Diversifying the Mixture-of-Experts Representation for Language Models with Orthogonal Optimizer

0
💬
Sign in to get full access
Overview
- The Mixture of Experts (MoE) is a successful deep learning technique that divides a model into specialized "experts" to maximize capacity without much extra computational cost.
- Even in the era of large language models (LLMs), MoE continues to play a crucial role, with indications that GPT-4 uses the MoE structure.
- However, MoE can suffer from performance issues, particularly imbalance and homogeneous representation among experts.
- While imbalance has been addressed, the challenge of homogeneous representation remains unresolved.
Plain English Explanation
The Mixture of Experts (MoE) is a clever way to build powerful deep learning models without dramatically increasing the computational cost. The key idea is to divide the model into specialized "experts" that each focus on a different part of the task. This "divide-and-conquer" approach allows the model to have a large overall capacity while keeping the individual experts relatively small and efficient.
Even as large language models (LLMs) like GPT-4 have become dominant, the MoE structure continues to play an important role. In fact, some researchers believe GPT-4 may use a MoE approach to ensure diverse and high-quality inference results.
However, the MoE structure is susceptible to some tricky problems. One issue is "imbalance," where some experts become much more heavily used than others. Another problem is "homogeneous representation," where the experts fail to specialize and their outputs become too similar to each other. While the imbalance problem has been studied extensively, the homogeneous representation challenge has remained unresolved - until now.
Technical Explanation
In this study, the researchers shed light on the homogeneous representation problem in MoE models. They found that in well-performing MoE models, the experts can end up with representations that are up to 99% similar to each other. This lack of diversity contradicts the original intention of the MoE approach, which is to leverage specialized experts to enhance the model's expressive power.
To tackle this issue, the researchers propose a new technique called "Orthogonal Mixture of Experts" (OMoE). The key ideas are:
-
Orthogonal Expert Optimizer: This component explicitly encourages each expert to update its weights in a direction orthogonal to the subspace spanned by the other experts. This helps enhance representation diversity.
-
Alternating Training Strategy: The researchers introduce a training approach where the experts take turns updating their weights, forcing them to interact and specialize in different directions.
Through extensive experiments on benchmarks like GLUE, SuperGLUE, question-answering, and named entity recognition, the researchers demonstrate that their OMoE approach significantly improves the performance of fine-tuned MoE models compared to previous methods.
Critical Analysis
The researchers have identified an important limitation of MoE models - the tendency for experts to develop homogeneous representations, undermining the original motivation of the approach. Their proposed OMoE solution is a clever and effective way to address this challenge.
However, the paper does not explore some potential caveats or limitations of the OMoE method. For example, the impact of the orthogonality constraint on model capacity and flexibility is not discussed. Additionally, the researchers focus on fine-tuning experiments, but it's unclear how OMoE would perform in training large-scale MoE models from scratch.
Further research could also investigate the theoretical underpinnings of the homogeneous representation problem and explore alternative approaches beyond the orthogonality-based solution presented here. Analyzing the tradeoffs between representation diversity, model capacity, and computational efficiency would also be a valuable direction for future work.
Conclusion
This study sheds light on a critical issue in Mixture of Experts (MoE) models - the tendency for experts to develop homogeneous representations, undermining the core benefits of the approach. The researchers' proposed OMoE solution, which uses an orthogonal expert optimizer and an alternating training strategy, is a significant step forward in addressing this challenge.
By demonstrating the effectiveness of OMoE on a range of benchmarks, the researchers have highlighted the potential of this technique to improve the performance and capabilities of MoE-based models, including in the context of large language models like GPT-4. As the field of deep learning continues to evolve, addressing issues like homogeneous representation will be crucial to unlocking the full potential of modular and specialized architectures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Diversifying the Mixture-of-Experts Representation for Language Models with Orthogonal Optimizer
Boan Liu, Liang Ding, Li Shen, Keqin Peng, Yu Cao, Dazhao Cheng, Dacheng Tao
The Mixture of Experts (MoE) has emerged as a highly successful technique in deep learning, based on the principle of divide-and-conquer to maximize model capacity without significant additional computational cost. Even in the era of large-scale language models (LLMs), MoE continues to play a crucial role, as some researchers have indicated that GPT-4 adopts the MoE structure to ensure diverse inference results. However, MoE is susceptible to performance degeneracy, particularly evident in the issues of imbalance and homogeneous representation among experts. While previous studies have extensively addressed the problem of imbalance, the challenge of homogeneous representation remains unresolved. In this study, we shed light on the homogeneous representation problem, wherein experts in the MoE fail to specialize and lack diversity, leading to frustratingly high similarities in their representations (up to 99% in a well-performed MoE model). This problem restricts the expressive power of the MoE and, we argue, contradicts its original intention. To tackle this issue, we propose a straightforward yet highly effective solution: OMoE, an orthogonal expert optimizer. Additionally, we introduce an alternating training strategy that encourages each expert to update in a direction orthogonal to the subspace spanned by other experts. Our algorithm facilitates MoE training in two key ways: firstly, it explicitly enhances representation diversity, and secondly, it implicitly fosters interaction between experts during orthogonal weights computation. Through extensive experiments, we demonstrate that our proposed optimization algorithm significantly improves the performance of fine-tuning the MoE model on the GLUE benchmark, SuperGLUE benchmark, question-answering task, and name entity recognition tasks.
Read more9/2/2024

0
HMoE: Heterogeneous Mixture of Experts for Language Modeling
An Wang, Xingwu Sun, Ruobing Xie, Shuaipeng Li, Jiaqi Zhu, Zhen Yang, Pinxue Zhao, J. N. Han, Zhanhui Kang, Di Wang, Naoaki Okazaki, Cheng-zhong Xu
Mixture of Experts (MoE) offers remarkable performance and computational efficiency by selectively activating subsets of model parameters. Traditionally, MoE models use homogeneous experts, each with identical capacity. However, varying complexity in input data necessitates experts with diverse capabilities, while homogeneous MoE hinders effective expert specialization and efficient parameter utilization. In this study, we propose a novel Heterogeneous Mixture of Experts (HMoE), where experts differ in size and thus possess diverse capacities. This heterogeneity allows for more specialized experts to handle varying token complexities more effectively. To address the imbalance in expert activation, we propose a novel training objective that encourages the frequent activation of smaller experts, enhancing computational efficiency and parameter utilization. Extensive experiments demonstrate that HMoE achieves lower loss with fewer activated parameters and outperforms conventional homogeneous MoE models on various pre-training evaluation benchmarks. Codes will be released upon acceptance.
Read more8/21/2024

0
A Survey on Mixture of Experts
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, Jiayi Huang
Large language models (LLMs) have garnered unprecedented advancements across diverse fields, ranging from natural language processing to computer vision and beyond. The prowess of LLMs is underpinned by their substantial model size, extensive and diverse datasets, and the vast computational power harnessed during training, all of which contribute to the emergent abilities of LLMs (e.g., in-context learning) that are not present in small models. Within this context, the mixture of experts (MoE) has emerged as an effective method for substantially scaling up model capacity with minimal computation overhead, gaining significant attention from academia and industry. Despite its growing prevalence, there lacks a systematic and comprehensive review of the literature on MoE. This survey seeks to bridge that gap, serving as an essential resource for researchers delving into the intricacies of MoE. We first briefly introduce the structure of the MoE layer, followed by proposing a new taxonomy of MoE. Next, we overview the core designs for various MoE models including both algorithmic and systemic aspects, alongside collections of available open-source implementations, hyperparameter configurations and empirical evaluations. Furthermore, we delineate the multifaceted applications of MoE in practice, and outline some potential directions for future research. To facilitate ongoing updates and the sharing of cutting-edge developments in MoE research, we have established a resource repository accessible at https://github.com/withinmiaov/A-Survey-on-Mixture-of-Experts.
Read more7/10/2024
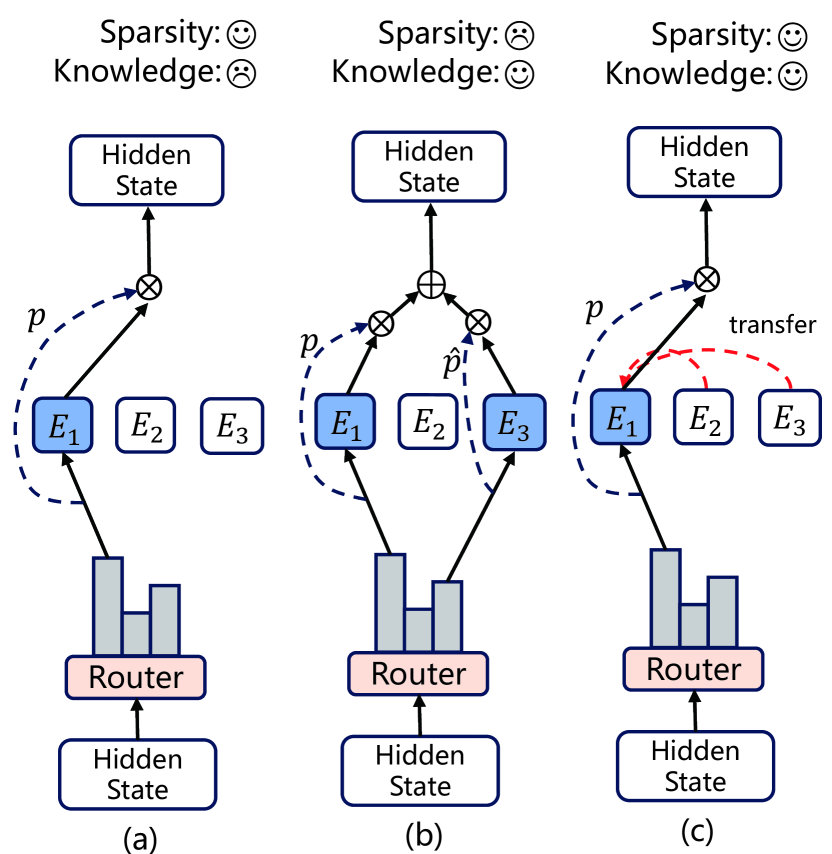
0
HyperMoE: Towards Better Mixture of Experts via Transferring Among Experts
Hao Zhao, Zihan Qiu, Huijia Wu, Zili Wang, Zhaofeng He, Jie Fu
The Mixture of Experts (MoE) for language models has been proven effective in augmenting the capacity of models by dynamically routing each input token to a specific subset of experts for processing. Despite the success, most existing methods face a challenge for balance between sparsity and the availability of expert knowledge: enhancing performance through increased use of expert knowledge often results in diminishing sparsity during expert selection. To mitigate this contradiction, we propose HyperMoE, a novel MoE framework built upon Hypernetworks. This framework integrates the computational processes of MoE with the concept of knowledge transferring in multi-task learning. Specific modules generated based on the information of unselected experts serve as supplementary information, which allows the knowledge of experts not selected to be used while maintaining selection sparsity. Our comprehensive empirical evaluations across multiple datasets and backbones establish that HyperMoE significantly outperforms existing MoE methods under identical conditions concerning the number of experts.
Read more7/26/2024