Distill to Delete: Unlearning in Graph Networks with Knowledge Distillation

0
Sign in to get full access
Overview
- This paper introduces a novel method called "Distill to Delete" for efficiently unlearning knowledge from graph neural networks (GNNs) using knowledge distillation.
- The proposed approach aims to remove specific information from a trained GNN model without having to retrain the entire model from scratch.
- The authors demonstrate the effectiveness of their method on various graph-based tasks, showing significant improvements in unlearning efficiency compared to existing techniques.
Plain English Explanation
The paper discusses a technique called "Distill to Delete" that allows for the selective removal of knowledge from trained graph neural network (GNN) models. GNNs are a type of machine learning model that can learn from data represented as graphs, such as social networks or molecular structures.
<a href="https://aimodels.fyi/papers/arxiv/deep-unlearning-fast-efficient-training-free-approach">Traditional unlearning approaches</a> often require retraining the entire model from scratch, which can be computationally expensive and time-consuming. The "Distill to Delete" method provides a more efficient alternative by leveraging knowledge distillation, a technique that allows a smaller model to learn the knowledge from a larger, more complex model.
The key idea is to train a smaller "student" model to mimic the behavior of the original "teacher" model, but with the specific knowledge that needs to be removed. This student model can then be used to update the original model, effectively deleting the unwanted knowledge without having to retrain the entire network.
The authors demonstrate the effectiveness of their approach on various graph-based tasks, such as node classification and link prediction. They show that "Distill to Delete" can outperform <a href="https://aimodels.fyi/papers/arxiv/gradient-transformation-towards-efficient-model-agnostic-unlearning">existing unlearning techniques</a> in terms of unlearning efficiency, making it a promising method for practical applications where selective knowledge removal is required.
Technical Explanation
The paper introduces a novel method called "Distill to Delete" for efficiently unlearning knowledge from graph neural networks (GNNs) using knowledge distillation.
The proposed approach consists of the following key steps:
-
Identifying the knowledge to be unlearned: The authors assume that the user can specify the knowledge to be removed, such as a set of nodes or edges in the input graph.
-
Training a "student" model: A smaller "student" model is trained to mimic the behavior of the original "teacher" model, but with the specific knowledge that needs to be removed. This is done using a knowledge distillation loss function that encourages the student model to produce similar outputs to the teacher model, but with the target knowledge removed.
-
Updating the original model: The trained student model is then used to update the original teacher model, effectively deleting the unwanted knowledge without having to retrain the entire network.
The authors evaluate their method on various graph-based tasks, including node classification and link prediction, using real-world datasets. They compare the performance of "Distill to Delete" to <a href="https://aimodels.fyi/papers/arxiv/adagmlp-adaboosting-gnn-to-mlp-knowledge-distillation">existing unlearning techniques</a> and demonstrate significant improvements in unlearning efficiency.
Critical Analysis
The paper presents a promising approach for efficiently unlearning knowledge from GNN models, which addresses an important practical challenge in machine learning. The authors have carefully designed their experiments and provided a thorough technical explanation of their method.
One potential limitation of the "Distill to Delete" approach is that it relies on the user's ability to accurately identify the specific knowledge that needs to be removed. In real-world scenarios, this may not always be a straightforward task, and the method's effectiveness could be influenced by the accuracy of this initial step.
Additionally, the authors do not explore the potential for <a href="https://aimodels.fyi/papers/arxiv/rkld-reverse-kl-divergence-based-knowledge-distillation">alternative knowledge distillation techniques</a> or <a href="https://aimodels.fyi/papers/arxiv/dataset-condensation-driven-machine-unlearning">dataset condensation-driven approaches</a> to unlearning, which could provide further improvements in efficiency and flexibility.
Overall, the "Distill to Delete" method represents a valuable contribution to the field of machine unlearning, and the authors have demonstrated its potential through thorough experimentation. Further research exploring the method's robustness and the integration of additional unlearning techniques could help strengthen the proposed approach.
Conclusion
The paper introduces a novel method called "Distill to Delete" for efficiently unlearning knowledge from graph neural networks (GNNs) using knowledge distillation. By training a smaller "student" model to mimic the behavior of the original "teacher" model while removing the target knowledge, the authors demonstrate a more efficient way to update the original model without having to retrain it from scratch.
The experimental results show that "Distill to Delete" can outperform existing unlearning techniques, making it a promising approach for practical applications where selective knowledge removal is required. This work contributes to the growing field of machine unlearning, which aims to develop efficient methods for updating and refining machine learning models in response to changing requirements or newly discovered biases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Distill to Delete: Unlearning in Graph Networks with Knowledge Distillation
Yash Sinha, Murari Mandal, Mohan Kankanhalli
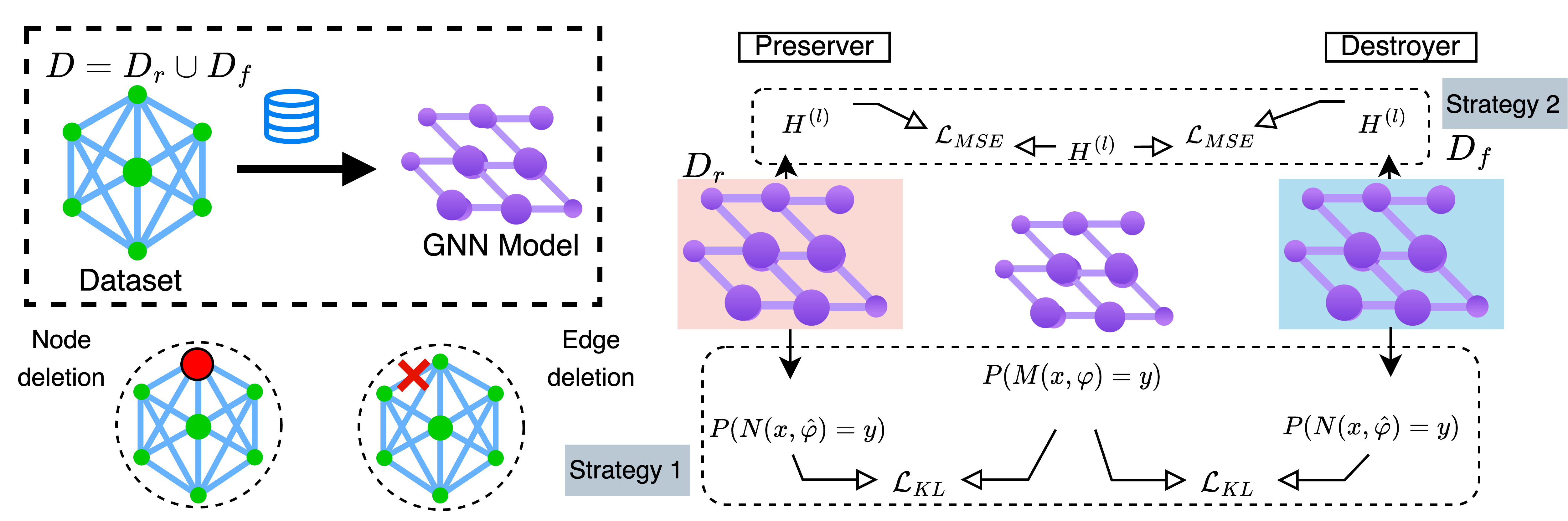
Graph unlearning has emerged as a pivotal method to delete information from a pre-trained graph neural network (GNN). One may delete nodes, a class of nodes, edges, or a class of edges. An unlearning method enables the GNN model to comply with data protection regulations (i.e., the right to be forgotten), adapt to evolving data distributions, and reduce the GPU-hours carbon footprint by avoiding repetitive retraining. Existing partitioning and aggregation-based methods have limitations due to their poor handling of local graph dependencies and additional overhead costs. More recently, GNNDelete offered a model-agnostic approach that alleviates some of these issues. Our work takes a novel approach to address these challenges in graph unlearning through knowledge distillation, as it distills to delete in GNN (D2DGN). It is a model-agnostic distillation framework where the complete graph knowledge is divided and marked for retention and deletion. It performs distillation with response-based soft targets and feature-based node embedding while minimizing KL divergence. The unlearned model effectively removes the influence of deleted graph elements while preserving knowledge about the retained graph elements. D2DGN surpasses the performance of existing methods when evaluated on various real-world graph datasets by up to $43.1%$ (AUC) in edge and node unlearning tasks. Other notable advantages include better efficiency, better performance in removing target elements, preservation of performance for the retained elements, and zero overhead costs. Notably, our D2DGN surpasses the state-of-the-art GNNDelete in AUC by $2.4%$, improves membership inference ratio by $+1.3$, requires $10.2times10^6$ fewer FLOPs per forward pass and up to $mathbf{3.2}times$ faster.
Read more6/11/2024
🧠
0
Gradient Transformation: Towards Efficient and Model-Agnostic Unlearning for Dynamic Graph Neural Networks
He Zhang, Bang Wu, Xiangwen Yang, Xingliang Yuan, Chengqi Zhang, Shirui Pan
Graph unlearning has emerged as an essential tool for safeguarding user privacy and mitigating the negative impacts of undesirable data. Meanwhile, the advent of dynamic graph neural networks (DGNNs) marks a significant advancement due to their superior capability in learning from dynamic graphs, which encapsulate spatial-temporal variations in diverse real-world applications (e.g., traffic forecasting). With the increasing prevalence of DGNNs, it becomes imperative to investigate the implementation of dynamic graph unlearning. However, current graph unlearning methodologies are designed for GNNs operating on static graphs and exhibit limitations including their serving in a pre-processing manner and impractical resource demands. Furthermore, the adaptation of these methods to DGNNs presents non-trivial challenges, owing to the distinctive nature of dynamic graphs. To this end, we propose an effective, efficient, model-agnostic, and post-processing method to implement DGNN unlearning. Specifically, we first define the unlearning requests and formulate dynamic graph unlearning in the context of continuous-time dynamic graphs. After conducting a role analysis on the unlearning data, the remaining data, and the target DGNN model, we propose a method called Gradient Transformation and a loss function to map the unlearning request to the desired parameter update. Evaluations on six real-world datasets and state-of-the-art DGNN backbones demonstrate its effectiveness (e.g., limited performance drop even obvious improvement) and efficiency (e.g., at most 7.23$times$ speed-up) outperformance, and potential advantages in handling future unlearning requests (e.g., at most 32.59$times$ speed-up).
Read more5/24/2024
🧠
0
New!Review of Digital Asset Development with Graph Neural Network Unlearning
Zara Lisbon
In the rapidly evolving landscape of digital assets, the imperative for robust data privacy and compliance with regulatory frameworks has intensified. This paper investigates the critical role of Graph Neural Networks (GNNs) in the management of digital assets and introduces innovative unlearning techniques specifically tailored to GNN architectures. We categorize unlearning strategies into two primary classes: data-driven approximation, which manipulates the graph structure to isolate and remove the influence of specific nodes, and model-driven approximation, which modifies the internal parameters and architecture of the GNN itself. By examining recent advancements in these unlearning methodologies, we highlight their applicability in various use cases, including fraud detection, risk assessment, token relationship prediction, and decentralized governance. We discuss the challenges inherent in balancing model performance with the requirements for data unlearning, particularly in the context of real-time financial applications. Furthermore, we propose a hybrid approach that combines the strengths of both unlearning strategies to enhance the efficiency and effectiveness of GNNs in digital asset ecosystems. Ultimately, this paper aims to provide a comprehensive framework for understanding and implementing GNN unlearning techniques, paving the way for secure and compliant deployment of machine learning in the digital asset domain.
Read more9/30/2024

0
Community-Centric Graph Unlearning
Yi Li, Shichao Zhang, Guixian Zhang, Debo Cheng
Graph unlearning technology has become increasingly important since the advent of the `right to be forgotten' and the growing concerns about the privacy and security of artificial intelligence. Graph unlearning aims to quickly eliminate the effects of specific data on graph neural networks (GNNs). However, most existing deterministic graph unlearning frameworks follow a balanced partition-submodel training-aggregation paradigm, resulting in a lack of structural information between subgraph neighborhoods and redundant unlearning parameter calculations. To address this issue, we propose a novel Graph Structure Mapping Unlearning paradigm (GSMU) and a novel method based on it named Community-centric Graph Eraser (CGE). CGE maps community subgraphs to nodes, thereby enabling the reconstruction of a node-level unlearning operation within a reduced mapped graph. CGE makes the exponential reduction of both the amount of training data and the number of unlearning parameters. Extensive experiments conducted on five real-world datasets and three widely used GNN backbones have verified the high performance and efficiency of our CGE method, highlighting its potential in the field of graph unlearning.
Read more8/20/2024