Distractors-Immune Representation Learning with Cross-modal Contrastive Regularization for Change Captioning

0
Sign in to get full access
Overview
- This paper proposes a novel approach for change captioning, which involves generating natural language descriptions of visual changes between image pairs.
- The key idea is to use cross-modal contrastive regularization to learn distractors-immune image representations that are robust to irrelevant visual changes.
- This helps the model focus on the important changes when generating captions, leading to more accurate and informative descriptions.
Plain English Explanation
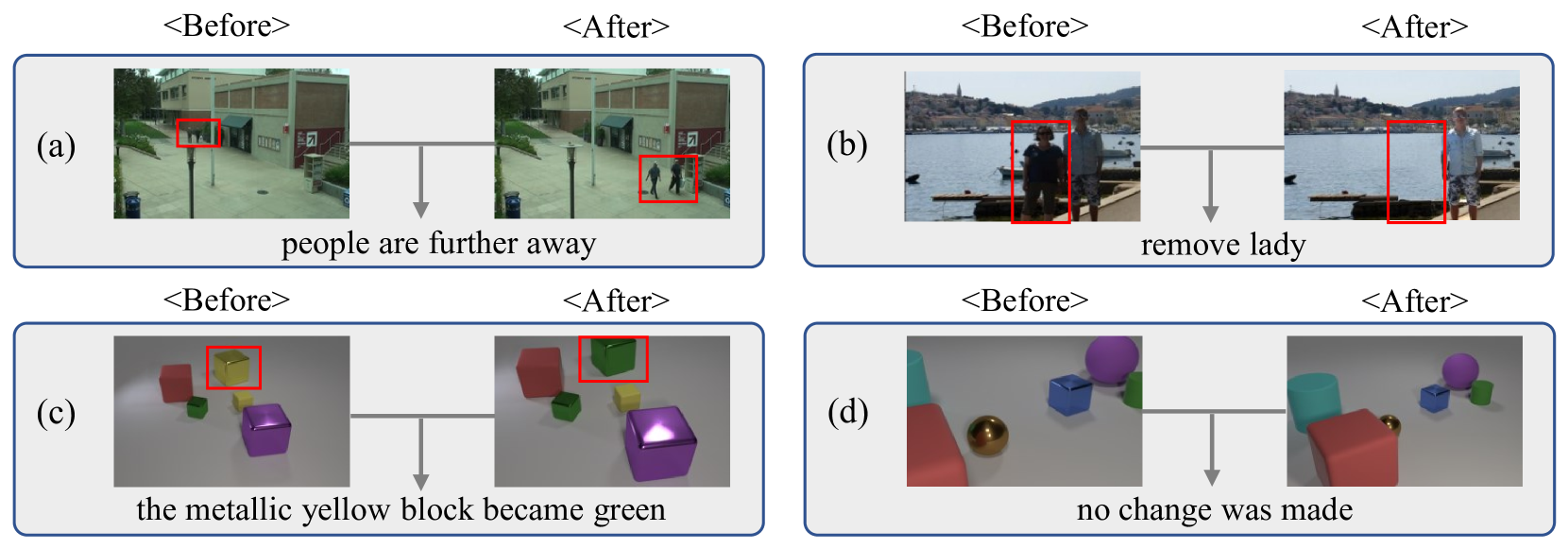
The paper discusses a method for automatically describing the differences between two images using natural language. This task, known as "change captioning", can be useful in various applications like video surveillance, medical imaging, and document analysis.
The main challenge is that there can be many irrelevant visual changes between images, like changes in lighting or camera angle, that shouldn't be included in the caption. The researchers' solution is to use a technique called "cross-modal contrastive regularization" to train the model to focus only on the meaningful changes.
The idea is to have the model learn image representations (numerical encodings of the visual information) that are "distractors-immune" - they are robust to irrelevant visual changes and highlight only the important differences. This is achieved by training the model to compare the image representations to the corresponding captions in a contrastive manner, rewarding it for aligning the representations with the relevant captions and penalizing misalignment.
By learning these distractors-immune representations, the model can then generate captions that accurately describe the key changes between images, without getting distracted by irrelevant visual differences. This leads to more informative and reliable change captioning, which could have applications in various domains.
Technical Explanation
The paper introduces a novel approach for learning distractors-immune image representations for the task of change captioning. The key contribution is the use of cross-modal contrastive regularization to imbue the image representations with robustness to irrelevant visual changes.
The overall architecture consists of an image encoder and a text decoder, connected by a shared multimodal representation space. The image encoder learns visual features that are aligned with the corresponding change captions through contrastive learning. Specifically, the model is trained to pull together the representations of images and their matching captions, while pushing apart the representations of images and mismatched captions.
This cross-modal contrastive regularization encourages the image representations to capture only the relevant changes that are reflected in the captions, while being invariant to distracting visual differences. The authors show that this leads to improved change captioning performance compared to baselines that do not have this distractors-immune representation learning component.
The paper also includes extensive experiments on multiple change captioning benchmarks, demonstrating the effectiveness of the proposed approach. The results indicate that the learned distractors-immune representations enable the model to generate more accurate and informative captions, focusing on the meaningful visual changes.
Critical Analysis
The paper presents a well-designed and theoretically grounded approach to the challenging problem of change captioning. The key strength is the use of cross-modal contrastive regularization to learn distractors-immune image representations, which is a novel and principled solution to the issue of irrelevant visual changes.
One potential limitation is that the method relies on having high-quality caption data aligned with the image pairs. In real-world scenarios, such annotation may not always be readily available, and the model's performance could be affected by noisy or incomplete captions.
Additionally, the paper does not delve into the interpretability of the learned representations. It would be interesting to understand which visual features the model considers important for change captioning and how it distinguishes relevant changes from distractions.
Further research could explore ways to make the approach more robust to diverse types of visual changes, or to extend it to other cross-modal tasks beyond change captioning. Link to Context-Aware Difference Distilling for Multi-Change Captioning, Link to Diffusion RSCC: Diffusion Probabilistic Model for Change Captioning, Link to DiffMatch: Visual-Language Guidance Makes Better Semi, Link to Describing Differences in Image Sets with Natural Language.
Conclusion
This paper presents a novel approach for change captioning that uses cross-modal contrastive regularization to learn distractors-immune image representations. By focusing the image features on the relevant visual changes, the model is able to generate more accurate and informative captions that describe the key differences between images.
The proposed method represents an important step forward in the field of change captioning, with potential applications in areas like surveillance, medical imaging, and document analysis. The insights from this research could also inspire further advancements in cross-modal learning and representation learning more broadly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Distractors-Immune Representation Learning with Cross-modal Contrastive Regularization for Change Captioning
Yunbin Tu, Liang Li, Li Su, Chenggang Yan, Qingming Huang
Change captioning aims to succinctly describe the semantic change between a pair of similar images, while being immune to distractors (illumination and viewpoint changes). Under these distractors, unchanged objects often appear pseudo changes about location and scale, and certain objects might overlap others, resulting in perturbational and discrimination-degraded features between two images. However, most existing methods directly capture the difference between them, which risk obtaining error-prone difference features. In this paper, we propose a distractors-immune representation learning network that correlates the corresponding channels of two image representations and decorrelates different ones in a self-supervised manner, thus attaining a pair of stable image representations under distractors. Then, the model can better interact them to capture the reliable difference features for caption generation. To yield words based on the most related difference features, we further design a cross-modal contrastive regularization, which regularizes the cross-modal alignment by maximizing the contrastive alignment between the attended difference features and generated words. Extensive experiments show that our method outperforms the state-of-the-art methods on four public datasets. The code is available at https://github.com/tuyunbin/DIRL.
Read more7/17/2024

0
Context-aware Difference Distilling for Multi-change Captioning
Yunbin Tu, Liang Li, Li Su, Zheng-Jun Zha, Chenggang Yan, Qingming Huang
Multi-change captioning aims to describe complex and coupled changes within an image pair in natural language. Compared with single-change captioning, this task requires the model to have higher-level cognition ability to reason an arbitrary number of changes. In this paper, we propose a novel context-aware difference distilling (CARD) network to capture all genuine changes for yielding sentences. Given an image pair, CARD first decouples context features that aggregate all similar/dissimilar semantics, termed common/difference context features. Then, the consistency and independence constraints are designed to guarantee the alignment/discrepancy of common/difference context features. Further, the common context features guide the model to mine locally unchanged features, which are subtracted from the pair to distill locally difference features. Next, the difference context features augment the locally difference features to ensure that all changes are distilled. In this way, we obtain an omni-representation of all changes, which is translated into linguistic sentences by a transformer decoder. Extensive experiments on three public datasets show CARD performs favourably against state-of-the-art methods.The code is available at https://github.com/tuyunbin/CARD.
Read more6/10/2024

0
Img-Diff: Contrastive Data Synthesis for Multimodal Large Language Models
Qirui Jiao, Daoyuan Chen, Yilun Huang, Yaliang Li, Ying Shen
High-performance Multimodal Large Language Models (MLLMs) rely heavily on data quality. This study introduces a novel dataset named Img-Diff, designed to enhance fine-grained image recognition in MLLMs by leveraging insights from contrastive learning and image difference captioning. By analyzing object differences between similar images, we challenge models to identify both matching and distinct components. We utilize the Stable-Diffusion-XL model and advanced image editing techniques to create pairs of similar images that highlight object replacements. Our methodology includes a Difference Area Generator for object differences identifying, followed by a Difference Captions Generator for detailed difference descriptions. The result is a relatively small but high-quality dataset of object replacement samples. We use the the proposed dataset to finetune state-of-the-art (SOTA) MLLMs such as MGM-7B, yielding comprehensive improvements of performance scores over SOTA models that trained with larger-scale datasets, in numerous image difference and Visual Question Answering tasks. For instance, our trained models notably surpass the SOTA models GPT-4V and Gemini on the MMVP benchmark. Besides, we investigate alternative methods for generating image difference data through object removal and conduct a thorough evaluation to confirm the dataset's diversity, quality, and robustness, presenting several insights on the synthesis of such a contrastive dataset. To encourage further research and advance the field of multimodal data synthesis and enhancement of MLLMs' fundamental capabilities for image understanding, we release our codes and dataset at https://github.com/modelscope/data-juicer/tree/ImgDiff.
Read more8/12/2024

0
LeOCLR: Leveraging Original Images for Contrastive Learning of Visual Representations
Mohammad Alkhalefi, Georgios Leontidis, Mingjun Zhong
Contrastive instance discrimination approaches outperform supervised learning in downstream tasks like image classification and object detection. However, these approaches heavily rely on data augmentation during representation learning, which may result in inferior results if not properly implemented. Random cropping followed by resizing is a common form of data augmentation used in contrastive learning, but it can lead to degraded representation learning if the two random crops contain distinct semantic content. To address this issue, this paper introduces LeOCLR (Leveraging Original Images for Contrastive Learning of Visual Representations), a framework that employs a new instance discrimination approach and an adapted loss function to alleviate discarding semantic features caused by mapping different object parts during representation learning. The experimental results show that our approach consistently improves representation learning across different datasets compared to baseline models. For example, our approach outperforms MoCo-v2 by 5.1% on ImageNet-1K in linear evaluation and several other methods on transfer learning tasks.
Read more7/22/2024