Distribution-Aware Continual Test-Time Adaptation for Semantic Segmentation

0

Sign in to get full access
Introduction
Related Work

Method
V Experiments
Conclusion
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Distribution-Aware Continual Test-Time Adaptation for Semantic Segmentation
Jiayi Ni, Senqiao Yang, Ran Xu, Jiaming Liu, Xiaoqi Li, Wenyu Jiao, Zehui Chen, Yi Liu, Shanghang Zhang
Since autonomous driving systems usually face dynamic and ever-changing environments, continual test-time adaptation (CTTA) has been proposed as a strategy for transferring deployed models to continually changing target domains. However, the pursuit of long-term adaptation often introduces catastrophic forgetting and error accumulation problems, which impede the practical implementation of CTTA in the real world. Recently, existing CTTA methods mainly focus on utilizing a majority of parameters to fit target domain knowledge through self-training. Unfortunately, these approaches often amplify the challenge of error accumulation due to noisy pseudo-labels, and pose practical limitations stemming from the heavy computational costs associated with entire model updates. In this paper, we propose a distribution-aware tuning (DAT) method to make the semantic segmentation CTTA efficient and practical in real-world applications. DAT adaptively selects and updates two small groups of trainable parameters based on data distribution during the continual adaptation process, including domain-specific parameters (DSP) and task-relevant parameters (TRP). Specifically, DSP exhibits sensitivity to outputs with substantial distribution shifts, effectively mitigating the problem of error accumulation. In contrast, TRP are allocated to positions that are responsive to outputs with minor distribution shifts, which are fine-tuned to avoid the catastrophic forgetting problem. In addition, since CTTA is a temporal task, we introduce the Parameter Accumulation Update (PAU) strategy to collect the updated DSP and TRP in target domain sequences. We conduct extensive experiments on two widely-used semantic segmentation CTTA benchmarks, achieving promising performance compared to previous state-of-the-art methods.
Read more4/1/2024

0
New!Hybrid-TTA: Continual Test-time Adaptation via Dynamic Domain Shift Detection
Hyewon Park, Hyejin Park, Jueun Ko, Dongbo Min
Continual Test Time Adaptation (CTTA) has emerged as a critical approach for bridging the domain gap between the controlled training environments and the real-world scenarios, enhancing model adaptability and robustness. Existing CTTA methods, typically categorized into Full-Tuning (FT) and Efficient-Tuning (ET), struggle with effectively addressing domain shifts. To overcome these challenges, we propose Hybrid-TTA, a holistic approach that dynamically selects instance-wise tuning method for optimal adaptation. Our approach introduces the Dynamic Domain Shift Detection (DDSD) strategy, which identifies domain shifts by leveraging temporal correlations in input sequences and dynamically switches between FT and ET to adapt to varying domain shifts effectively. Additionally, the Masked Image Modeling based Adaptation (MIMA) framework is integrated to ensure domain-agnostic robustness with minimal computational overhead. Our Hybrid-TTA achieves a notable 1.6%p improvement in mIoU on the Cityscapes-to-ACDC benchmark dataset, surpassing previous state-of-the-art methods and offering a robust solution for real-world continual adaptation challenges.
Read more9/16/2024

0
Reshaping the Online Data Buffering and Organizing Mechanism for Continual Test-Time Adaptation
Zhilin Zhu, Xiaopeng Hong, Zhiheng Ma, Weijun Zhuang, Yaohui Ma, Yong Dai, Yaowei Wang
Continual Test-Time Adaptation (CTTA) involves adapting a pre-trained source model to continually changing unsupervised target domains. In this paper, we systematically analyze the challenges of this task: online environment, unsupervised nature, and the risks of error accumulation and catastrophic forgetting under continual domain shifts. To address these challenges, we reshape the online data buffering and organizing mechanism for CTTA. We propose an uncertainty-aware buffering approach to identify and aggregate significant samples with high certainty from the unsupervised, single-pass data stream. Based on this, we propose a graph-based class relation preservation constraint to overcome catastrophic forgetting. Furthermore, a pseudo-target replay objective is used to mitigate error accumulation. Extensive experiments demonstrate the superiority of our method in both segmentation and classification CTTA tasks. Code is available at https://github.com/z1358/OBAO.
Read more7/19/2024
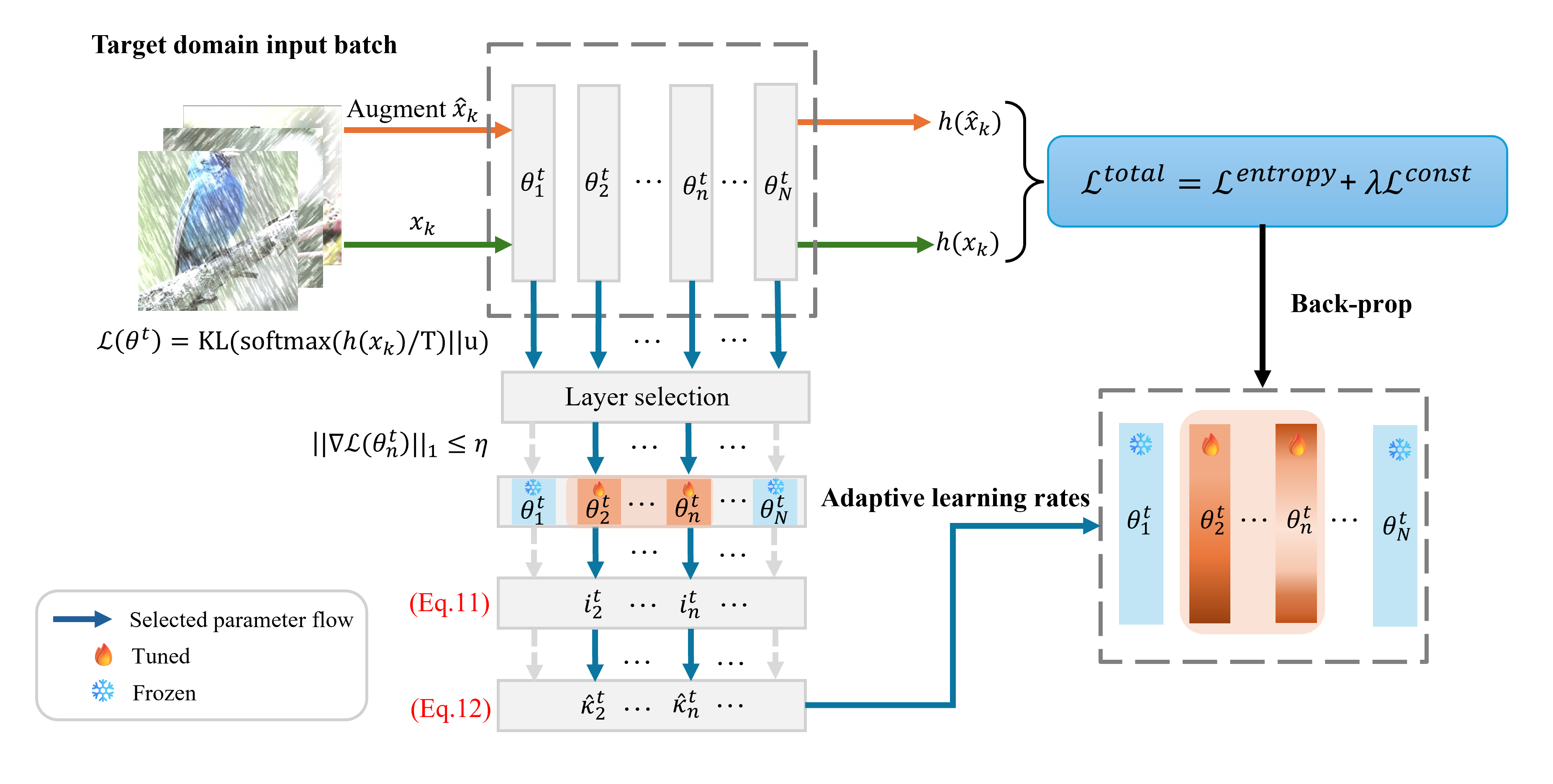
0
PALM: Pushing Adaptive Learning Rate Mechanisms for Continual Test-Time Adaptation
Sarthak Kumar Maharana, Baoming Zhang, Yunhui Guo
Real-world vision models in dynamic environments face rapid shifts in domain distributions, leading to decreased recognition performance. Using unlabeled test data, continual test-time adaptation (CTTA) directly adjusts a pre-trained source discriminative model to these changing domains. A highly effective CTTA method involves applying layer-wise adaptive learning rates for selectively adapting pre-trained layers. However, it suffers from the poor estimation of domain shift and the inaccuracies arising from the pseudo-labels. This work aims to overcome these limitations by identifying layers for adaptation via quantifying model prediction uncertainty without relying on pseudo-labels. We utilize the magnitude of gradients as a metric, calculated by backpropagating the KL divergence between the softmax output and a uniform distribution, to select layers for further adaptation. Subsequently, for the parameters exclusively belonging to these selected layers, with the remaining ones frozen, we evaluate their sensitivity to approximate the domain shift and adjust their learning rates accordingly. We conduct extensive image classification experiments on CIFAR-10C, CIFAR-100C, and ImageNet-C, demonstrating the superior efficacy of our method compared to prior approaches.
Read more8/27/2024