Distributional Refinement Network: Distributional Forecasting via Deep Learning

0
🤿
Sign in to get full access
Overview
- Actuarial modeling involves modeling the distribution of losses
- Existing methods like Generalized Linear Models (GLMs) have challenges in:
- Allowing covariates to flexibly impact different aspects of the conditional distribution
- Integrating developments in machine learning and AI to maximize predictive power
- Maintaining interpretability to enhance trust in the model
- The paper proposes a Distributional Refinement Network (DRN) to address these challenges
Plain English Explanation
Actuaries, who are responsible for assessing and managing risk, often need to model the distribution of losses or costs. A classic approach is to use Generalized Linear Models (GLMs). However, GLMs have some limitations. They may not be able to fully capture how different factors (or "covariates") can flexibly influence different aspects of the distribution of losses. Additionally, advancements in machine learning and AI could potentially improve the predictive power of these models, but integrating these developments while maintaining interpretability (so users can understand how the model works) is a challenge.
To address these issues, the researchers in this paper propose a new model called the Distributional Refinement Network (DRN). The DRN combines an interpretable baseline model (like a GLM) with a more flexible neural network component. This approach is inspired by the Combined Actuarial Neural Network (CANN). The neural network part of the DRN allows the model to capture more complex relationships between the factors and the distribution of losses, while the baseline model helps maintain interpretability.
The key advantage of the DRN is that it can flexibly model how the different factors influence the entire distribution of losses, not just the average or "mean" value. This can lead to improved predictive performance compared to existing methods. The researchers demonstrate the DRN's capabilities using both synthetic (computer-generated) data and real-world insurance data.
Technical Explanation
The paper proposes a Distributional Refinement Network (DRN) to address the limitations of existing distributional regression models like Generalized Linear Models (GLMs) in actuarial modeling. The DRN combines an interpretable baseline model (such as a GLM) with a flexible neural network component, inspired by the Combined Actuarial Neural Network (CANN).
The key features of the DRN are:
-
Flexible Covariate Effects: The neural network component of the DRN allows covariates to flexibly influence different aspects of the conditional distribution, going beyond the limitations of GLMs.
-
Predictive Power: By integrating advancements in machine learning and AI, the DRN can improve predictive performance compared to traditional methods.
-
Interpretability: The baseline interpretable model (e.g., GLM) helps maintain a level of interpretability in the overall DRN model, addressing the common trade-off between flexibility and interpretability.
The researchers evaluate the DRN using both synthetic and real-world insurance data, demonstrating its superior distributional forecasting capacity compared to existing methods. The DRN has the potential to be a powerful distributional regression model in actuarial science and beyond.
Critical Analysis
The paper presents a promising approach to addressing the challenges in actuarial modeling, but there are a few important considerations:
-
Interpretability Limitations: While the DRN aims to maintain interpretability, the inclusion of a neural network component may still limit the model's transparency, especially as the complexity of the problem and the number of variables increases. Further research is needed to explore ways to enhance the interpretability of such hybrid models.
-
Data Requirements: The DRN, like other machine learning-based models, may require large, high-quality datasets to achieve its full potential. The availability and quality of data in actuarial applications could be a constraint.
-
Computational Complexity: The training and deployment of the DRN may be more computationally intensive compared to simpler models like GLMs, which could be a consideration for real-world implementation.
-
Regulatory Concerns: In the actuarial domain, regulatory bodies often require a high degree of model interpretability and transparency. The industry may need to evolve its practices to accommodate more complex, yet powerful, models like the DRN.
Conclusion
The paper introduces the Distributional Refinement Network (DRN), a novel approach to distributional regression modeling that combines an interpretable baseline model with a flexible neural network component. The DRN addresses key challenges in actuarial modeling, such as allowing covariates to flexibly impact the entire conditional distribution, integrating advancements in machine learning and AI, and maintaining interpretability.
The researchers demonstrate the DRN's superior distributional forecasting capabilities using both synthetic and real-world data. The DRN has the potential to be a powerful tool in actuarial science and other fields that require accurate and interpretable distributional modeling.
While the DRN represents a significant step forward, there are still some limitations and practical considerations that need to be addressed, such as interpretability, data requirements, and computational complexity. As the field of actuarial modeling continues to evolve, innovative approaches like the DRN will play an increasingly important role in managing risk and uncertainty.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Distributional Refinement Network: Distributional Forecasting via Deep Learning
Benjamin Avanzi, Eric Dong, Patrick J. Laub, Bernard Wong
A key task in actuarial modelling involves modelling the distributional properties of losses. Classic (distributional) regression approaches like Generalized Linear Models (GLMs; Nelder and Wedderburn, 1972) are commonly used, but challenges remain in developing models that can (i) allow covariates to flexibly impact different aspects of the conditional distribution, (ii) integrate developments in machine learning and AI to maximise the predictive power while considering (i), and, (iii) maintain a level of interpretability in the model to enhance trust in the model and its outputs, which is often compromised in efforts pursuing (i) and (ii). We tackle this problem by proposing a Distributional Refinement Network (DRN), which combines an inherently interpretable baseline model (such as GLMs) with a flexible neural network-a modified Deep Distribution Regression (DDR; Li et al., 2019) method. Inspired by the Combined Actuarial Neural Network (CANN; Schelldorfer and W{''u}thrich, 2019), our approach flexibly refines the entire baseline distribution. As a result, the DRN captures varying effects of features across all quantiles, improving predictive performance while maintaining adequate interpretability. Using both synthetic and real-world data, we demonstrate the DRN's superior distributional forecasting capacity. The DRN has the potential to be a powerful distributional regression model in actuarial science and beyond.
Read more6/4/2024

0
How Inverse Conditional Flows Can Serve as a Substitute for Distributional Regression
Lucas Kook, Chris Kolb, Philipp Schiele, Daniel Dold, Marcel Arpogaus, Cornelius Fritz, Philipp F. Baumann, Philipp Kopper, Tobias Pielok, Emilio Dorigatti, David Rugamer
Neural network representations of simple models, such as linear regression, are being studied increasingly to better understand the underlying principles of deep learning algorithms. However, neural representations of distributional regression models, such as the Cox model, have received little attention so far. We close this gap by proposing a framework for distributional regression using inverse flow transformations (DRIFT), which includes neural representations of the aforementioned models. We empirically demonstrate that the neural representations of models in DRIFT can serve as a substitute for their classical statistical counterparts in several applications involving continuous, ordered, time-series, and survival outcomes. We confirm that models in DRIFT empirically match the performance of several statistical methods in terms of estimation of partial effects, prediction, and aleatoric uncertainty quantification. DRIFT covers both interpretable statistical models and flexible neural networks opening up new avenues in both statistical modeling and deep learning.
Read more7/11/2024
0
General Distribution Learning: A theoretical framework for Deep Learning
Binchuan Qi
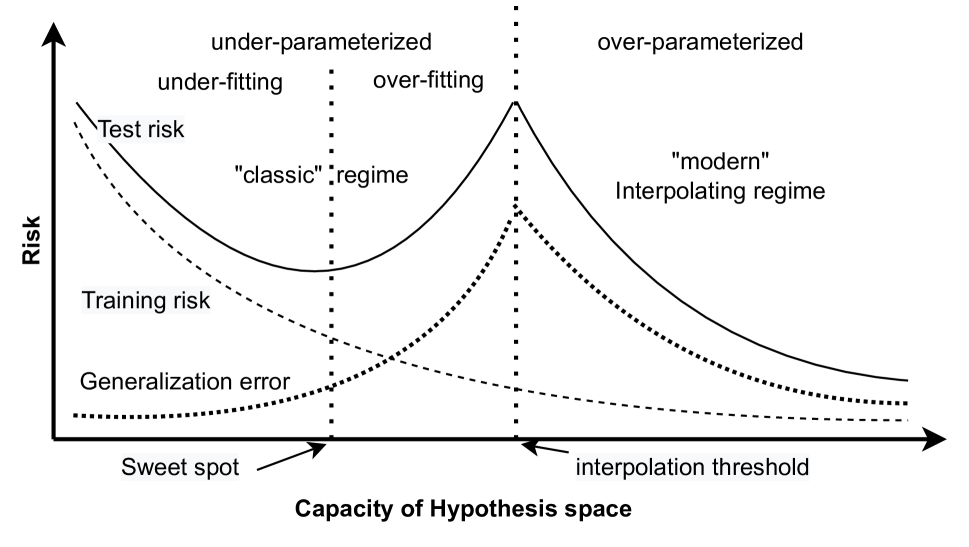
This paper introduces General Distribution Learning (GD learning), a novel theoretical learning framework designed to address a comprehensive range of machine learning and statistical tasks, including classification, regression, and parameter estimation. GD learning focuses on estimating the true underlying probability distribution of dataset and using models to fit the estimated parameters of the distribution. The learning error in GD learning is thus decomposed into two distinct categories: estimation error and fitting error. The estimation error, which stems from the constraints of finite sampling, limited prior knowledge, and the estimation algorithm's inherent limitations, quantifies the discrepancy between the true distribution and its estimate. The fitting error can be attributed to model's capacity limitation and the performance limitation of the optimization algorithm, which evaluates the deviation of the model output from the fitted objective. To address the challenge of non-convexity in the optimization of learning error, we introduce the standard loss function and demonstrate that, when employing this function, global optimal solutions in non-convex optimization can be approached by minimizing the gradient norm and the structural error. Moreover, we demonstrate that the estimation error is determined by the uncertainty of the estimate $q$, and propose the minimum uncertainty principle to obtain an optimal estimate of the true distribution. We further provide upper bounds for the estimation error, fitting error, and learning error within the GD learning framework. Ultimately, our findings are applied to offer theoretical explanations for several unanswered questions on deep learning, including overparameterization, non-convex optimization, flat minima, dynamic isometry condition and other techniques in deep learning.
Read more7/19/2024

0
Exploration and Anti-Exploration with Distributional Random Network Distillation
Kai Yang, Jian Tao, Jiafei Lyu, Xiu Li
Exploration remains a critical issue in deep reinforcement learning for an agent to attain high returns in unknown environments. Although the prevailing exploration Random Network Distillation (RND) algorithm has been demonstrated to be effective in numerous environments, it often needs more discriminative power in bonus allocation. This paper highlights the bonus inconsistency issue within RND, pinpointing its primary limitation. To address this issue, we introduce the Distributional RND (DRND), a derivative of the RND. DRND enhances the exploration process by distilling a distribution of random networks and implicitly incorporating pseudo counts to improve the precision of bonus allocation. This refinement encourages agents to engage in more extensive exploration. Our method effectively mitigates the inconsistency issue without introducing significant computational overhead. Both theoretical analysis and experimental results demonstrate the superiority of our approach over the original RND algorithm. Our method excels in challenging online exploration scenarios and effectively serves as an anti-exploration mechanism in D4RL offline tasks. Our code is publicly available at https://github.com/yk7333/DRND.
Read more5/21/2024