design. The code will be released at: url{https://github.com/Shwai-He/LLM-Drop}.
6/26/2024

A Primal-Dual Framework for Transformers and Neural Networks
Tan M. Nguyen, Tam Nguyen, Nhat Ho, Andrea L. Bertozzi, Richard G. Baraniuk, Stanley J. Osher
0
0
Self-attention is key to the remarkable success of transformers in sequence modeling tasks including many applications in natural language processing and computer vision. Like neural network layers, these attention mechanisms are often developed by heuristics and experience. To provide a principled framework for constructing attention layers in transformers, we show that the self-attention corresponds to the support vector expansion derived from a support vector regression problem, whose primal formulation has the form of a neural network layer. Using our framework, we derive popular attention layers used in practice and propose two new attentions: 1) the Batch Normalized Attention (Attention-BN) derived from the batch normalization layer and 2) the Attention with Scaled Head (Attention-SH) derived from using less training data to fit the SVR model. We empirically demonstrate the advantages of the Attention-BN and Attention-SH in reducing head redundancy, increasing the model's accuracy, and improving the model's efficiency in a variety of practical applications including image and time-series classification.
6/21/2024
✅
Attention as an RNN
Leo Feng, Frederick Tung, Hossein Hajimirsadeghi, Mohamed Osama Ahmed, Yoshua Bengio, Greg Mori
0
0
The advent of Transformers marked a significant breakthrough in sequence modelling, providing a highly performant architecture capable of leveraging GPU parallelism. However, Transformers are computationally expensive at inference time, limiting their applications, particularly in low-resource settings (e.g., mobile and embedded devices). Addressing this, we (1) begin by showing that attention can be viewed as a special Recurrent Neural Network (RNN) with the ability to compute its textit{many-to-one} RNN output efficiently. We then (2) show that popular attention-based models such as Transformers can be viewed as RNN variants. However, unlike traditional RNNs (e.g., LSTMs), these models cannot be updated efficiently with new tokens, an important property in sequence modelling. Tackling this, we (3) introduce a new efficient method of computing attention's textit{many-to-many} RNN output based on the parallel prefix scan algorithm. Building on the new attention formulation, we (4) introduce textbf{Aaren}, an attention-based module that can not only (i) be trained in parallel (like Transformers) but also (ii) be updated efficiently with new tokens, requiring only constant memory for inferences (like traditional RNNs). Empirically, we show Aarens achieve comparable performance to Transformers on $38$ datasets spread across four popular sequential problem settings: reinforcement learning, event forecasting, time series classification, and time series forecasting tasks while being more time and memory-efficient.
5/29/2024
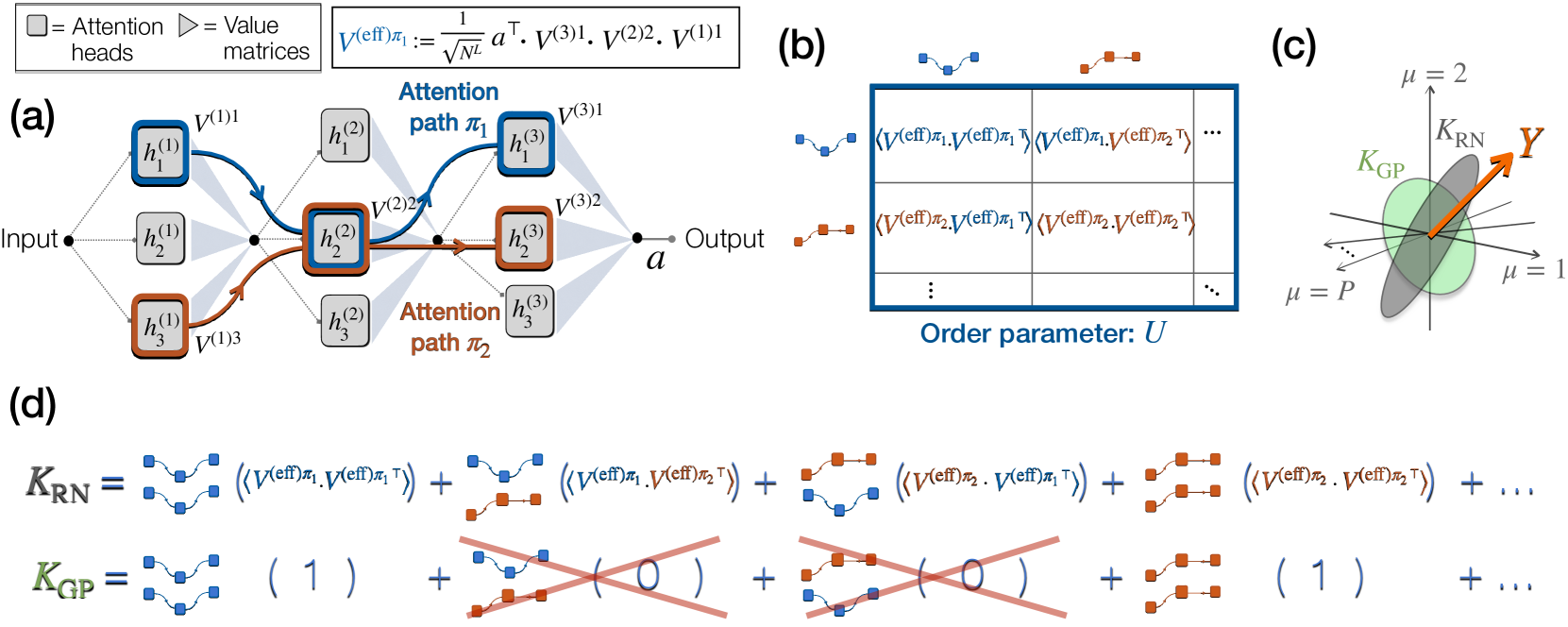
Dissecting the Interplay of Attention Paths in a Statistical Mechanics Theory of Transformers
Lorenzo Tiberi, Francesca Mignacco, Kazuki Irie, Haim Sompolinsky
0
0
Despite the remarkable empirical performance of Transformers, their theoretical understanding remains elusive. Here, we consider a deep multi-head self-attention network, that is closely related to Transformers yet analytically tractable. We develop a statistical mechanics theory of Bayesian learning in this model, deriving exact equations for the network's predictor statistics under the finite-width thermodynamic limit, i.e., $N,Prightarrowinfty$, $P/N=mathcal{O}(1)$, where $N$ is the network width and $P$ is the number of training examples. Our theory shows that the predictor statistics are expressed as a sum of independent kernels, each one pairing different 'attention paths', defined as information pathways through different attention heads across layers. The kernels are weighted according to a 'task-relevant kernel combination' mechanism that aligns the total kernel with the task labels. As a consequence, this interplay between attention paths enhances generalization performance. Experiments confirm our findings on both synthetic and real-world sequence classification tasks. Finally, our theory explicitly relates the kernel combination mechanism to properties of the learned weights, allowing for a qualitative transfer of its insights to models trained via gradient descent. As an illustration, we demonstrate an efficient size reduction of the network, by pruning those attention heads that are deemed less relevant by our theory.
5/28/2024