General Distribution Learning: A theoretical framework for Deep Learning
2406.05666
0
0
Abstract
There remain numerous unanswered research questions on deep learning (DL) within the classical learning theory framework. These include the remarkable generalization capabilities of overparametrized neural networks (NNs), the efficient optimization performance despite non-convexity of objectives, the mechanism of flat minima for generalization, and the exceptional performance of deep architectures in solving physical problems. This paper introduces General Distribution Learning (GD Learning), a novel theoretical learning framework designed to address a comprehensive range of machine learning and statistical tasks, including classification, regression and parameter estimation. Departing from traditional statistical machine learning, GD Learning focuses on the true underlying distribution. In GD Learning, learning error, corresponding to the expected error in classical statistical learning framework, is divided into fitting errors due to models and algorithms, as well as sampling errors introduced by limited sampling data. The framework significantly incorporates prior knowledge, especially in scenarios characterized by data scarcity, thereby enhancing performance. Within the GD Learning framework, we demonstrate that the global optimal solutions in non-convex optimization can be approached by minimizing the gradient norm and the non-uniformity of the eigenvalues of the model's Jacobian matrix. This insight leads to the development of the gradient structure control algorithm. GD Learning also offers fresh insights into the questions on deep learning, including overparameterization and non-convex optimization, bias-variance trade-off, and the mechanism of flat minima.
Create account to get full access
Overview
- This paper presents a theoretical framework called "General Distribution Learning" (GDL) for understanding deep learning models.
- The framework aims to provide a unified view of deep learning that encompasses various learning paradigms, including supervised, unsupervised, and reinforcement learning.
- GDL proposes that deep learning models learn to approximate the general distribution of data, which can then be used for various tasks like classification, generation, and decision-making.
Plain English Explanation
The paper introduces a new theoretical framework called "General Distribution Learning" (GDL) that aims to provide a comprehensive understanding of how deep learning models work. Deep learning has become a powerful tool for solving a wide range of problems, from image recognition to natural language processing. However, the inner workings of these models can be complex and difficult to fully explain.
The GDL framework suggests that deep learning models don't just learn to perform specific tasks, like classifying images or generating text. Instead, they learn to approximate the "general distribution" of the data they're trained on. This means they develop an understanding of the underlying patterns and relationships in the data, which can then be applied to a variety of different tasks.
For example, a deep learning model trained on images of different objects might learn the general distribution of visual features, such as shapes, textures, and colors. This understanding can then be used to classify new images, generate new images, or even make decisions about the objects in the images.
The key idea behind GDL is that by learning the general distribution of the data, deep learning models can be more flexible and adaptable, able to tackle a wide range of problems without having to be specifically trained for each one. This could lead to more efficient and versatile AI systems in the future.
Technical Explanation
The paper proposes a theoretical framework called "General Distribution Learning" (GDL) to provide a unified view of deep learning. The core idea of GDL is that deep learning models learn to approximate the general distribution of the data they are trained on, rather than just memorizing specific inputs and outputs.
The authors argue that this general distribution learning can encompass a variety of learning paradigms, including supervised, unsupervised, and reinforcement learning. By learning the underlying patterns and relationships in the data, deep learning models can then be applied to a wide range of tasks, such as classification, generation, and decision-making.
The paper presents a formal mathematical formulation of GDL, which defines the objective function and constraints for a deep learning model to learn the general distribution. The authors show that this framework can be applied to different learning scenarios, including supervised learning, unsupervised learning, and reinforcement learning.
Furthermore, the paper explores the relationship between GDL and other theoretical frameworks, such as Towards a Theory of Out-of-Distribution Learning, Domain Generalization through Meta-Learning: A Survey, and Error Bounds for Supervised Classification from Information Theoretic Principles. The authors discuss how GDL can provide a unifying perspective on these related theories and how they can inform the development of more robust and versatile deep learning models.
Critical Analysis
The GDL framework presented in this paper is a valuable contribution to the theoretical understanding of deep learning. By proposing that deep learning models learn the general distribution of data, rather than just memorizing specific inputs and outputs, the authors offer a fresh perspective on how these models operate and how they can be applied to a wide range of problems.
One potential limitation of the GDL framework is that it may not fully capture the complexities of real-world data and the challenges faced by deep learning models in practice. The paper focuses on a theoretical formulation, and it remains to be seen how well the GDL principles translate to more complex, noisy, or high-dimensional datasets.
Additionally, the paper does not delve deeply into the practical implications of GDL for the design and training of deep learning models. While the authors discuss the relationship between GDL and other theoretical frameworks, more work may be needed to translate these ideas into practical guidelines for model development and deployment.
Nonetheless, the GDL framework opens up new avenues for research and exploration in the field of deep learning. By providing a unified perspective on different learning paradigms, the framework could inspire the development of more versatile and adaptable AI systems that can tackle a broader range of problems. As the authors mention, future directions for the theory of graph machine learning could also benefit from the insights presented in this paper.
Conclusion
The "General Distribution Learning" (GDL) framework proposed in this paper offers a novel theoretical perspective on how deep learning models operate. By suggesting that these models learn to approximate the general distribution of data, rather than just memorize specific inputs and outputs, the authors provide a unified view of various learning paradigms, including supervised, unsupervised, and reinforcement learning.
The GDL framework has the potential to inform the development of more versatile and adaptable AI systems that can tackle a broader range of problems. While the paper focuses on the theoretical aspects, the ideas presented could lead to practical guidelines for designing and training deep learning models that better capture the underlying patterns and relationships in complex, real-world data.
As the field of deep learning continues to evolve, the GDL framework and its connections to related theories, such as out-of-distribution learning and domain generalization, could provide valuable insights and guide future research directions in the quest for more robust and capable artificial intelligence systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
Towards a theory of out-of-distribution learning
Jayanta Dey, Ali Geisa, Ronak Mehta, Tyler M. Tomita, Hayden S. Helm, Haoyin Xu, Eric Eaton, Jeffery Dick, Carey E. Priebe, Joshua T. Vogelstein
0
0
Learning is a process wherein a learning agent enhances its performance through exposure of experience or data. Throughout this journey, the agent may encounter diverse learning environments. For example, data may be presented to the leaner all at once, in multiple batches, or sequentially. Furthermore, the distribution of each data sample could be either identical and independent (iid) or non-iid. Additionally, there may exist computational and space constraints for the deployment of the learning algorithms. The complexity of a learning task can vary significantly, depending on the learning setup and the constraints imposed upon it. However, it is worth noting that the current literature lacks formal definitions for many of the in-distribution and out-of-distribution learning paradigms. Establishing proper and universally agreed-upon definitions for these learning setups is essential for thoroughly exploring the evolution of ideas across different learning scenarios and deriving generalized mathematical bounds for these learners. In this paper, we aim to address this issue by proposing a chronological approach to defining different learning tasks using the provably approximately correct (PAC) learning framework. We will start with in-distribution learning and progress to recently proposed lifelong or continual learning. We employ consistent terminology and notation to demonstrate how each of these learning frameworks represents a specific instance of a broader, more generalized concept of learnability. Our hope is that this work will inspire a universally agreed-upon approach to quantifying different types of learning, fostering greater understanding and progress in the field.
6/10/2024

Domain Generalization through Meta-Learning: A Survey
Arsham Gholamzadeh Khoee, Yinan Yu, Robert Feldt
0
0
Deep neural networks (DNNs) have revolutionized artificial intelligence but often lack performance when faced with out-of-distribution (OOD) data, a common scenario due to the inevitable domain shifts in real-world applications. This limitation stems from the common assumption that training and testing data share the same distribution-an assumption frequently violated in practice. Despite their effectiveness with large amounts of data and computational power, DNNs struggle with distributional shifts and limited labeled data, leading to overfitting and poor generalization across various tasks and domains. Meta-learning presents a promising approach by employing algorithms that acquire transferable knowledge across various tasks for fast adaptation, eliminating the need to learn each task from scratch. This survey paper delves into the realm of meta-learning with a focus on its contribution to domain generalization. We first clarify the concept of meta-learning for domain generalization and introduce a novel taxonomy based on the feature extraction strategy and the classifier learning methodology, offering a granular view of methodologies. Through an exhaustive review of existing methods and underlying theories, we map out the fundamentals of the field. Our survey provides practical insights and an informed discussion on promising research directions, paving the way for future innovation in meta-learning for domain generalization.
4/4/2024
Error Bounds of Supervised Classification from Information-Theoretic Perspective
Binchuan Qi, Wei Gong, Li Li
0
0
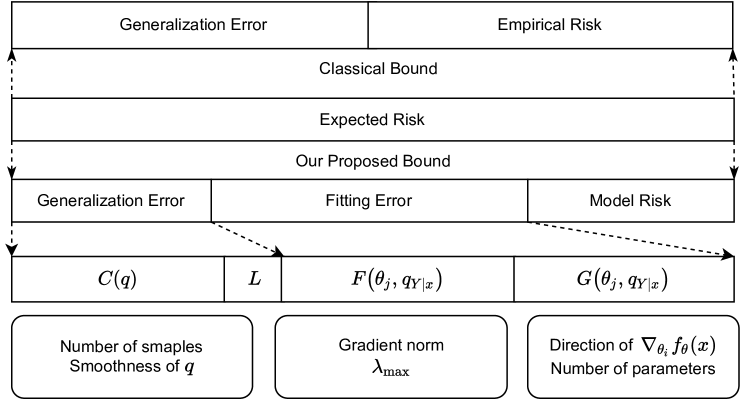
There remains a list of unanswered research questions on deep learning (DL), including the remarkable generalization power of overparametrized neural networks, the efficient optimization performance despite the non-convexity, and the mechanisms behind flat minima in generalization. In this paper, we adopt an information-theoretic perspective to explore the theoretical foundations of supervised classification using deep neural networks (DNNs). Our analysis introduces the concepts of fitting error and model risk, which, together with generalization error, constitute an upper bound on the expected risk. We demonstrate that the generalization errors are bounded by the complexity, influenced by both the smoothness of distribution and the sample size. Consequently, task complexity serves as a reliable indicator of the dataset's quality, guiding the setting of regularization hyperparameters. Furthermore, the derived upper bound fitting error links the back-propagated gradient, Neural Tangent Kernel (NTK), and the model's parameter count with the fitting error. Utilizing the triangle inequality, we establish an upper bound on the expected risk. This bound offers valuable insights into the effects of overparameterization, non-convex optimization, and the flat minima in DNNs.Finally, empirical verification confirms a significant positive correlation between the derived theoretical bounds and the practical expected risk, confirming the practical relevance of the theoretical findings.
6/28/2024
🔄
Future Directions in the Theory of Graph Machine Learning
Christopher Morris, Fabrizio Frasca, Nadav Dym, Haggai Maron, .Ismail .Ilkan Ceylan, Ron Levie, Derek Lim, Michael Bronstein, Martin Grohe, Stefanie Jegelka
0
0
Machine learning on graphs, especially using graph neural networks (GNNs), has seen a surge in interest due to the wide availability of graph data across a broad spectrum of disciplines, from life to social and engineering sciences. Despite their practical success, our theoretical understanding of the properties of GNNs remains highly incomplete. Recent theoretical advancements primarily focus on elucidating the coarse-grained expressive power of GNNs, predominantly employing combinatorial techniques. However, these studies do not perfectly align with practice, particularly in understanding the generalization behavior of GNNs when trained with stochastic first-order optimization techniques. In this position paper, we argue that the graph machine learning community needs to shift its attention to developing a balanced theory of graph machine learning, focusing on a more thorough understanding of the interplay of expressive power, generalization, and optimization.
6/17/2024