Distilling Vision-Language Foundation Models: A Data-Free Approach via Prompt Diversification

0

Sign in to get full access
Overview
- A paper that explores a data-free approach to distilling vision-language foundation models by leveraging prompt diversification.
- The key idea is to use a diverse set of prompts to capture the knowledge in a large foundation model, without requiring access to the original training data.
- This allows for efficient knowledge transfer to smaller student models, improving their out-of-distribution generalization capabilities.
Plain English Explanation
The paper presents a novel way to transfer the knowledge from a large, powerful vision-language model to smaller, more specialized models, without needing access to the original training data. This is an important problem because the large foundation models are expensive to train and deploy, but their knowledge can be very useful for a wide range of applications.
The researchers found that by using a diverse set of prompts, they could effectively capture the knowledge in the large model and then distill it into a smaller student model. This process, called data-free knowledge distillation, allows the student model to benefit from the rich understanding of the world that the foundation model has learned, without needing to see the same training data.
The key innovation is the use of prompt diversification. By generating a wide variety of prompts, the researchers were able to capture different aspects of the foundation model's knowledge, rather than relying on a single prompt or a small set of prompts. This makes the distillation process more robust and helps the student model generalize better to new, out-of-distribution data.
Technical Explanation
The paper proposes a data-free knowledge distillation approach for transferring the capabilities of large vision-language foundation models to smaller student models. The key innovation is the use of prompt diversification to capture the rich knowledge encoded in the foundation model, without requiring access to the original training data.
The researchers first generate a diverse set of prompts that cover a wide range of topics and linguistic patterns. They then use these prompts to elicit responses from the foundation model, effectively distilling its knowledge into a set of text outputs. This text-based knowledge representation is then used to train the smaller student model, leveraging techniques like selective dual-teacher knowledge transfer to efficiently transfer the learned capabilities.
The experiments demonstrate that this data-free distillation approach leads to significant improvements in the out-of-distribution generalization capabilities of the student models, compared to traditional knowledge distillation methods that rely on access to the original training data. The researchers attribute this success to the prompt diversification strategy, which allows the student model to learn a more comprehensive and robust representation of the foundation model's knowledge.
Critical Analysis
The paper presents a compelling approach to addressing the challenge of efficiently transferring the capabilities of large vision-language foundation models to smaller, more specialized models. The use of prompt diversification is a clever and effective solution to the data-free knowledge distillation problem.
One potential limitation of the approach is that the success of the distillation process may depend on the quality and diversity of the prompts used. While the researchers demonstrate the effectiveness of their prompt generation strategy, it's possible that in certain domains or use cases, a different set of prompts may be required to fully capture the foundation model's knowledge.
Additionally, the paper does not explore the scalability of the prompt diversification approach as the size and complexity of the foundation model increases. It would be interesting to see how the method performs when scaling to even larger and more capable vision-language models.
Overall, the paper presents a valuable contribution to the field of knowledge distillation and highlights the importance of finding data-efficient ways to leverage the capabilities of large-scale foundation models. The prompt diversification approach is a promising step forward and could have significant implications for the development of more accessible and versatile AI systems.
Conclusion
This paper introduces a data-free approach to distilling the knowledge of large vision-language foundation models into smaller student models. By leveraging prompt diversification, the researchers demonstrate a way to effectively capture the rich understanding encoded in the foundation model, without requiring access to the original training data.
The resulting student models show improved out-of-distribution generalization capabilities, making them more versatile and accessible for a wider range of applications. This work highlights the importance of finding efficient knowledge transfer techniques to democratize the benefits of powerful foundation models, and the prompt diversification strategy represents an important step in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Distilling Vision-Language Foundation Models: A Data-Free Approach via Prompt Diversification
Yunyi Xuan, Weijie Chen, Shicai Yang, Di Xie, Luojun Lin, Yueting Zhuang
Data-Free Knowledge Distillation (DFKD) has shown great potential in creating a compact student model while alleviating the dependency on real training data by synthesizing surrogate data. However, prior arts are seldom discussed under distribution shifts, which may be vulnerable in real-world applications. Recent Vision-Language Foundation Models, e.g., CLIP, have demonstrated remarkable performance in zero-shot out-of-distribution generalization, yet consuming heavy computation resources. In this paper, we discuss the extension of DFKD to Vision-Language Foundation Models without access to the billion-level image-text datasets. The objective is to customize a student model for distribution-agnostic downstream tasks with given category concepts, inheriting the out-of-distribution generalization capability from the pre-trained foundation models. In order to avoid generalization degradation, the primary challenge of this task lies in synthesizing diverse surrogate images driven by text prompts. Since not only category concepts but also style information are encoded in text prompts, we propose three novel Prompt Diversification methods to encourage image synthesis with diverse styles, namely Mix-Prompt, Random-Prompt, and Contrastive-Prompt. Experiments on out-of-distribution generalization datasets demonstrate the effectiveness of the proposed methods, with Contrastive-Prompt performing the best.
Read more7/23/2024

0
PromptKD: Unsupervised Prompt Distillation for Vision-Language Models
Zheng Li, Xiang Li, Xinyi Fu, Xin Zhang, Weiqiang Wang, Shuo Chen, Jian Yang
Prompt learning has emerged as a valuable technique in enhancing vision-language models (VLMs) such as CLIP for downstream tasks in specific domains. Existing work mainly focuses on designing various learning forms of prompts, neglecting the potential of prompts as effective distillers for learning from larger teacher models. In this paper, we introduce an unsupervised domain prompt distillation framework, which aims to transfer the knowledge of a larger teacher model to a lightweight target model through prompt-driven imitation using unlabeled domain images. Specifically, our framework consists of two distinct stages. In the initial stage, we pre-train a large CLIP teacher model using domain (few-shot) labels. After pre-training, we leverage the unique decoupled-modality characteristics of CLIP by pre-computing and storing the text features as class vectors only once through the teacher text encoder. In the subsequent stage, the stored class vectors are shared across teacher and student image encoders for calculating the predicted logits. Further, we align the logits of both the teacher and student models via KL divergence, encouraging the student image encoder to generate similar probability distributions to the teacher through the learnable prompts. The proposed prompt distillation process eliminates the reliance on labeled data, enabling the algorithm to leverage a vast amount of unlabeled images within the domain. Finally, the well-trained student image encoders and pre-stored text features (class vectors) are utilized for inference. To our best knowledge, we are the first to (1) perform unsupervised domain-specific prompt-driven knowledge distillation for CLIP, and (2) establish a practical pre-storing mechanism of text features as shared class vectors between teacher and student. Extensive experiments on 11 datasets demonstrate the effectiveness of our method.
Read more8/14/2024

0
Improving Zero-shot Generalization of Learned Prompts via Unsupervised Knowledge Distillation
Marco Mistretta, Alberto Baldrati, Marco Bertini, Andrew D. Bagdanov
Vision-Language Models (VLMs) demonstrate remarkable zero-shot generalization to unseen tasks, but fall short of the performance of supervised methods in generalizing to downstream tasks with limited data. Prompt learning is emerging as a parameter-efficient method for adapting VLMs, but state-of-the-art approaches require annotated samples. In this paper we propose a novel approach to prompt learning based on unsupervised knowledge distillation from more powerful models. Our approach, which we call Knowledge Distillation Prompt Learning (KDPL), can be integrated into existing prompt learning techniques and eliminates the need for labeled examples during adaptation. Our experiments on more than ten standard benchmark datasets demonstrate that KDPL is very effective at improving generalization of learned prompts for zero-shot domain generalization, zero-shot cross-dataset generalization, and zero-shot base-to-novel class generalization problems. KDPL requires no ground-truth labels for adaptation, and moreover we show that even in the absence of any knowledge of training class names it can be used to effectively transfer knowledge. The code is publicly available at https://github.com/miccunifi/KDPL.
Read more7/31/2024
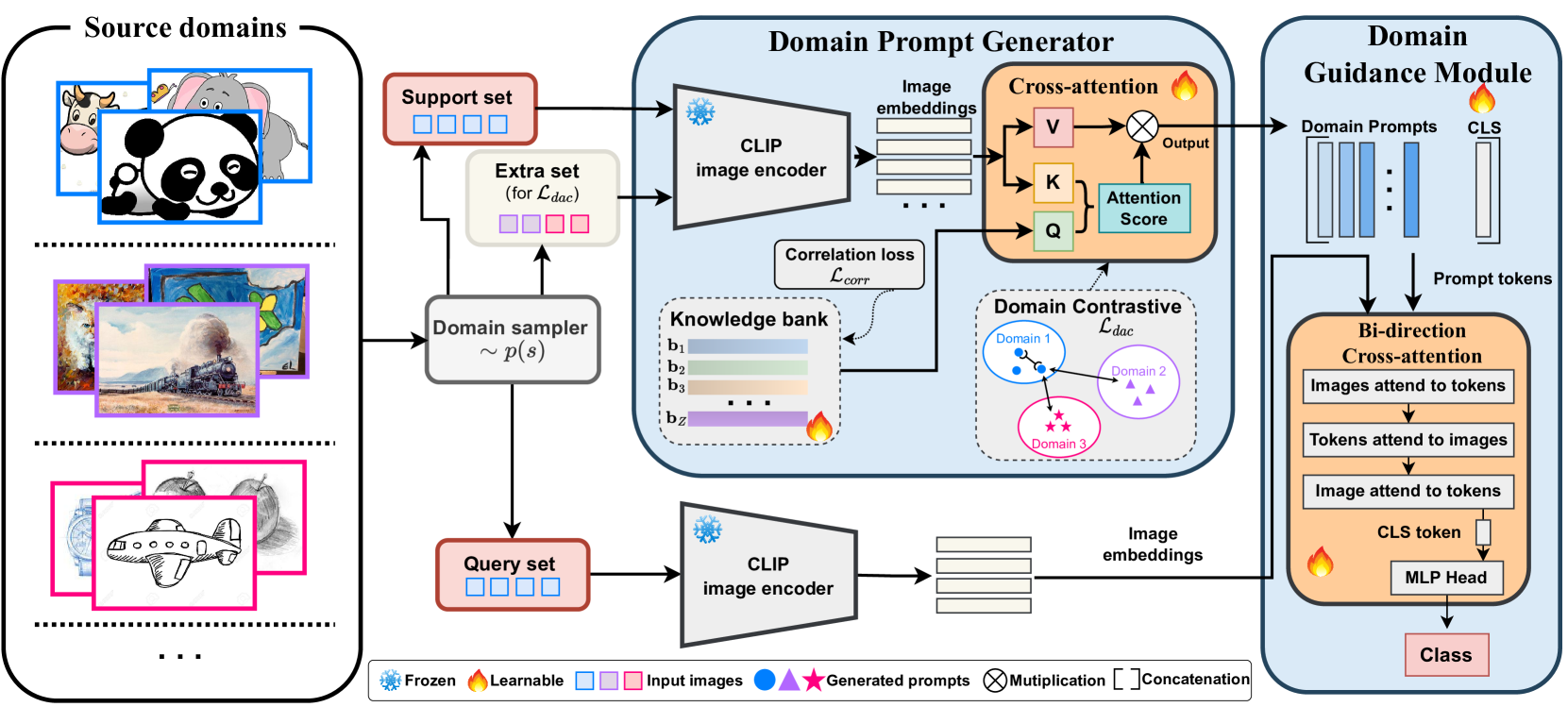
0
Adapting to Distribution Shift by Visual Domain Prompt Generation
Zhixiang Chi, Li Gu, Tao Zhong, Huan Liu, Yuanhao Yu, Konstantinos N Plataniotis, Yang Wang
In this paper, we aim to adapt a model at test-time using a few unlabeled data to address distribution shifts. To tackle the challenges of extracting domain knowledge from a limited amount of data, it is crucial to utilize correlated information from pre-trained backbones and source domains. Previous studies fail to utilize recent foundation models with strong out-of-distribution generalization. Additionally, domain-centric designs are not flavored in their works. Furthermore, they employ the process of modelling source domains and the process of learning to adapt independently into disjoint training stages. In this work, we propose an approach on top of the pre-computed features of the foundation model. Specifically, we build a knowledge bank to learn the transferable knowledge from source domains. Conditioned on few-shot target data, we introduce a domain prompt generator to condense the knowledge bank into a domain-specific prompt. The domain prompt then directs the visual features towards a particular domain via a guidance module. Moreover, we propose a domain-aware contrastive loss and employ meta-learning to facilitate domain knowledge extraction. Extensive experiments are conducted to validate the domain knowledge extraction. The proposed method outperforms previous work on 5 large-scale benchmarks including WILDS and DomainNet.
Read more5/7/2024