Reshaping the Online Data Buffering and Organizing Mechanism for Continual Test-Time Adaptation

0

Sign in to get full access
Overview
- This paper proposes a novel approach to continual test-time adaptation, which aims to enable models to continuously learn and adapt to new data during the test phase without experiencing catastrophic forgetting.
- The authors introduce an online data buffering and organizing mechanism that effectively stores and retrieves relevant data samples to facilitate continual learning at test time.
- The proposed method outperforms existing continual test-time adaptation techniques on various benchmark datasets and tasks, demonstrating its effectiveness in addressing the challenges of continual learning.
Plain English Explanation
Continual learning is the ability of an AI model to continuously learn and adapt to new information, even as it's being used to make predictions. This is important because the real world is constantly changing, and we want our AI models to be able to keep up.
The key challenge in continual learning is called "catastrophic forgetting", where a model forgets what it has previously learned when it tries to learn new things. This paper presents a new way to address this problem, specifically for the test-time adaptation setting.
The paper introduces a mechanism for storing and organizing data samples that the model sees during the test phase. This allows the model to continually learn from this data, without forgetting what it had learned before. The authors show that their approach outperforms existing continual test-time adaptation techniques, making the model more robust and adaptable to changing conditions.
By solving the problem of catastrophic forgetting, this research helps pave the way for AI models that can continuously learn and improve over time, just like humans do. This could lead to more intelligent and capable AI systems that can better handle the complexity and dynamism of the real world.
Technical Explanation
The paper proposes a novel approach to continual test-time adaptation, which aims to enable models to continuously learn and adapt to new data during the test phase without experiencing catastrophic forgetting. The authors introduce an online data buffering and organizing mechanism that effectively stores and retrieves relevant data samples to facilitate continual learning at test time.
The key idea is to maintain a buffer of data samples encountered during the test phase and continuously update the model's parameters using these samples. To avoid catastrophic forgetting, the authors propose a data organization strategy that groups samples based on their similarity, allowing the model to selectively update its parameters based on the most relevant data.
The proposed method is evaluated on various benchmark datasets and tasks, including object detection, semantic segmentation, and domain adaptation. The results demonstrate that the introduced approach outperforms existing continual test-time adaptation techniques, highlighting its effectiveness in addressing the challenges of continual learning.
Critical Analysis
The paper presents a promising approach to continual test-time adaptation, but it also acknowledges several limitations and areas for further research. One key limitation is the reliance on a fixed-size buffer, which may not be scalable to large-scale or long-term deployment scenarios. The authors suggest exploring more efficient buffer management strategies, such as RDUMB, to address this issue.
Additionally, the paper focuses on single-task continual learning, and it would be valuable to investigate the performance of the proposed method in more complex, multi-task settings. Furthermore, the authors note that the impact of the data organization strategy on the model's adaptation capabilities warrants further exploration.
Overall, the research presented in this paper represents a significant step forward in the field of continual test-time adaptation, but there are still challenges and opportunities for future work to make these systems more robust, scalable, and capable of handling the full complexity of real-world applications.
Conclusion
This paper introduces a novel approach to continual test-time adaptation that addresses the critical challenge of catastrophic forgetting. By leveraging an online data buffering and organizing mechanism, the proposed method enables AI models to continuously learn and adapt to new data during the test phase, outperforming existing techniques on various benchmarks.
The research highlights the importance of continual learning in the real world, where the data and environment are constantly evolving. By solving the problem of catastrophic forgetting, this work paves the way for the development of more intelligent and adaptable AI systems that can keep up with the changing needs of users and applications. As the field of continual learning continues to advance, the insights and techniques presented in this paper will likely play a crucial role in driving further progress and bringing us closer to truly robust and versatile AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reshaping the Online Data Buffering and Organizing Mechanism for Continual Test-Time Adaptation
Zhilin Zhu, Xiaopeng Hong, Zhiheng Ma, Weijun Zhuang, Yaohui Ma, Yong Dai, Yaowei Wang
Continual Test-Time Adaptation (CTTA) involves adapting a pre-trained source model to continually changing unsupervised target domains. In this paper, we systematically analyze the challenges of this task: online environment, unsupervised nature, and the risks of error accumulation and catastrophic forgetting under continual domain shifts. To address these challenges, we reshape the online data buffering and organizing mechanism for CTTA. We propose an uncertainty-aware buffering approach to identify and aggregate significant samples with high certainty from the unsupervised, single-pass data stream. Based on this, we propose a graph-based class relation preservation constraint to overcome catastrophic forgetting. Furthermore, a pseudo-target replay objective is used to mitigate error accumulation. Extensive experiments demonstrate the superiority of our method in both segmentation and classification CTTA tasks. Code is available at https://github.com/z1358/OBAO.
Read more7/19/2024
➖
0
Controllable Continual Test-Time Adaptation
Ziqi Shi, Fan Lyu, Ye Liu, Fanhua Shang, Fuyuan Hu, Wei Feng, Zhang Zhang, Liang Wang
Continual Test-Time Adaptation (CTTA) is an emerging and challenging task where a model trained in a source domain must adapt to continuously changing conditions during testing, without access to the original source data. CTTA is prone to error accumulation due to uncontrollable domain shifts, leading to blurred decision boundaries between categories. Existing CTTA methods primarily focus on suppressing domain shifts, which proves inadequate during the unsupervised test phase. In contrast, we introduce a novel approach that guides rather than suppresses these shifts. Specifically, we propose $textbf{C}$ontrollable $textbf{Co}$ntinual $textbf{T}$est-$textbf{T}$ime $textbf{A}$daptation (C-CoTTA), which explicitly prevents any single category from encroaching on others, thereby mitigating the mutual influence between categories caused by uncontrollable shifts. Moreover, our method reduces the sensitivity of model to domain transformations, thereby minimizing the magnitude of category shifts. Extensive quantitative experiments demonstrate the effectiveness of our method, while qualitative analyses, such as t-SNE plots, confirm the theoretical validity of our approach.
Read more5/29/2024
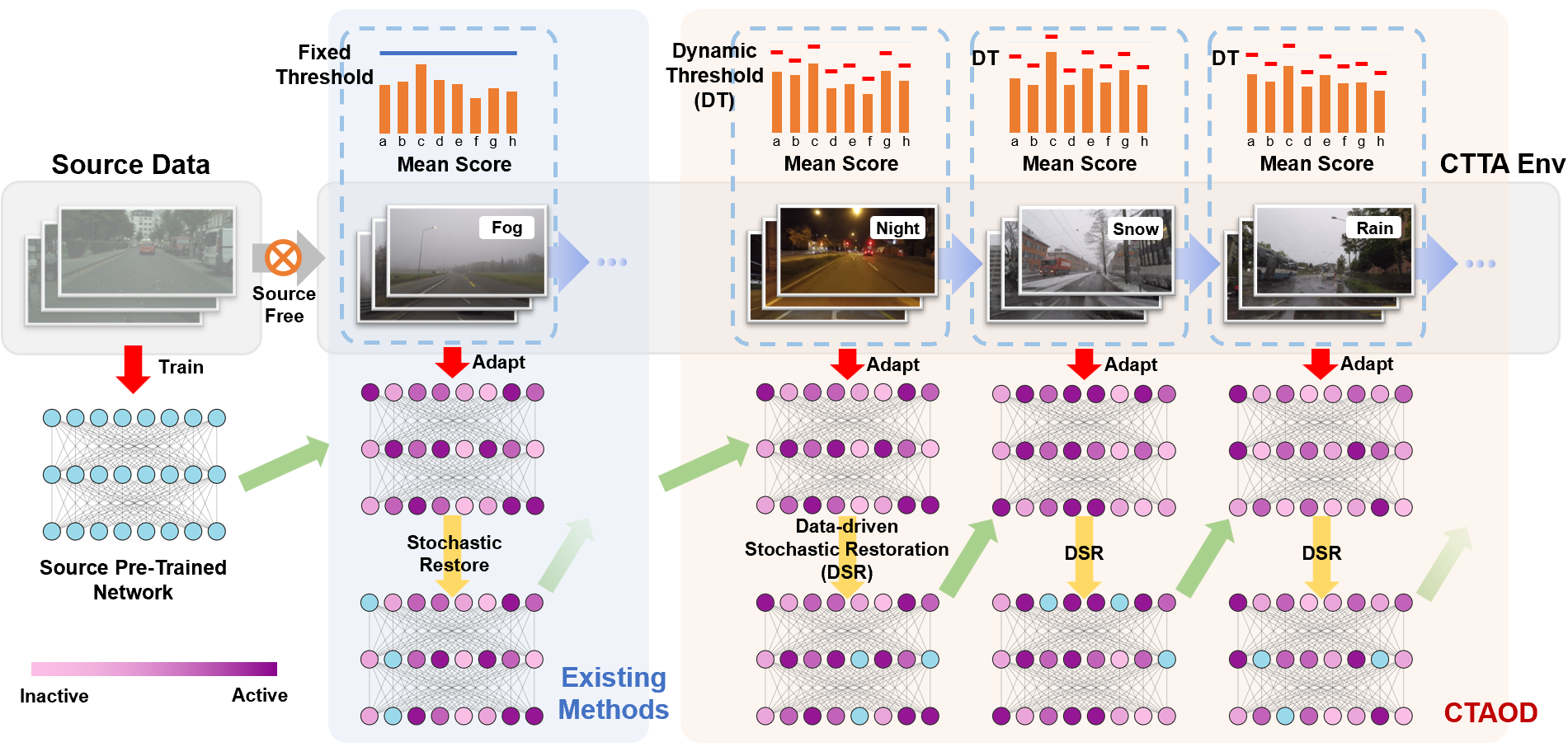
0
Exploring Test-Time Adaptation for Object Detection in Continually Changing Environments
Shilei Cao, Yan Liu, Juepeng Zheng, Weijia Li, Runmin Dong, Haohuan Fu
Real-world application models are commonly deployed in dynamic environments, where the target domain distribution undergoes temporal changes. Continual Test-Time Adaptation (CTTA) has recently emerged as a promising technique to gradually adapt a source-trained model to continually changing target domains. Despite recent advancements in addressing CTTA, two critical issues remain: 1) Fixed thresholds for pseudo-labeling in existing methodologies generate low-quality pseudo-labels, as model confidence varies across categories and domains; 2) Stochastic parameter restoration methods for mitigating catastrophic forgetting fail to effectively preserve critical information due to their intrinsic randomness. To tackle these challenges for detection models in CTTA scenarios, we present CTAOD, featuring three core components. Firstly, the object-level contrastive learning module extracts object-level features for contrastive learning to refine the feature representation in the target domain. Secondly, the adaptive monitoring module dynamically skips unnecessary adaptation and updates the category-specific threshold based on predicted confidence scores to enable efficiency and improve the quality of pseudo-labels. Lastly, the data-driven stochastic restoration mechanism selectively reset inactive parameters with higher possibilities, ensuring the retention of essential knowledge. We demonstrate the effectiveness of CTAOD on four CTTA object detection tasks, where CTAOD outperforms existing methods, especially achieving a 3.2 mAP improvement and a 20% increase in efficiency on the Cityscapes-to-Cityscapes-C CTTA task. The code will be released.
Read more8/20/2024

0
New!Hybrid-TTA: Continual Test-time Adaptation via Dynamic Domain Shift Detection
Hyewon Park, Hyejin Park, Jueun Ko, Dongbo Min
Continual Test Time Adaptation (CTTA) has emerged as a critical approach for bridging the domain gap between the controlled training environments and the real-world scenarios, enhancing model adaptability and robustness. Existing CTTA methods, typically categorized into Full-Tuning (FT) and Efficient-Tuning (ET), struggle with effectively addressing domain shifts. To overcome these challenges, we propose Hybrid-TTA, a holistic approach that dynamically selects instance-wise tuning method for optimal adaptation. Our approach introduces the Dynamic Domain Shift Detection (DDSD) strategy, which identifies domain shifts by leveraging temporal correlations in input sequences and dynamically switches between FT and ET to adapt to varying domain shifts effectively. Additionally, the Masked Image Modeling based Adaptation (MIMA) framework is integrated to ensure domain-agnostic robustness with minimal computational overhead. Our Hybrid-TTA achieves a notable 1.6%p improvement in mIoU on the Cityscapes-to-ACDC benchmark dataset, surpassing previous state-of-the-art methods and offering a robust solution for real-world continual adaptation challenges.
Read more9/16/2024