Distributed Convolutional Neural Network Training on Mobile and Edge Clusters

0

Sign in to get full access
Overview
- Distributed training of convolutional neural networks (CNNs) on mobile and edge devices
- Aims to enable efficient distributed CNN training at the edge
- Focuses on the challenges and solutions for distributed CNN training on resource-constrained mobile and edge devices
Plain English Explanation
In this paper, the researchers explore ways to train convolutional neural networks (CNNs) on a distributed network of mobile and edge devices, rather than relying on a central cloud server. This is an important challenge because many real-world AI applications, like self-driving cars or smart home assistants, need to run on devices at the "edge" of a network, close to where data is generated, rather than in a distant cloud.
The key idea is to divide the training of the CNN model across multiple edge devices, so that the workload and memory requirements are distributed. This allows the training to happen closer to where the data is generated, reducing latency and improving efficiency. The researchers identify and address several technical hurdles to make this distributed training approach viable, such as managing communication between devices and dealing with unreliable or intermittent network connections.
By enabling efficient distributed training of CNNs at the edge, this work could pave the way for a new generation of AI-powered applications that can run locally on mobile phones, smart home hubs, self-driving car computers, and other edge devices. This could lead to faster, more responsive, and more privacy-preserving AI systems compared to cloud-based approaches.
Technical Explanation
The paper proposes a framework for distributed convolutional neural network training on mobile and edge clusters. The key contributions include:
-
Distributed CNN Training Architecture: The authors design a distributed training system that can split the workload of training a CNN model across multiple edge devices. This involves partitioning the model into sub-networks that can be trained in parallel on different devices.
-
Communication-Efficient Optimization: To address the challenge of unreliable network connections between edge devices, the researchers develop communication-efficient optimization techniques. This includes selective parameter updates and adaptive compression methods to reduce the amount of data that needs to be exchanged during training.
-
Adaptive Load Balancing: The framework dynamically adjusts the workload distribution across devices based on their available resources and connectivity, to ensure efficient utilization of the edge cluster.
-
Experimental Evaluation: The authors evaluate their approach on various CNN models and edge hardware setups. The results demonstrate significant speedups in training time and reductions in network bandwidth usage compared to centralized cloud-based training.
Critical Analysis
The paper provides a well-designed and thorough solution for distributed CNN training on mobile and edge devices. However, a few potential limitations and areas for further research are worth noting:
-
The evaluations are performed on simulated edge clusters, not real-world deployments. More testing is needed to understand the practical challenges and tradeoffs in deploying such a system in diverse real-world environments.
-
The focus is on CNN models, but the techniques could potentially be extended to other neural network architectures as well. Exploring the generalizability of the approach would be valuable.
-
The paper does not address potential privacy and security concerns that may arise when training sensitive data on distributed edge devices. Incorporating robust privacy-preserving mechanisms would be an important next step.
-
While the adaptive load balancing is a key strength, further research is needed to optimize the resource allocation and task scheduling algorithms for different hardware heterogeneities and workload patterns.
Conclusion
This paper presents a promising approach to enable efficient distributed training of convolutional neural networks on mobile and edge computing infrastructure. By overcoming the challenges of unreliable connectivity and resource constraints at the edge, the proposed framework could unlock new opportunities for deploying AI-powered applications closer to the data sources, leading to reduced latency, improved privacy, and greater efficiency. As the authors note, this work represents an important step towards a more distributed and democratized future for machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Distributed Convolutional Neural Network Training on Mobile and Edge Clusters
Pranav Rama, Madison Threadgill, Andreas Gerstlauer
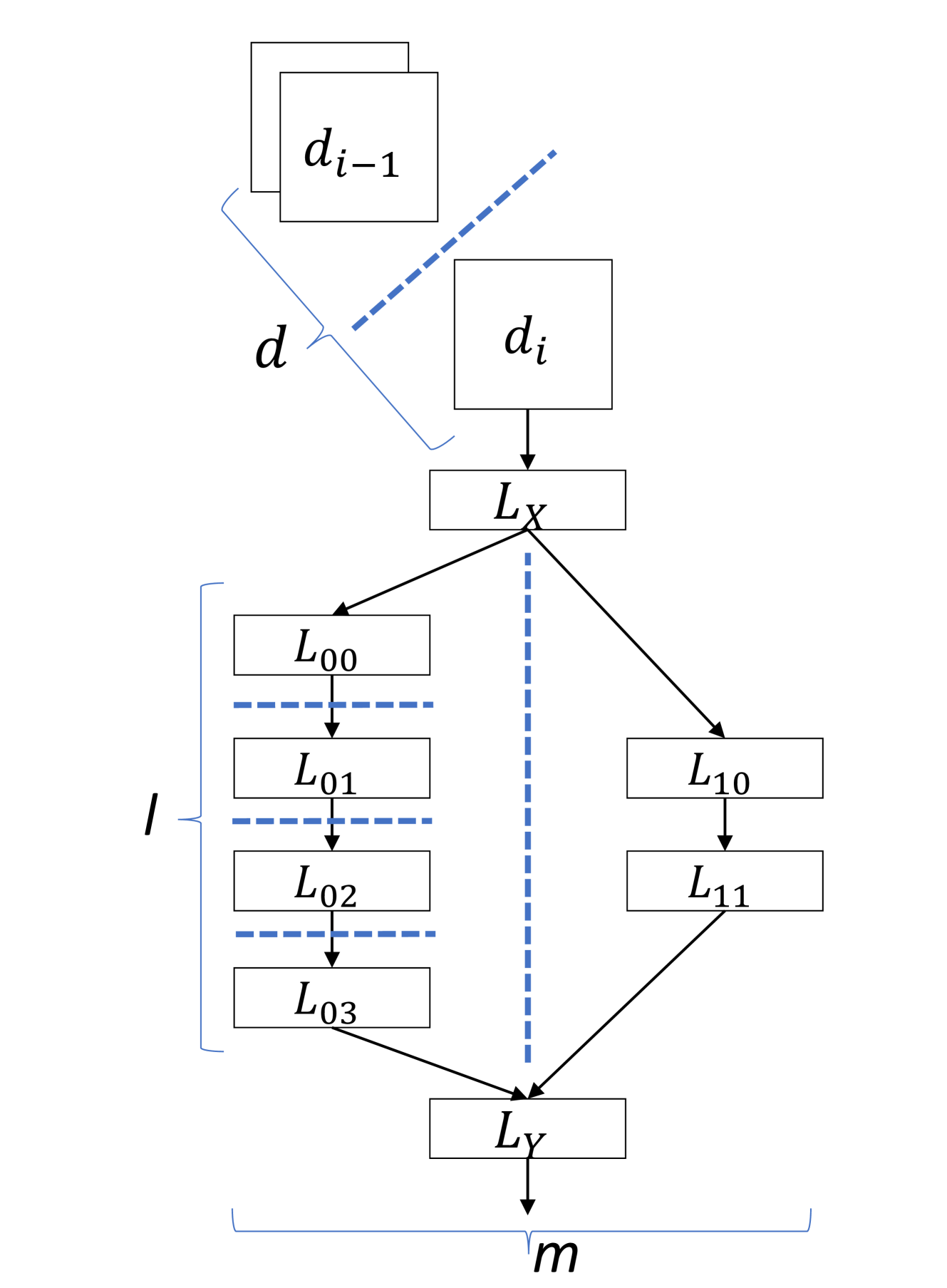
The training of deep and/or convolutional neural networks (DNNs/CNNs) is traditionally done on servers with powerful CPUs and GPUs. Recent efforts have emerged to localize machine learning tasks fully on the edge. This brings advantages in reduced latency and increased privacy, but necessitates working with resource-constrained devices. Approaches for inference and training in mobile and edge devices based on pruning, quantization or incremental and transfer learning require trading off accuracy. Several works have explored distributing inference operations on mobile and edge clusters instead. However, there is limited literature on distributed training on the edge. Existing approaches all require a central, potentially powerful edge or cloud server for coordination or offloading. In this paper, we describe an approach for distributed CNN training exclusively on mobile and edge devices. Our approach is beneficial for the initial CNN layers that are feature map dominated. It is based on partitioning forward inference and back-propagation operations among devices through tiling and fusing to maximize locality and expose communication and memory-aware parallelism. We also introduce the concept of layer grouping to further fine-tune performance based on computation and communication trade-off. Results show that for a cluster of 2-6 quad-core Raspberry Pi3 devices, training of an object-detection CNN provides a 2x-15x speedup with respect to a single core and up to 8x reduction in memory usage per device, all without sacrificing accuracy. Grouping offers up to 1.5x speedup depending on the reference profile and batch size.
Read more9/17/2024
0
A Survey of Distributed Learning in Cloud, Mobile, and Edge Settings
Madison Threadgill, Andreas Gerstlauer
In the era of deep learning (DL), convolutional neural networks (CNNs), and large language models (LLMs), machine learning (ML) models are becoming increasingly complex, demanding significant computational resources for both inference and training stages. To address this challenge, distributed learning has emerged as a crucial approach, employing parallelization across various devices and environments. This survey explores the landscape of distributed learning, encompassing cloud and edge settings. We delve into the core concepts of data and model parallelism, examining how models are partitioned across different dimensions and layers to optimize resource utilization and performance. We analyze various partitioning schemes for different layer types, including fully connected, convolutional, and recurrent layers, highlighting the trade-offs between computational efficiency, communication overhead, and memory constraints. This survey provides valuable insights for future research and development in this rapidly evolving field by comparing and contrasting distributed learning approaches across diverse contexts.
Read more5/27/2024
🤿
0
Automated Deep Neural Network Inference Partitioning for Distributed Embedded Systems
Fabian Kress, El Mahdi El Annabi, Tim Hotfilter, Julian Hoefer, Tanja Harbaum, Juergen Becker
Distributed systems can be found in various applications, e.g., in robotics or autonomous driving, to achieve higher flexibility and robustness. Thereby, data flow centric applications such as Deep Neural Network (DNN) inference benefit from partitioning the workload over multiple compute nodes in terms of performance and energy-efficiency. However, mapping large models on distributed embedded systems is a complex task, due to low latency and high throughput requirements combined with strict energy and memory constraints. In this paper, we present a novel approach for hardware-aware layer scheduling of DNN inference in distributed embedded systems. Therefore, our proposed framework uses a graph-based algorithm to automatically find beneficial partitioning points in a given DNN. Each of these is evaluated based on several essential system metrics such as accuracy and memory utilization, while considering the respective system constraints. We demonstrate our approach in terms of the impact of inference partitioning on various performance metrics of six different DNNs. As an example, we can achieve a 47.5 % throughput increase for EfficientNet-B0 inference partitioned onto two platforms while observing high energy-efficiency.
Read more7/1/2024
🤯
0
Embedded Distributed Inference of Deep Neural Networks: A Systematic Review
Federico Nicol'as Peccia, Oliver Bringmann
Embedded distributed inference of Neural Networks has emerged as a promising approach for deploying machine-learning models on resource-constrained devices in an efficient and scalable manner. The inference task is distributed across a network of embedded devices, with each device contributing to the overall computation by performing a portion of the workload. In some cases, more powerful devices such as edge or cloud servers can be part of the system to be responsible of the most demanding layers of the network. As the demand for intelligent systems and the complexity of the deployed neural network models increases, this approach is becoming more relevant in a variety of applications such as robotics, autonomous vehicles, smart cities, Industry 4.0 and smart health. We present a systematic review of papers published during the last six years which describe techniques and methods to distribute Neural Networks across these kind of systems. We provide an overview of the current state-of-the-art by analysing more than 100 papers, present a new taxonomy to characterize them, and discuss trends and challenges in the field.
Read more5/7/2024