Distillation Matters: Empowering Sequential Recommenders to Match the Performance of Large Language Model
2405.00338
0
0
Abstract
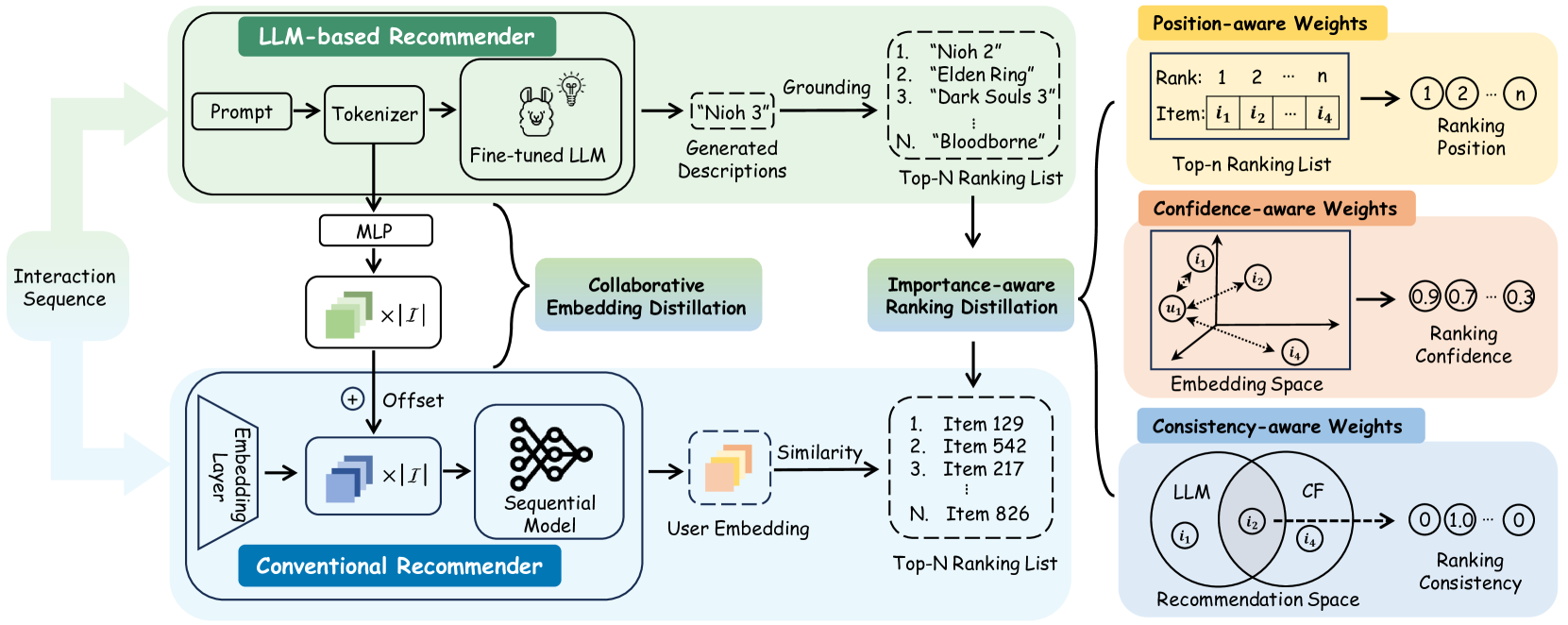
Owing to their powerful semantic reasoning capabilities, Large Language Models (LLMs) have been effectively utilized as recommenders, achieving impressive performance. However, the high inference latency of LLMs significantly restricts their practical deployment. To address this issue, this work investigates knowledge distillation from cumbersome LLM-based recommendation models to lightweight conventional sequential models. It encounters three challenges: 1) the teacher's knowledge may not always be reliable; 2) the capacity gap between the teacher and student makes it difficult for the student to assimilate the teacher's knowledge; 3) divergence in semantic space poses a challenge to distill the knowledge from embeddings. To tackle these challenges, this work proposes a novel distillation strategy, DLLM2Rec, specifically tailored for knowledge distillation from LLM-based recommendation models to conventional sequential models. DLLM2Rec comprises: 1) Importance-aware ranking distillation, which filters reliable and student-friendly knowledge by weighting instances according to teacher confidence and student-teacher consistency; 2) Collaborative embedding distillation integrates knowledge from teacher embeddings with collaborative signals mined from the data. Extensive experiments demonstrate the effectiveness of the proposed DLLM2Rec, boosting three typical sequential models with an average improvement of 47.97%, even enabling them to surpass LLM-based recommenders in some cases.
Create account to get full access
Overview
- This paper explores how knowledge distillation can be used to empower sequential recommenders to match the performance of large language models.
- The researchers propose a novel knowledge distillation approach that allows sequential recommenders to learn from the rich semantic representations of large language models.
- Their method enables sequential recommenders to achieve state-of-the-art performance on various recommendation tasks, rivaling the performance of large language models.
Plain English Explanation
In the world of recommender systems, there is a growing interest in harnessing the power of large language models (LLMs) to enhance the performance of sequential recommenders. Sequential recommenders are models that make personalized recommendations based on a user's past interactions, but they often struggle to match the performance of LLMs, which are trained on vast amounts of data and can capture rich semantic representations.
The researchers in this paper propose a novel approach called "distillation" that allows sequential recommenders to learn from the knowledge stored in LLMs. By distilling this knowledge, the sequential recommenders can gain access to the same semantic representations as the LLMs, enabling them to make more accurate and personalized recommendations.
The key idea behind this distillation process is to train the sequential recommender to mimic the behavior of the LLM, essentially "copying" its knowledge. This is done by having the sequential recommender learn to predict the same outputs as the LLM, such as the next item a user might interact with. By aligning the sequential recommender's outputs with the LLM's, the researchers are able to transfer the LLM's rich understanding of language and user behavior to the sequential recommender.
The result is that the sequential recommender can now achieve state-of-the-art performance on various recommendation tasks, matching or even exceeding the performance of the LLMs themselves. This is a significant breakthrough, as it allows the benefits of LLMs to be enjoyed by sequential recommenders, which are often more efficient and easier to deploy in real-world applications.
Technical Explanation
The researchers propose a novel knowledge distillation approach to empower sequential recommenders to match the performance of large language models (LLMs). Their method, called "Distillation Matters," leverages the rich semantic representations learned by LLMs to enhance the performance of sequential recommenders.
The key technical components of their approach are:
-
LLM Representation Learning: The researchers first train an LLM on a large corpus of data, enabling it to capture rich semantic representations of language and user behavior.
-
Sequential Recommender Architecture: They then design a sequential recommender model that can take advantage of the LLM's representations. This architecture includes modules that can effectively extract and utilize the LLM's knowledge.
-
Knowledge Distillation: The core of their method is a novel knowledge distillation process that transfers the LLM's knowledge to the sequential recommender. This is done by training the sequential recommender to mimic the LLM's outputs, effectively "copying" its rich understanding of language and user behavior.
The researchers evaluate their approach on various recommendation tasks, including next-item recommendation and diverse paraphrase generation. Their results demonstrate that the distilled sequential recommenders can match or even exceed the performance of the LLMs, while being more efficient and easier to deploy.
Critical Analysis
The researchers have made a significant contribution by showing how knowledge distillation can be used to empower sequential recommenders to rival the performance of LLMs. This is an important advancement, as it allows the benefits of LLMs, such as their rich semantic understanding, to be enjoyed by more resource-constrained sequential recommender models.
However, the paper does not address potential limitations or caveats of their approach. For example, it is unclear how well the distillation process would work with different types of LLMs or recommendation tasks. The researchers also do not discuss the potential impact of their approach on model interpretability or fairness, which are important considerations in real-world recommender systems.
Further research could explore the generalizability of the distillation approach, as well as its implications for model transparency and bias. Nonetheless, the core idea of empowering sequential recommenders through knowledge distillation is a promising direction that could have significant practical implications for the field of recommender systems.
Conclusion
This paper presents a novel knowledge distillation approach that allows sequential recommenders to match the performance of large language models. By distilling the rich semantic representations learned by LLMs, the researchers have shown that sequential recommenders can achieve state-of-the-art results on various recommendation tasks.
This breakthrough has important implications for the future of recommender systems, as it enables the benefits of LLMs to be enjoyed by more efficient and deployable sequential models. As the field continues to evolve, further research on the limitations and potential impacts of this distillation-based approach will be crucial to ensure the responsible and effective use of these powerful recommendation technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Intermediate Distillation: Data-Efficient Distillation from Black-Box LLMs for Information Retrieval
Zizhong Li, Haopeng Zhang, Jiawei Zhang
0
0
Recent research has explored distilling knowledge from large language models (LLMs) to optimize retriever models, especially within the retrieval-augmented generation (RAG) framework. However, most existing training methods rely on extracting supervision signals from LLMs' weights or their output probabilities, which is not only resource-intensive but also incompatible with black-box LLMs. In this paper, we introduce textit{Intermediate Distillation}, a data-efficient knowledge distillation training scheme that treats LLMs as black boxes and distills their knowledge via an innovative LLM-ranker-retriever pipeline, solely using LLMs' ranking generation as the supervision signal. Extensive experiments demonstrate that our proposed method can significantly improve the performance of retriever models with only 1,000 training instances. Moreover, our distilled retriever model significantly boosts performance in question-answering tasks within the RAG framework, demonstrating the potential of LLMs to economically and effectively train smaller models.
6/19/2024

New!DistiLLM: Towards Streamlined Distillation for Large Language Models
Jongwoo Ko, Sungnyun Kim, Tianyi Chen, Se-Young Yun
0
0
Knowledge distillation (KD) is widely used for compressing a teacher model to a smaller student model, reducing its inference cost and memory footprint while preserving model capabilities. However, current KD methods for auto-regressive sequence models (e.g., large language models) suffer from missing a standardized objective function. Moreover, the recent use of student-generated outputs to address training-inference mismatches has significantly escalated computational costs. To tackle these issues, we introduce DistiLLM, a more effective and efficient KD framework for auto-regressive language models. DistiLLM comprises two components: (1) a novel skew Kullback-Leibler divergence loss, where we unveil and leverage its theoretical properties, and (2) an adaptive off-policy approach designed to enhance the efficiency in utilizing student-generated outputs. Extensive experiments, including instruction-following tasks, demonstrate the effectiveness of DistiLLM in building high-performing student models while achieving up to 4.3$times$ speedup compared to recent KD methods.
7/4/2024

Knowledge Distillation of LLM for Automatic Scoring of Science Education Assessments
Ehsan Latif, Luyang Fang, Ping Ma, Xiaoming Zhai
0
0
This study proposes a method for knowledge distillation (KD) of fine-tuned Large Language Models (LLMs) into smaller, more efficient, and accurate neural networks. We specifically target the challenge of deploying these models on resource-constrained devices. Our methodology involves training the smaller student model (Neural Network) using the prediction probabilities (as soft labels) of the LLM, which serves as a teacher model. This is achieved through a specialized loss function tailored to learn from the LLM's output probabilities, ensuring that the student model closely mimics the teacher's performance. To validate the performance of the KD approach, we utilized a large dataset, 7T, containing 6,684 student-written responses to science questions and three mathematical reasoning datasets with student-written responses graded by human experts. We compared accuracy with state-of-the-art (SOTA) distilled models, TinyBERT, and artificial neural network (ANN) models. Results have shown that the KD approach has 3% and 2% higher scoring accuracy than ANN and TinyBERT, respectively, and comparable accuracy to the teacher model. Furthermore, the student model size is 0.03M, 4,000 times smaller in parameters and x10 faster in inferencing than the teacher model and TinyBERT, respectively. The significance of this research lies in its potential to make advanced AI technologies accessible in typical educational settings, particularly for automatic scoring.
6/13/2024

DELRec: Distilling Sequential Pattern to Enhance LLM-based Recommendation
Guohao Sun, Haoyi Zhang
0
0
Sequential recommendation (SR) tasks enhance recommendation accuracy by capturing the connection between users' past interactions and their changing preferences. Conventional models often focus solely on capturing sequential patterns within the training data, neglecting the broader context and semantic information embedded in item titles from external sources. This limits their predictive power and adaptability. Recently, large language models (LLMs) have shown promise in SR tasks due to their advanced understanding capabilities and strong generalization abilities. Researchers have attempted to enhance LLMs' recommendation performance by incorporating information from SR models. However, previous approaches have encountered problems such as 1) only influencing LLMs at the result level; 2) increased complexity of LLMs recommendation methods leading to reduced interpretability; 3) incomplete understanding and utilization of SR models information by LLMs. To address these problems, we proposes a novel framework, DELRec, which aims to extract knowledge from SR models and enable LLMs to easily comprehend and utilize this supplementary information for more effective sequential recommendations. DELRec consists of two main stages: 1) SR Models Pattern Distilling, focusing on extracting behavioral patterns exhibited by SR models using soft prompts through two well-designed strategies; 2) LLMs-based Sequential Recommendation, aiming to fine-tune LLMs to effectively use the distilled auxiliary information to perform SR tasks. Extensive experimental results conducted on three real datasets validate the effectiveness of the DELRec framework.
6/19/2024