Tokenization Matters! Degrading Large Language Models through Challenging Their Tokenization

0
Sign in to get full access
Overview
- This paper investigates how the tokenization process used by large language models (LLMs) can be exploited to degrade their performance.
- The researchers found that by introducing carefully crafted "tokenization challenges" into text inputs, they were able to significantly degrade the performance of LLMs on various tasks, including language understanding, generation, and reasoning.
- The results suggest that the tokenization process is a critical and often overlooked component of LLMs, and that understanding and addressing tokenization-related vulnerabilities could be important for improving the robustness and reliability of these models.
Plain English Explanation
The paper looks at how the way large language models (LLMs) break down text into smaller pieces, called "tokens," can be used to make the models perform worse. LLMs are powerful AI systems that can understand and generate human language, but they rely on this tokenization process to make sense of the text they're given.
The researchers discovered that by introducing certain carefully designed "tokenization challenges" into the text, they could significantly degrade the LLMs' performance on a variety of tasks, such as understanding the meaning of sentences, generating new text, and even reasoning about complex ideas. This suggests that the way these models handle tokenization is a critical, but often overlooked, part of how they work.
By understanding the vulnerabilities in the tokenization process, the researchers believe it may be possible to improve the overall robustness and reliability of LLMs, making them more resistant to this kind of attack. This could be important as these models become more widely used in real-world applications.
Technical Explanation
The paper explores how the tokenization process used by large language models (LLMs) can be exploited to degrade their performance. Tokenization is the process of breaking down text into smaller, meaningful units (tokens) that the LLM can then process and understand.
The researchers designed a set of "tokenization challenges" - carefully crafted text inputs that were designed to exploit weaknesses in the tokenization process of various LLMs, including GPT-3, BERT, and DALL-E 2. They found that by introducing these challenges, they were able to significantly degrade the LLMs' performance on a range of tasks, including language understanding, generation, and reasoning.
The results suggest that the tokenization process is a critical and often overlooked component of LLMs, and that understanding and addressing tokenization-related vulnerabilities could be important for improving the overall robustness and reliability of these models. This could be particularly important as LLMs become more widely deployed in real-world applications, where they may encounter a diverse range of input data and use cases.
Critical Analysis
The paper provides valuable insights into the importance of the tokenization process in large language models (LLMs) and highlights the potential vulnerabilities that can arise from this often overlooked component. The researchers' approach of designing carefully crafted "tokenization challenges" to degrade LLM performance is a novel and thought-provoking technique that could have broader implications for understanding and improving the robustness of these models.
However, it's important to note that the paper focuses primarily on demonstrating the feasibility of these tokenization-based attacks, and does not provide comprehensive solutions or mitigation strategies. While the researchers mention that addressing tokenization-related vulnerabilities could be important for improving LLM robustness, the paper does not delve deeply into specific approaches for achieving this.
Additionally, the paper's experiments are limited to a relatively small set of LLMs and tasks, and it's unclear how the findings would generalize to a wider range of models and use cases. Further research would be needed to better understand the broader implications and potential real-world impacts of these tokenization-based attacks.
It would also be valuable for the paper to explore the potential causes and underlying mechanisms behind the observed tokenization vulnerabilities, as this could provide more insights into how to address them effectively. Exploring the tradeoffs between tokenization performance, model complexity, and robustness could also be a fruitful area for future research.
Conclusion
The paper "Tokenization Matters! Degrading Large Language Models through Challenging Their Tokenization" highlights the critical role that the tokenization process plays in the performance of large language models (LLMs). The researchers' demonstration of how carefully designed "tokenization challenges" can significantly degrade LLM performance on a range of tasks suggests that understanding and addressing tokenization-related vulnerabilities could be an important step in improving the overall robustness and reliability of these powerful AI systems.
As LLMs become more widely deployed in real-world applications, ensuring their resilience to such tokenization-based attacks will be crucial. The insights and techniques presented in this paper could serve as a valuable starting point for further research and development in this area, with the ultimate goal of creating more robust and trustworthy language models that can be reliably deployed in a wide range of contexts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Tokenization Matters! Degrading Large Language Models through Challenging Their Tokenization
Dixuan Wang, Yanda Li, Junyuan Jiang, Zepeng Ding, Guochao Jiang, Jiaqing Liang, Deqing Yang
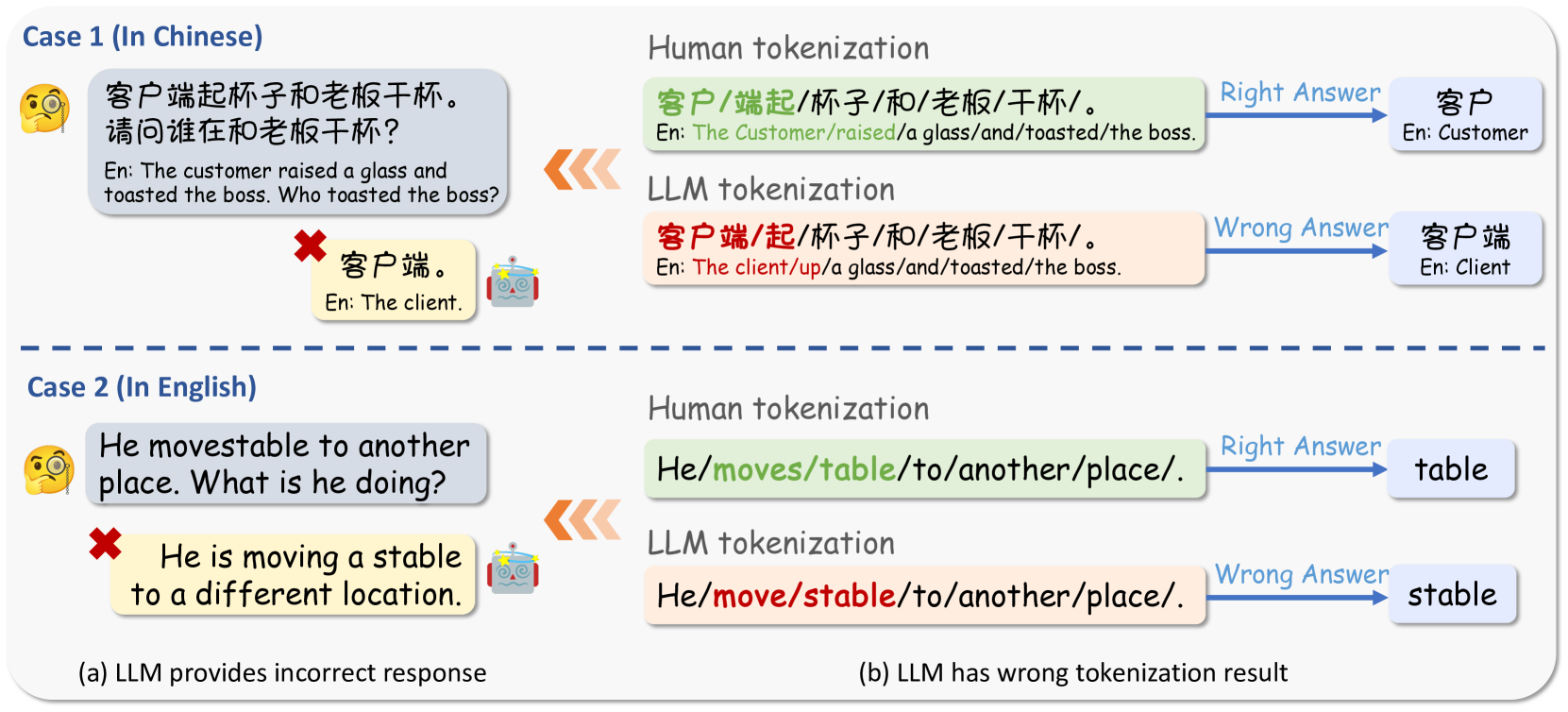
Large Language Models (LLMs) have shown remarkable capabilities in language understanding and generation. Nonetheless, it was also witnessed that LLMs tend to produce inaccurate responses to specific queries. This deficiency can be traced to the tokenization step LLMs must undergo, which is an inevitable limitation inherent to all LLMs. In fact, incorrect tokenization is the critical point that hinders LLMs in understanding the input precisely, thus leading to unsatisfactory output. To demonstrate this flaw of LLMs, we construct an adversarial dataset, named as $textbf{ADT (Adversarial Dataset for Tokenizer)}$, which draws upon the vocabularies of various open-source LLMs to challenge LLMs' tokenization. ADT consists of two subsets: the manually constructed ADT-Human and the automatically generated ADT-Auto. Our empirical results reveal that our ADT is highly effective on challenging the tokenization of leading LLMs, including GPT-4o, Llama-3, Qwen2.5-max and so on, thus degrading these LLMs' capabilities. Moreover, our method of automatic data generation has been proven efficient and robust, which can be applied to any open-source LLMs. To the best of our knowledge, our study is the first to investigating LLMs' vulnerability in terms of challenging their token segmentation, which will shed light on the subsequent research of improving LLMs' capabilities through optimizing their tokenization process and algorithms.
Read more5/28/2024

0
Tokenization Falling Short: The Curse of Tokenization
Yekun Chai, Yewei Fang, Qiwei Peng, Xuhong Li
Language models typically tokenize raw text into sequences of subword identifiers from a predefined vocabulary, a process inherently sensitive to typographical errors, length variations, and largely oblivious to the internal structure of tokens-issues we term the curse of tokenization. In this study, we delve into these drawbacks and demonstrate that large language models (LLMs) remain susceptible to these problems. This study systematically investigates these challenges and their impact on LLMs through three critical research questions: (1) complex problem solving, (2) token structure probing, and (3) resilience to typographical variation. Our findings reveal that scaling model parameters can mitigate the issue of tokenization; however, LLMs still suffer from biases induced by typos and other text format variations. Our experiments show that subword regularization such as BPE-dropout can mitigate this issue. We will release our code and data to facilitate further research.
Read more6/18/2024
⚙️
0
Toward a Theory of Tokenization in LLMs
Nived Rajaraman, Jiantao Jiao, Kannan Ramchandran
While there has been a large body of research attempting to circumvent tokenization for language modeling (Clark et al., 2022; Xue et al., 2022), the current consensus is that it is a necessary initial step for designing state-of-the-art performant language models. In this paper, we investigate tokenization from a theoretical point of view by studying the behavior of transformers on simple data generating processes. When trained on data drawn from certain simple $k^{text{th}}$-order Markov processes for $k > 1$, transformers exhibit a surprising phenomenon - in the absence of tokenization, they empirically fail to learn the right distribution and predict characters according to a unigram model (Makkuva et al., 2024). With the addition of tokenization, however, we empirically observe that transformers break through this barrier and are able to model the probabilities of sequences drawn from the source near-optimally, achieving small cross-entropy loss. With this observation as starting point, we study the end-to-end cross-entropy loss achieved by transformers with and without tokenization. With the appropriate tokenization, we show that even the simplest unigram models (over tokens) learnt by transformers are able to model the probability of sequences drawn from $k^{text{th}}$-order Markov sources near optimally. Our analysis provides a justification for the use of tokenization in practice through studying the behavior of transformers on Markovian data.
Read more4/15/2024
0
Assessing Adversarial Robustness of Large Language Models: An Empirical Study
Zeyu Yang, Zhao Meng, Xiaochen Zheng, Roger Wattenhofer
Large Language Models (LLMs) have revolutionized natural language processing, but their robustness against adversarial attacks remains a critical concern. We presents a novel white-box style attack approach that exposes vulnerabilities in leading open-source LLMs, including Llama, OPT, and T5. We assess the impact of model size, structure, and fine-tuning strategies on their resistance to adversarial perturbations. Our comprehensive evaluation across five diverse text classification tasks establishes a new benchmark for LLM robustness. The findings of this study have far-reaching implications for the reliable deployment of LLMs in real-world applications and contribute to the advancement of trustworthy AI systems.
Read more9/16/2024