Context-aware Difference Distilling for Multi-change Captioning

0

Sign in to get full access
Overview
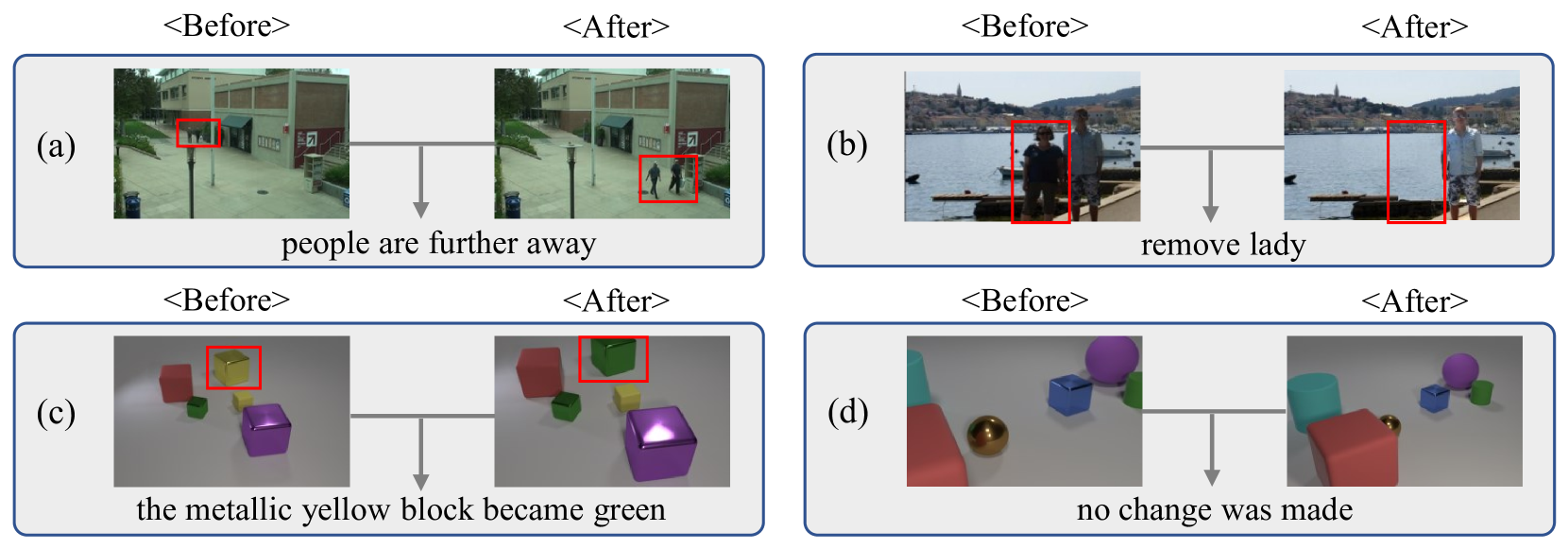
- This paper introduces a novel approach for "multi-change captioning", which aims to generate natural language descriptions of multiple changes between two images.
- The proposed method, called "Context-aware Difference Distilling" (CDD), learns to capture the contextual information around the changes and generate more coherent and comprehensive captions.
- CDD utilizes a "difference distilling" mechanism to selectively attend to the most relevant change regions and a "context-aware" encoder-decoder architecture to incorporate the surrounding context.
Plain English Explanation
The paper presents a system that can describe the differences between two images using natural language. This is a challenging task, as it requires understanding not just the changes themselves, but also the broader context around those changes.
The researchers' approach, called "Context-aware Difference Distilling" (CDD), tries to address this challenge. CDD first identifies the key regions where changes have occurred between the two images. It then uses this information to generate a caption that explains the changes in a coherent and comprehensive way, taking into account the surrounding context.
For example, imagine you have two photos of a room, and the only difference is that a vase has been added to a table. A simple change detection system might just say "a vase has been added." But CDD would also consider the table, the room, and other relevant context to generate a more complete description, such as "A new vase has been placed on the table in the living room."
The key innovation in CDD is this ability to distill the most important change information and combine it with the broader context to produce high-quality, natural-sounding captions. This could be useful in applications like describing differences in image sets, contrastive image retrieval, and change detection.
Technical Explanation
The CDD model consists of two key components: a "difference distilling" module and a "context-aware" encoder-decoder architecture.
The difference distilling module first identifies the regions in the two input images where changes have occurred. It does this by computing a "difference map" that highlights the areas of change. This module then selectively attends to the most relevant change regions, distilling the key information that should be included in the final caption.
The context-aware encoder-decoder takes the distilled change information and the original image pair as input. It uses a transformer-based encoder to extract contextual features from the images, and a transformer-based decoder to generate the final caption. This allows the model to consider not just the changes themselves, but also the broader visual context surrounding those changes.
The researchers trained and evaluated CDD on the CLEVR-Change dataset, which contains image pairs with multiple changes and corresponding human-written captions. CDD outperformed several baseline models, demonstrating its ability to generate more accurate and coherent descriptions of complex multi-change scenarios.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the CDD model, including comparisons to state-of-the-art baselines on the CLEVR-Change dataset. The results indicate that the context-aware difference distilling approach is an effective way to tackle the multi-change captioning problem.
However, the paper does not address some potential limitations of the approach. For example, the model may struggle with situations where the changes are more subtle or distributed across the image, rather than concentrated in a few key regions. Additionally, the reliance on the CLEVR-Change dataset, which focuses on synthetic images, raises questions about how well the model would generalize to real-world scenarios with more complex visual and linguistic challenges.
Further research could explore ways to make the CDD model more robust to these types of challenges, perhaps by incorporating additional contextual information or exploring alternative training approaches. Nonetheless, this paper represents an important step forward in the field of multi-change captioning and could have valuable applications in areas like image analysis and contrastive learning.
Conclusion
The "Context-aware Difference Distilling" (CDD) model presented in this paper is a novel approach to the problem of multi-change captioning. By selectively attending to the most relevant change regions and incorporating the surrounding visual context, CDD is able to generate more accurate and coherent natural language descriptions of the differences between two images.
This work has the potential to impact a range of applications, from image analysis and comparison to contrastive learning and change detection. While the current model has some limitations, the researchers' innovative approach to the multi-change captioning problem represents an important step forward in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Context-aware Difference Distilling for Multi-change Captioning
Yunbin Tu, Liang Li, Li Su, Zheng-Jun Zha, Chenggang Yan, Qingming Huang
Multi-change captioning aims to describe complex and coupled changes within an image pair in natural language. Compared with single-change captioning, this task requires the model to have higher-level cognition ability to reason an arbitrary number of changes. In this paper, we propose a novel context-aware difference distilling (CARD) network to capture all genuine changes for yielding sentences. Given an image pair, CARD first decouples context features that aggregate all similar/dissimilar semantics, termed common/difference context features. Then, the consistency and independence constraints are designed to guarantee the alignment/discrepancy of common/difference context features. Further, the common context features guide the model to mine locally unchanged features, which are subtracted from the pair to distill locally difference features. Next, the difference context features augment the locally difference features to ensure that all changes are distilled. In this way, we obtain an omni-representation of all changes, which is translated into linguistic sentences by a transformer decoder. Extensive experiments on three public datasets show CARD performs favourably against state-of-the-art methods.The code is available at https://github.com/tuyunbin/CARD.
Read more6/10/2024
0
Distractors-Immune Representation Learning with Cross-modal Contrastive Regularization for Change Captioning
Yunbin Tu, Liang Li, Li Su, Chenggang Yan, Qingming Huang
Change captioning aims to succinctly describe the semantic change between a pair of similar images, while being immune to distractors (illumination and viewpoint changes). Under these distractors, unchanged objects often appear pseudo changes about location and scale, and certain objects might overlap others, resulting in perturbational and discrimination-degraded features between two images. However, most existing methods directly capture the difference between them, which risk obtaining error-prone difference features. In this paper, we propose a distractors-immune representation learning network that correlates the corresponding channels of two image representations and decorrelates different ones in a self-supervised manner, thus attaining a pair of stable image representations under distractors. Then, the model can better interact them to capture the reliable difference features for caption generation. To yield words based on the most related difference features, we further design a cross-modal contrastive regularization, which regularizes the cross-modal alignment by maximizing the contrastive alignment between the attended difference features and generated words. Extensive experiments show that our method outperforms the state-of-the-art methods on four public datasets. The code is available at https://github.com/tuyunbin/DIRL.
Read more7/17/2024

0
Describing Differences in Image Sets with Natural Language
Lisa Dunlap, Yuhui Zhang, Xiaohan Wang, Ruiqi Zhong, Trevor Darrell, Jacob Steinhardt, Joseph E. Gonzalez, Serena Yeung-Levy
How do two sets of images differ? Discerning set-level differences is crucial for understanding model behaviors and analyzing datasets, yet manually sifting through thousands of images is impractical. To aid in this discovery process, we explore the task of automatically describing the differences between two $textbf{sets}$ of images, which we term Set Difference Captioning. This task takes in image sets $D_A$ and $D_B$, and outputs a description that is more often true on $D_A$ than $D_B$. We outline a two-stage approach that first proposes candidate difference descriptions from image sets and then re-ranks the candidates by checking how well they can differentiate the two sets. We introduce VisDiff, which first captions the images and prompts a language model to propose candidate descriptions, then re-ranks these descriptions using CLIP. To evaluate VisDiff, we collect VisDiffBench, a dataset with 187 paired image sets with ground truth difference descriptions. We apply VisDiff to various domains, such as comparing datasets (e.g., ImageNet vs. ImageNetV2), comparing classification models (e.g., zero-shot CLIP vs. supervised ResNet), summarizing model failure modes (supervised ResNet), characterizing differences between generative models (e.g., StableDiffusionV1 and V2), and discovering what makes images memorable. Using VisDiff, we are able to find interesting and previously unknown differences in datasets and models, demonstrating its utility in revealing nuanced insights.
Read more4/30/2024

0
OneDiff: A Generalist Model for Image Difference
Erdong Hu, Longteng Guo, Tongtian Yue, Zijia Zhao, Shuning Xue, Jing Liu
In computer vision, Image Difference Captioning (IDC) is crucial for accurately describing variations between closely related images. Traditional IDC methods often rely on specialist models, which restrict their applicability across varied contexts. This paper introduces the OneDiff model, a novel generalist approach that utilizes a robust vision-language model architecture, integrating a siamese image encoder with a Visual Delta Module. This innovative configuration allows for the precise detection and articulation of fine-grained differences between image pairs. OneDiff is trained through a dual-phase strategy, encompassing Coupled Sample Training and multi-task learning across a diverse array of data types, supported by our newly developed DiffCap Dataset. This dataset merges real-world and synthetic data, enhancing the training process and bolstering the model's robustness. Extensive testing on diverse IDC benchmarks, such as Spot-the-Diff, CLEVR-Change, and Birds-to-Words, shows that OneDiff consistently outperforms existing state-of-the-art models in accuracy and adaptability, achieving improvements of up to 85% CIDEr points in average. By setting a new benchmark in IDC, OneDiff paves the way for more versatile and effective applications in detecting and describing visual differences. The code, models, and data will be made publicly available.
Read more7/17/2024