Gradient Transformation: Towards Efficient and Model-Agnostic Unlearning for Dynamic Graph Neural Networks
2405.14407
0
0
🧠
Abstract
Graph unlearning has emerged as an essential tool for safeguarding user privacy and mitigating the negative impacts of undesirable data. Meanwhile, the advent of dynamic graph neural networks (DGNNs) marks a significant advancement due to their superior capability in learning from dynamic graphs, which encapsulate spatial-temporal variations in diverse real-world applications (e.g., traffic forecasting). With the increasing prevalence of DGNNs, it becomes imperative to investigate the implementation of dynamic graph unlearning. However, current graph unlearning methodologies are designed for GNNs operating on static graphs and exhibit limitations including their serving in a pre-processing manner and impractical resource demands. Furthermore, the adaptation of these methods to DGNNs presents non-trivial challenges, owing to the distinctive nature of dynamic graphs. To this end, we propose an effective, efficient, model-agnostic, and post-processing method to implement DGNN unlearning. Specifically, we first define the unlearning requests and formulate dynamic graph unlearning in the context of continuous-time dynamic graphs. After conducting a role analysis on the unlearning data, the remaining data, and the target DGNN model, we propose a method called Gradient Transformation and a loss function to map the unlearning request to the desired parameter update. Evaluations on six real-world datasets and state-of-the-art DGNN backbones demonstrate its effectiveness (e.g., limited performance drop even obvious improvement) and efficiency (e.g., at most 7.23$times$ speed-up) outperformance, and potential advantages in handling future unlearning requests (e.g., at most 32.59$times$ speed-up).
Create account to get full access
Overview
- Graph unlearning is a crucial tool for protecting user privacy and mitigating the negative impacts of undesirable data.
- Dynamic graph neural networks (DGNNs) are a significant advancement in learning from dynamic graphs, which capture spatial-temporal variations in real-world applications like traffic forecasting.
- Implementing dynamic graph unlearning is essential as DGNNs become more prevalent, but current graph unlearning methods are designed for static graphs and have limitations.
- The paper proposes an effective, efficient, model-agnostic, and post-processing method for dynamic graph unlearning.
Plain English Explanation
Graph unlearning is a way to "forget" certain information that a machine learning model has learned, which can be important for protecting people's privacy and fixing problems caused by bad data. Dynamic graph neural networks are a type of model that are really good at learning from data that changes over time, like how traffic patterns change throughout the day. As these dynamic models become more common, it's crucial to figure out how to "unlearn" information from them too.
However, the current methods for unlearning information from machine learning models were designed for models that work with data that doesn't change over time. Applying these methods to dynamic models presents some challenges because of the unique nature of dynamic data.
The researchers in this paper propose a new way to do dynamic graph unlearning that is effective, efficient, and can work with different types of dynamic models. Their approach involves analyzing the role of the data that needs to be unlearned, the remaining data, and the target dynamic model. Then, they use a special technique called "Gradient Transformation" and a custom loss function to update the model in a way that removes the undesirable information.
Technical Explanation
The paper first defines the concept of unlearning requests and formulates dynamic graph unlearning in the context of continuous-time dynamic graphs. The researchers then conduct a role analysis on the unlearning data, the remaining data, and the target DGNN model.
Based on this analysis, they propose a method called Gradient Transformation and a custom loss function to map the unlearning request to the desired parameter update in the DGNN model. This approach is designed to be effective, efficient, model-agnostic, and applied as a post-processing step.
Experiments on six real-world datasets and state-of-the-art DGNN backbones demonstrate the effectiveness of the proposed method. The authors show that it can achieve limited performance drop or even improvement compared to the original model. It also exhibits significant efficiency, with up to 7.23x speed-up in processing unlearning requests. Furthermore, the method shows potential advantages in handling future unlearning requests, with up to 32.59x speed-up.
Critical Analysis
The paper addresses an important and timely challenge in the field of dynamic graph neural networks by proposing a novel method for dynamic graph unlearning. The authors' approach of conducting a role analysis and using Gradient Transformation is a clever and well-designed solution to the limitations of existing graph unlearning techniques.
However, the paper does not delve into potential limitations or caveats of the proposed method. For example, it would be valuable to understand how the method performs on different types of dynamic graphs or if there are any edge cases where it may not be as effective.
Additionally, the authors could have explored the broader implications of dynamic graph unlearning, such as its impact on model interpretability, potential fairness issues, or the ethical considerations around user privacy and data rights. Unlearning backdoor attacks through gradient-based model could be a relevant link to consider in this context.
Overall, the research presented in the paper is a significant contribution to the field of dynamic graph neural networks and graph unlearning. The authors' proposed method offers a promising approach to address the challenges of unlearning in dynamic graph settings, but further exploration of its limitations and broader implications would strengthen the research.
Conclusion
The paper presents an effective, efficient, and model-agnostic method for implementing dynamic graph unlearning, a crucial capability as dynamic graph neural networks become more prevalent. The authors' approach of conducting a role analysis and using Gradient Transformation to map unlearning requests to parameter updates is a clever solution to the limitations of existing graph unlearning techniques.
The results demonstrate the method's effectiveness in limiting performance drop or even improving model performance, as well as its efficiency in processing unlearning requests. This research represents a significant contribution to the field of dynamic graph neural networks and data selection, transfer, and unlearning, with the potential to enhance user privacy and mitigate the negative impacts of undesirable data in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
How Graph Neural Networks Learn: Lessons from Training Dynamics
Chenxiao Yang, Qitian Wu, David Wipf, Ruoyu Sun, Junchi Yan
0
0
A long-standing goal in deep learning has been to characterize the learning behavior of black-box models in a more interpretable manner. For graph neural networks (GNNs), considerable advances have been made in formalizing what functions they can represent, but whether GNNs will learn desired functions during the optimization process remains less clear. To fill this gap, we study their training dynamics in function space. In particular, we find that the gradient descent optimization of GNNs implicitly leverages the graph structure to update the learned function, as can be quantified by a phenomenon which we call emph{kernel-graph alignment}. We provide theoretical explanations for the emergence of this phenomenon in the overparameterized regime and empirically validate it on real-world GNNs. This finding offers new interpretable insights into when and why the learned GNN functions generalize, highlighting their limitations in heterophilic graphs. Practically, we propose a parameter-free algorithm that directly uses a sparse matrix (i.e. graph adjacency) to update the learned function. We demonstrate that this embarrassingly simple approach can be as effective as GNNs while being orders-of-magnitude faster.
6/19/2024
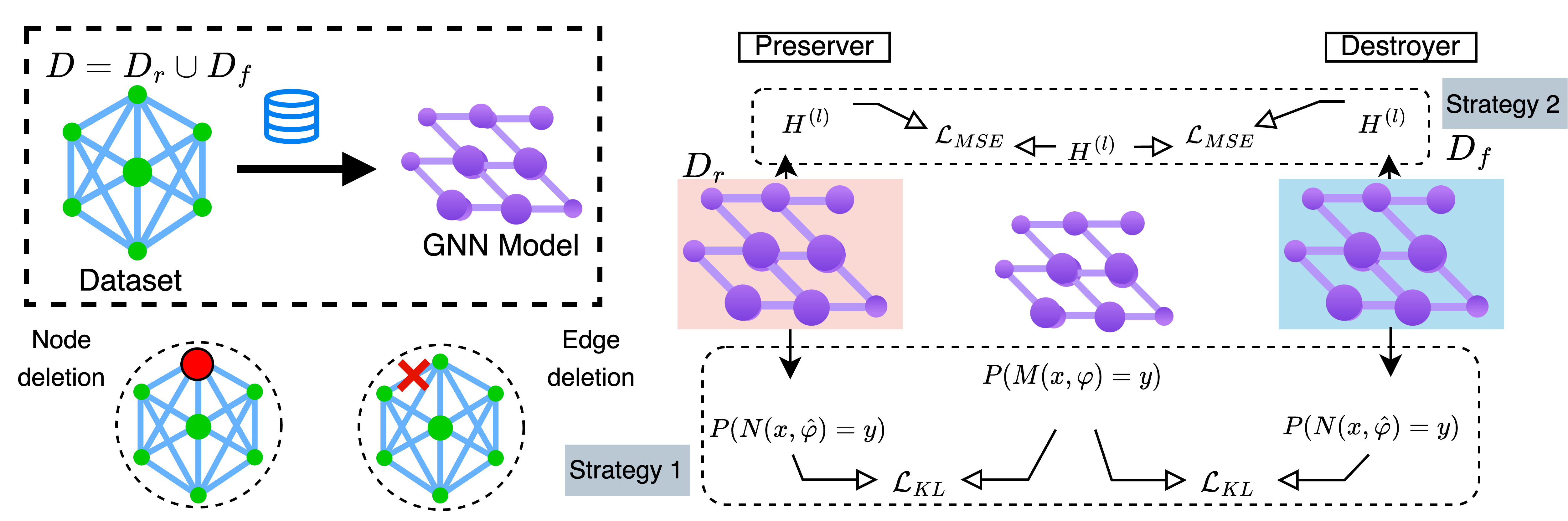
Distill to Delete: Unlearning in Graph Networks with Knowledge Distillation
Yash Sinha, Murari Mandal, Mohan Kankanhalli
0
0
Graph unlearning has emerged as a pivotal method to delete information from a pre-trained graph neural network (GNN). One may delete nodes, a class of nodes, edges, or a class of edges. An unlearning method enables the GNN model to comply with data protection regulations (i.e., the right to be forgotten), adapt to evolving data distributions, and reduce the GPU-hours carbon footprint by avoiding repetitive retraining. Existing partitioning and aggregation-based methods have limitations due to their poor handling of local graph dependencies and additional overhead costs. More recently, GNNDelete offered a model-agnostic approach that alleviates some of these issues. Our work takes a novel approach to address these challenges in graph unlearning through knowledge distillation, as it distills to delete in GNN (D2DGN). It is a model-agnostic distillation framework where the complete graph knowledge is divided and marked for retention and deletion. It performs distillation with response-based soft targets and feature-based node embedding while minimizing KL divergence. The unlearned model effectively removes the influence of deleted graph elements while preserving knowledge about the retained graph elements. D2DGN surpasses the performance of existing methods when evaluated on various real-world graph datasets by up to $43.1%$ (AUC) in edge and node unlearning tasks. Other notable advantages include better efficiency, better performance in removing target elements, preservation of performance for the retained elements, and zero overhead costs. Notably, our D2DGN surpasses the state-of-the-art GNNDelete in AUC by $2.4%$, improves membership inference ratio by $+1.3$, requires $10.2times10^6$ fewer FLOPs per forward pass and up to $mathbf{3.2}times$ faster.
6/11/2024

A More Practical Approach to Machine Unlearning
David Zagardo
0
0
Machine learning models often incorporate vast amounts of data, raising significant privacy concerns. Machine unlearning, the ability to remove the influence of specific data points from a trained model, addresses these concerns. This paper explores practical methods for implementing machine unlearning, focusing on a first-epoch gradient-ascent approach. Key findings include: 1. Single vs. Multi-Epoch Unlearning: First-epoch gradient unlearning is more effective than multi-epoch gradients. 2. Layer-Based Unlearning: The embedding layer in GPT-2 is crucial for effective unlearning. Gradients from the output layers (11 and 12) have no impact. Efficient unlearning can be achieved using only the embedding layer, halving space complexity. 3. Influence Functions & Scoring: Techniques like Hessian Vector Product and the dot product of activations and tensors are used for quantifying unlearning. 4. Gradient Ascent Considerations: Calibration is necessary to avoid overexposing the model to specific data points during unlearning, which could prematurely terminate the process. 5. Fuzzy Matching vs. Iterative Unlearning: Fuzzy matching techniques shift the model to a new optimum, while iterative unlearning provides a more complete modality. Our empirical evaluation confirms that first-epoch gradient ascent for machine unlearning is more effective than whole-model gradient ascent. These results highlight the potential of machine unlearning for enhancing data privacy and compliance with regulations such as GDPR and CCPA. The study underscores the importance of formal methods to comprehensively evaluate the unlearning process.
6/14/2024
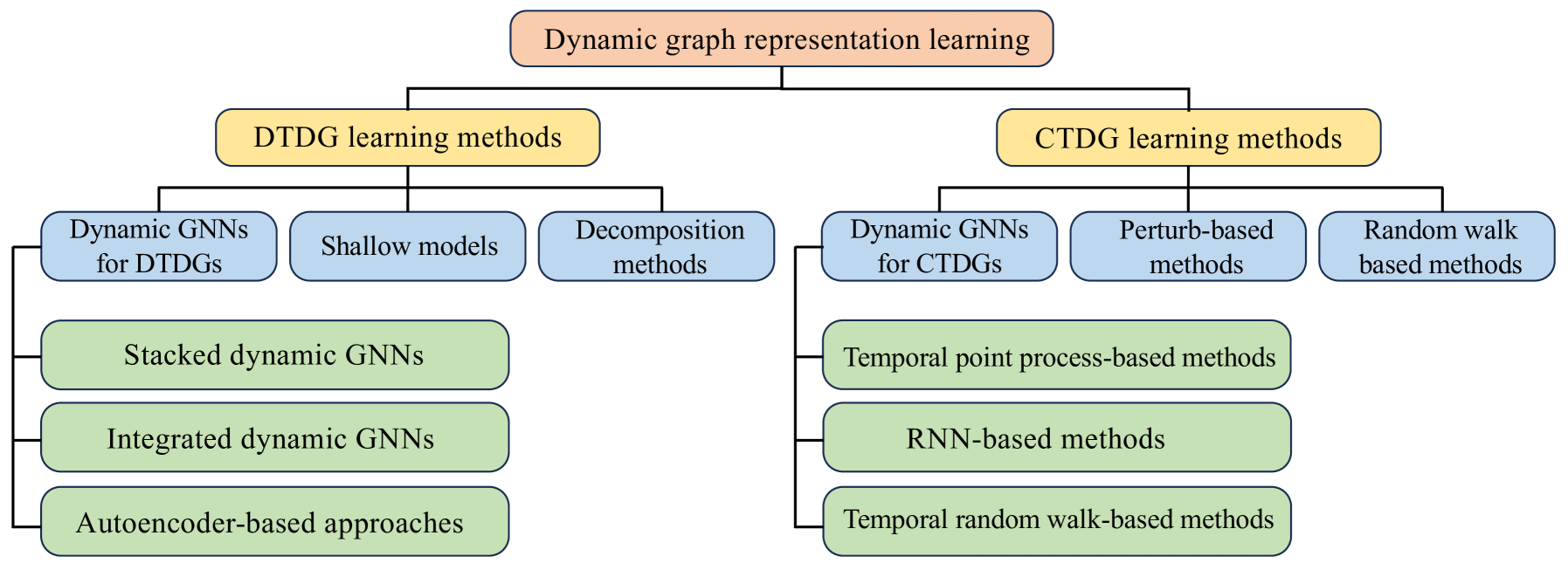
A survey of dynamic graph neural networks
Yanping Zheng, Lu Yi, Zhewei Wei
0
0
Graph neural networks (GNNs) have emerged as a powerful tool for effectively mining and learning from graph-structured data, with applications spanning numerous domains. However, most research focuses on static graphs, neglecting the dynamic nature of real-world networks where topologies and attributes evolve over time. By integrating sequence modeling modules into traditional GNN architectures, dynamic GNNs aim to bridge this gap, capturing the inherent temporal dependencies of dynamic graphs for a more authentic depiction of complex networks. This paper provides a comprehensive review of the fundamental concepts, key techniques, and state-of-the-art dynamic GNN models. We present the mainstream dynamic GNN models in detail and categorize models based on how temporal information is incorporated. We also discuss large-scale dynamic GNNs and pre-training techniques. Although dynamic GNNs have shown superior performance, challenges remain in scalability, handling heterogeneous information, and lack of diverse graph datasets. The paper also discusses possible future directions, such as adaptive and memory-enhanced models, inductive learning, and theoretical analysis.
4/30/2024