Divergent Token Metrics: Measuring degradation to prune away LLM components -- and optimize quantization

0
👀
Sign in to get full access
Overview
- Large language models (LLMs) have made significant advancements in natural language processing, but their growing size raises concerns about effective deployment and the need for compression.
- This study introduces Divergent Token Metrics (DTMs), a novel approach to evaluating compressed LLMs, addressing limitations of traditional metrics like perplexity or accuracy.
- DTMs measure token divergences to provide deeper insights into the nuances of model compression, particularly when assessing individual component impacts.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. They have revolutionized many language-based tasks, like translation, summarization, and question-answering. However, as these models become larger and more complex, there are challenges in deploying them effectively, especially on devices with limited computing power.
This is where model compression comes in. Researchers are exploring ways to make LLMs smaller and more efficient, without losing their impressive capabilities. The paper introduces a new approach, called Divergent Token Metrics (DTMs), to evaluate the quality of compressed LLMs. Traditional metrics, like perplexity or accuracy, don't always capture the nuances of how a compressed model performs.
DTMs look at the differences, or "divergences," between the tokens (individual words or characters) generated by the original and compressed models. This allows for a more detailed understanding of how the compression is affecting the model's text generation abilities. By using DTMs, the researchers were able to identify specific components of the LLM that could be significantly compressed without losing much performance.
For example, they found that 25% of the attention components in the Llama-2 model could be removed while still maintaining state-of-the-art performance. They also discovered that more than 80% of the model's parameters could be converted to a more compact data type (int8) without needing special techniques to handle outliers.
These findings suggest that when compressing LLMs, it's important to consider the individual components and use appropriate compression techniques for each one. Standard metrics may not tell the whole story, and DTMs can provide valuable insights to guide the compression process.
Technical Explanation
This study introduces Divergent Token Metrics (DTMs), a novel approach for evaluating the quality of compressed Large Language Models (LLMs). Traditional evaluation metrics, such as perplexity or accuracy, often fail to accurately reflect the subtleties of text generation when models are compressed.
The core idea behind DTMs is to measure the divergences, or differences, between the tokens (words or characters) generated by the original and compressed LLMs. This provides deeper insights into the nuances of model compression, particularly when assessing the impact of individual components.
The researchers focused on two key compression techniques: sparsification (pruning attention components) and quantization (reducing parameter precision). Using the First Divergent Token Metric (FDTM), they found that 25% of all attention components in the Llama-2 model family could be pruned beyond 90% while still maintaining state-of-the-art performance.
For quantization, FDTM suggested that more than 80% of the model's parameters could be transformed to a more compact int8 data type without needing special outlier management techniques. These results highlight the importance of choosing appropriate compression methods for individual model components, as standard metrics can fail to capture the true impact of compression.
Critical Analysis
The Divergent Token Metrics (DTMs) introduced in this paper provide a novel and promising approach for evaluating compressed Large Language Models (LLMs). By focusing on the divergences between tokens generated by original and compressed models, the authors are able to gain deeper insights into the nuances of model compression.
However, the paper does not address the potential limitations or caveats of the DTM approach. For instance, it's unclear how well the metrics scale to larger, more complex LLMs, or how they might perform in real-world deployment scenarios with diverse datasets and use cases.
Additionally, the paper could have benefited from a more thorough discussion of the potential trade-offs and considerations when applying these compression techniques. While the results show impressive levels of compression, the authors do not explore potential impacts on model robustness, fairness, or safety.
Further research could investigate the generalizability of DTMs, their sensitivity to different compression methods, and their ability to capture more holistic measures of model performance beyond text generation quality. Incorporating these aspects would strengthen the practical relevance and impact of the proposed approach.
Conclusion
This study presents a novel Divergent Token Metrics (DTMs) framework for evaluating compressed Large Language Models (LLMs), addressing the limitations of traditional evaluation methods. By focusing on the divergences between tokens generated by original and compressed models, DTMs provide deeper insights into the nuances of model compression.
The researchers demonstrate the utility of DTMs, particularly the First Divergent Token Metric (FDTM), in guiding effective compression strategies. They show that significant levels of sparsification and quantization can be achieved on the Llama-2 model family without substantial performance degradation.
These findings suggest that a more individualized approach to model compression, guided by appropriate evaluation metrics like DTMs, can lead to more efficient and effective deployment of large language models. As the field of LLMs continues to evolve, the DTM framework offers a promising direction for assessing the quality of compressed models and informing future advancements in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
0
Divergent Token Metrics: Measuring degradation to prune away LLM components -- and optimize quantization
Bjorn Deiseroth, Max Meuer, Nikolas Gritsch, Constantin Eichenberg, Patrick Schramowski, Matthias A{ss}enmacher, Kristian Kersting
Large Language Models (LLMs) have reshaped natural language processing with their impressive capabilities. However, their ever-increasing size has raised concerns about their effective deployment and the need for LLM compression. This study introduces the Divergent Token Metrics (DTMs), a novel approach to assessing compressed LLMs, addressing the limitations of traditional perplexity or accuracy measures that fail to accurately reflect text generation quality. DTMs measure token divergences that allow deeper insights into the subtleties of model compression, in particular, when evaluating components' impacts individually. Utilizing the First Divergent Token Metric (FDTM) in model sparsification reveals that 25% of all attention components can be pruned beyond 90% on the Llama-2 model family, still keeping SOTA performance. For quantization, FDTM suggests that more than 80% of parameters can be naively transformed to int8 without special outlier management. These evaluations indicate the necessity of choosing appropriate compressions for parameters individually -- and that FDTM can identify those -- while standard metrics result in deteriorated outcomes.
Read more4/4/2024

0
Delta-CoMe: Training-Free Delta-Compression with Mixed-Precision for Large Language Models
Bowen Ping, Shuo Wang, Hanqing Wang, Xu Han, Yuzhuang Xu, Yukun Yan, Yun Chen, Baobao Chang, Zhiyuan Liu, Maosong Sun
Fine-tuning is a crucial process for adapting large language models (LLMs) to diverse applications. In certain scenarios, such as multi-tenant serving, deploying multiple LLMs becomes necessary to meet complex demands. Recent studies suggest decomposing a fine-tuned LLM into a base model and corresponding delta weights, which are then compressed using low-rank or low-bit approaches to reduce costs. In this work, we observe that existing low-rank and low-bit compression methods can significantly harm the model performance for task-specific fine-tuned LLMs (e.g., WizardMath for math problems). Motivated by the long-tail distribution of singular values in the delta weights, we propose a delta quantization approach using mixed-precision. This method employs higher-bit representation for singular vectors corresponding to larger singular values. We evaluate our approach on various fine-tuned LLMs, including math LLMs, code LLMs, chat LLMs, and even VLMs. Experimental results demonstrate that our approach performs comparably to full fine-tuned LLMs, surpassing both low-rank and low-bit baselines by a considerable margin. Additionally, we show that our method is compatible with various backbone LLMs, such as Llama-2, Llama-3, and Mistral, highlighting its generalizability.
Read more6/14/2024

191
Accuracy is Not All You Need
Abhinav Dutta, Sanjeev Krishnan, Nipun Kwatra, Ramachandran Ramjee
When Large Language Models (LLMs) are compressed using techniques such as quantization, the predominant way to demonstrate the validity of such techniques is by measuring the model's accuracy on various benchmarks.If the accuracies of the baseline model and the compressed model are close, it is assumed that there was negligible degradation in quality.However, even when the accuracy of baseline and compressed model are similar, we observe the phenomenon of flips, wherein answers change from correct to incorrect and vice versa in proportion.We conduct a detailed study of metrics across multiple compression techniques, models and datasets, demonstrating that the behavior of compressed models as visible to end-users is often significantly different from the baseline model, even when accuracy is similar.We further evaluate compressed models qualitatively and quantitatively using MT-Bench and show that compressed models are significantly worse than baseline models in this free-form generative task.Thus, we argue that compression techniques should also be evaluated using distance metrics.We propose two such metrics, KL-Divergence and flips, and show that they are well correlated.
Read more7/15/2024
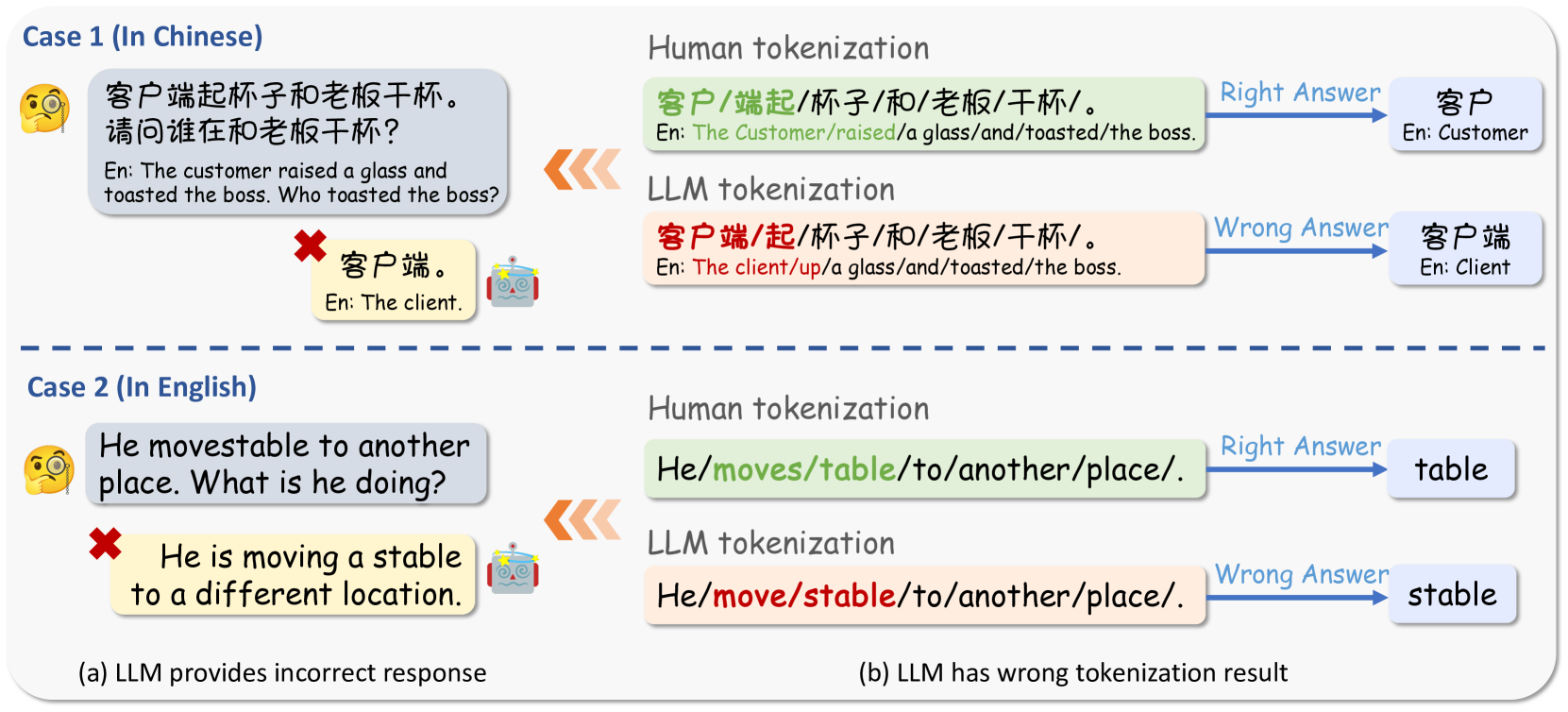
0
Tokenization Matters! Degrading Large Language Models through Challenging Their Tokenization
Dixuan Wang, Yanda Li, Junyuan Jiang, Zepeng Ding, Guochao Jiang, Jiaqing Liang, Deqing Yang
Large Language Models (LLMs) have shown remarkable capabilities in language understanding and generation. Nonetheless, it was also witnessed that LLMs tend to produce inaccurate responses to specific queries. This deficiency can be traced to the tokenization step LLMs must undergo, which is an inevitable limitation inherent to all LLMs. In fact, incorrect tokenization is the critical point that hinders LLMs in understanding the input precisely, thus leading to unsatisfactory output. To demonstrate this flaw of LLMs, we construct an adversarial dataset, named as $textbf{ADT (Adversarial Dataset for Tokenizer)}$, which draws upon the vocabularies of various open-source LLMs to challenge LLMs' tokenization. ADT consists of two subsets: the manually constructed ADT-Human and the automatically generated ADT-Auto. Our empirical results reveal that our ADT is highly effective on challenging the tokenization of leading LLMs, including GPT-4o, Llama-3, Qwen2.5-max and so on, thus degrading these LLMs' capabilities. Moreover, our method of automatic data generation has been proven efficient and robust, which can be applied to any open-source LLMs. To the best of our knowledge, our study is the first to investigating LLMs' vulnerability in terms of challenging their token segmentation, which will shed light on the subsequent research of improving LLMs' capabilities through optimizing their tokenization process and algorithms.
Read more5/28/2024