Attention as an RNN
2405.13956
2
0
✅
Abstract
The advent of Transformers marked a significant breakthrough in sequence modelling, providing a highly performant architecture capable of leveraging GPU parallelism. However, Transformers are computationally expensive at inference time, limiting their applications, particularly in low-resource settings (e.g., mobile and embedded devices). Addressing this, we (1) begin by showing that attention can be viewed as a special Recurrent Neural Network (RNN) with the ability to compute its textit{many-to-one} RNN output efficiently. We then (2) show that popular attention-based models such as Transformers can be viewed as RNN variants. However, unlike traditional RNNs (e.g., LSTMs), these models cannot be updated efficiently with new tokens, an important property in sequence modelling. Tackling this, we (3) introduce a new efficient method of computing attention's textit{many-to-many} RNN output based on the parallel prefix scan algorithm. Building on the new attention formulation, we (4) introduce textbf{Aaren}, an attention-based module that can not only (i) be trained in parallel (like Transformers) but also (ii) be updated efficiently with new tokens, requiring only constant memory for inferences (like traditional RNNs). Empirically, we show Aarens achieve comparable performance to Transformers on $38$ datasets spread across four popular sequential problem settings: reinforcement learning, event forecasting, time series classification, and time series forecasting tasks while being more time and memory-efficient.
Create account to get full access
Overview
- Transformers, a breakthrough in sequence modelling, are computationally expensive at inference time, limiting their applications in low-resource settings.
- This paper introduces a new efficient method of computing attention's many-to-many RNN output based on the parallel prefix scan algorithm.
- The paper presents Aaren, an attention-based module that can be trained in parallel like Transformers and updated efficiently with new tokens, requiring only constant memory for inferences like traditional RNNs.
- Empirically, Aarens achieve comparable performance to Transformers on 38 datasets across four popular sequential problem settings while being more time and memory-efficient.
Plain English Explanation
Transformers are a type of machine learning model that have revolutionized the way we handle sequential data, such as text and time series. They are highly effective, but they can be computationally expensive, making them challenging to use on devices with limited resources, like smartphones or embedded systems.
The researchers behind this paper found a way to make attention, a key component of Transformers, more efficient. Attention allows the model to focus on the most relevant parts of the input when generating the output. The researchers showed that attention can be viewed as a special type of Recurrent Neural Network (RNN), which is a common type of machine learning model for sequential data.
Building on this insight, the researchers introduced a new method for computing attention's output efficiently, using an algorithm called the parallel prefix scan. This allowed them to create a new attention-based module called Aaren, which has several advantages:
- It can be trained in parallel, like Transformers, allowing for fast training.
- It can be updated efficiently with new input tokens, requiring only constant memory during inference, like traditional RNNs.
The researchers tested Aaren on a wide range of sequential tasks, such as reinforcement learning, event forecasting, time series classification, and time series forecasting. They found that Aaren performed just as well as Transformers on these tasks, but was more efficient in terms of time and memory usage.
This research is important because it helps address one of the key limitations of Transformers, making them more suitable for use in low-resource settings where computational power is limited. By combining the strengths of Transformers and traditional RNNs, the researchers have created a new model that can be both highly effective and highly efficient.
Technical Explanation
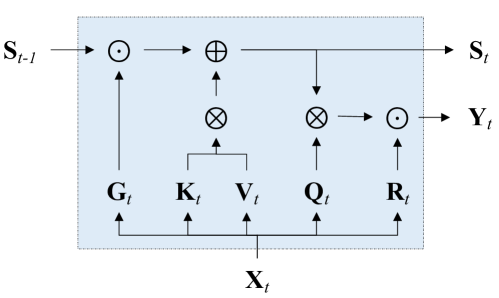
The paper begins by showing that attention can be viewed as a special type of Recurrent Neural Network (RNN) that can efficiently compute its many-to-one RNN output. The researchers then demonstrate that popular attention-based models, such as Transformers, can be seen as RNN variants.
However, unlike traditional RNNs (e.g., LSTMs), these attention-based models cannot be updated efficiently with new tokens, which is an important property in sequence modelling. To address this, the researchers introduce a new efficient method of computing attention's many-to-many RNN output based on the parallel prefix scan algorithm.
Building on this new attention formulation, the researchers introduce Aaren, an attention-based module that can not only be trained in parallel (like Transformers) but also be updated efficiently with new tokens, requiring only constant memory for inferences (like traditional RNNs).
Empirically, the researchers show that Aarens achieve comparable performance to Transformers on 38 datasets spread across four popular sequential problem settings: reinforcement learning, event forecasting, time series classification, and time series forecasting tasks. Importantly, Aarens are more time and memory-efficient than Transformers.
Critical Analysis
The paper provides a novel and insightful approach to addressing the computational challenges of Transformers, particularly in low-resource settings. The researchers' insights into the connection between attention and RNNs, as well as their efficient method for computing attention's output, are valuable contributions to the field.
One potential limitation of the research is that the experiments were conducted on a relatively narrow set of tasks, and it's unclear how well the Aaren module would perform on more complex or diverse sequence modelling problems. Additionally, the paper does not provide a detailed analysis of the tradeoffs between the performance and efficiency of Aaren compared to other attention-based models, such as BurstAttention or TA-RNN.
Further research could explore the performance of Aaren on a wider range of tasks, as well as compare it more extensively with other efficient attention-based models. Additionally, the researchers could investigate the potential for Aaren to be integrated into larger language models or other complex sequence modelling applications, which could further demonstrate the practical benefits of their approach.
Conclusion
This paper presents a significant advancement in the field of sequence modelling by introducing Aaren, an attention-based module that combines the strengths of Transformers and traditional RNNs. Aaren's ability to be trained in parallel while also being efficiently updatable with new tokens makes it a highly promising solution for deploying powerful sequence models in low-resource settings.
The researchers' insights into the connection between attention and RNNs, as well as their efficient method for computing attention's output, are valuable contributions that could have far-reaching implications for the development of more scalable and efficient machine learning models. As the demand for high-performing, yet resource-efficient, sequence models continues to grow, this research represents an important step forward in addressing this challenge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Gated Linear Attention Transformers with Hardware-Efficient Training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, Yoon Kim
0
0
Transformers with linear attention allow for efficient parallel training but can simultaneously be formulated as an RNN with 2D (matrix-valued) hidden states, thus enjoying linear-time inference complexity. However, linear attention generally underperforms ordinary softmax attention. Moreover, current implementations of linear attention lack I/O-awareness and are thus slower than highly optimized implementations of softmax attention. This work describes a hardware-efficient algorithm for linear attention that trades off memory movement against parallelizability. The resulting implementation, dubbed FLASHLINEARATTENTION, is faster than FLASHATTENTION-2 (Dao, 2023) as a standalone layer even on short sequence lengths (e.g., 1K). We then generalize this algorithm to a more expressive variant of linear attention with data-dependent gates. When used as a replacement for the standard attention layer in Transformers, the resulting gated linear attention (GLA) Transformer is found to perform competitively against the LLaMA-architecture Transformer (Touvron et al., 2023) as well recent linear-time-inference baselines such as RetNet (Sun et al., 2023a) and Mamba (Gu & Dao, 2023) on moderate-scale language modeling experiments. GLA Transformer is especially effective at length generalization, enabling a model trained on 2K to generalize to sequences longer than 20K without significant perplexity degradations. For training speed, the GLA Transformer has higher throughput than a similarly-sized Mamba model.
6/6/2024

Breaking the Attention Bottleneck
Kalle Hilsenbek
0
0
Attention-based transformers have become the standard architecture in many deep learning fields, primarily due to their ability to model long-range dependencies and handle variable-length input sequences. However, the attention mechanism with its quadratic complexity is a significant bottleneck in the transformer architecture. This algorithm is only uni-directional in the decoder and converges to a static pattern in over-parametrized decoder-only models. I address this issue by developing a generative function as attention or activation replacement. It still has the auto-regressive character by comparing each token with the previous one. In my test setting with nanoGPT this yields a smaller loss while having a smaller model. The loss further drops by incorporating an average context vector. This concept of attention replacement is distributed under the GNU AGPL v3 license at https://gitlab.com/Bachstelze/causal_generation.
6/18/2024

Lean Attention: Hardware-Aware Scalable Attention Mechanism for the Decode-Phase of Transformers
Rya Sanovar, Srikant Bharadwaj, Renee St. Amant, Victor Ruhle, Saravan Rajmohan
0
0
Transformer-based models have emerged as one of the most widely used architectures for natural language processing, natural language generation, and image generation. The size of the state-of-the-art models has increased steadily reaching billions of parameters. These huge models are memory hungry and incur significant inference latency even on cutting edge AI-accelerators, such as GPUs. Specifically, the time and memory complexity of the attention operation is quadratic in terms of the total context length, i.e., prompt and output tokens. Thus, several optimizations such as key-value tensor caching and FlashAttention computation have been proposed to deliver the low latency demands of applications relying on such large models. However, these techniques do not cater to the computationally distinct nature of different phases during inference. To that end, we propose LeanAttention, a scalable technique of computing self-attention for the token-generation phase (decode-phase) of decoder-only transformer models. LeanAttention enables scaling the attention mechanism implementation for the challenging case of long context lengths by re-designing the execution flow for the decode-phase. We identify that the associative property of online softmax can be treated as a reduction operation thus allowing us to parallelize the attention computation over these large context lengths. We extend the stream-K style reduction of tiled calculation to self-attention to enable parallel computation resulting in an average of 2.6x attention execution speedup over FlashAttention-2 and up to 8.33x speedup for 512k context lengths.
5/20/2024
🖼️
Attention as a Hypernetwork
Simon Schug, Seijin Kobayashi, Yassir Akram, Jo~ao Sacramento, Razvan Pascanu
0
0
Transformers can under some circumstances generalize to novel problem instances whose constituent parts might have been encountered during training but whose compositions have not. What mechanisms underlie this ability for compositional generalization? By reformulating multi-head attention as a hypernetwork, we reveal that a low-dimensional latent code specifies key-query specific operations. We find empirically that this latent code is highly structured, capturing information about the subtasks performed by the network. Using the framework of attention as a hypernetwork we further propose a simple modification of multi-head linear attention that strengthens the ability for compositional generalization on a range of abstract reasoning tasks. In particular, we introduce a symbolic version of the Raven Progressive Matrices human intelligence test on which we demonstrate how scaling model size and data enables compositional generalization and gives rise to a functionally structured latent code in the transformer.
6/24/2024