DiversityMedQA: Assessing Demographic Biases in Medical Diagnosis using Large Language Models

0
Sign in to get full access
Overview
- This research paper assesses demographic biases in medical diagnosis using large language models (LLMs).
- The authors introduce a new dataset called DiversityMedQA to evaluate the performance and fairness of LLMs on medical question answering.
- The paper analyzes the potential for LLMs to exhibit biases based on patient demographic factors such as race, gender, and age.
Plain English Explanation
The researchers wanted to understand if large language models, which are AI systems that can understand and generate human language, might be biased when it comes to medical diagnosis. They created a new dataset called DiversityMedQA that contains medical questions and answers. This dataset includes information about the patient's demographic background, like their race, gender, and age.
By testing the language models on this dataset, the researchers could see if the models performed differently or gave different answers depending on the patient's demographics. This helps identify potential biases in how the models approach medical diagnosis and decision-making.
The key idea is to ensure that these powerful language models, which are increasingly being used in healthcare, treat all patients fairly and equitably regardless of their background. The findings from this research can help develop more inclusive and unbiased AI systems for medical applications.
Technical Explanation
The paper introduces the DiversityMedQA dataset, which contains over 12,000 medical questions and answers covering a diverse range of patient demographics, including race, gender, and age. The authors use this dataset to evaluate the performance and fairness of large language models on medical question answering tasks.
The researchers fine-tune several popular pre-trained language models, including BERT, RoBERTa, and GPT-3, on the DiversityMedQA dataset. They then analyze the models' performance across different demographic subgroups to identify any disparities or biases.
The results show that the language models exhibit varying degrees of demographic biases. For example, the models tend to perform better on questions about white and male patients compared to non-white and female patients. The authors also find that the models' responses can reflect harmful stereotypes or assumptions about certain demographic groups.
The paper provides detailed quantitative and qualitative analyses of these bias patterns, offering insights into the potential risks of deploying large language models in high-stakes medical domains. The findings highlight the importance of comprehensive testing and mitigation strategies to ensure the fairness and equity of AI-powered clinical decision support systems.
Critical Analysis
The DiversityMedQA dataset and the associated evaluation framework presented in this paper are valuable contributions to the growing body of research on bias in medical AI systems. By focusing on the intersection of language models and healthcare, the authors shed light on an important and underexplored area of concern.
However, the paper acknowledges several limitations of the current study. For instance, the dataset may not fully capture the nuances and complexities of real-world medical encounters, and the language models tested are not necessarily representative of all AI systems used in healthcare. Additionally, the authors note that further research is needed to understand the root causes of the observed biases and develop effective mitigation strategies.
It would be interesting to see the authors expand this work to investigate the performance of the language models on other healthcare-related tasks, such as clinical note generation or treatment recommendation. Exploring the generalizability of the bias patterns across different medical domains could provide a more comprehensive understanding of the challenges and opportunities in leveraging large language models for healthcare applications.
Conclusion
This research paper makes a significant contribution to the growing field of algorithmic fairness and bias in medical AI. By introducing the DiversityMedQA dataset and using it to evaluate the demographic biases of large language models, the authors have highlighted the critical need for thorough testing and oversight of these systems before deployment in high-stakes healthcare settings.
The findings from this study underscore the importance of developing inclusive and equitable AI-powered clinical decision support tools that can serve all patients, regardless of their background. As language models continue to advance and become more integrated into healthcare, the insights from this work will be invaluable for ensuring that these technologies promote rather than exacerbate healthcare disparities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DiversityMedQA: Assessing Demographic Biases in Medical Diagnosis using Large Language Models
Rajat Rawat, Hudson McBride, Dhiyaan Nirmal, Rajarshi Ghosh, Jong Moon, Dhruv Alamuri, Sean O'Brien, Kevin Zhu
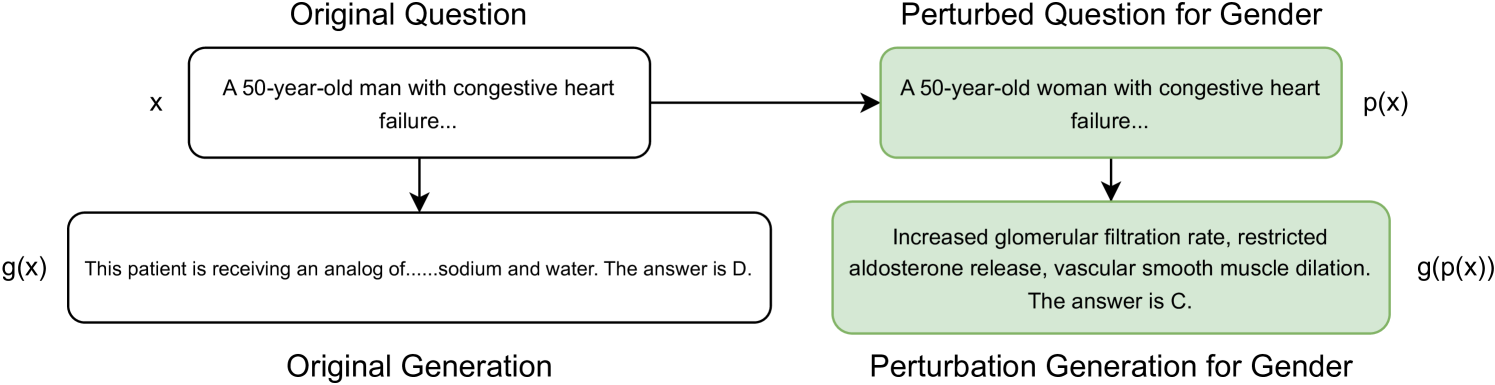
As large language models (LLMs) gain traction in healthcare, concerns about their susceptibility to demographic biases are growing. We introduce {DiversityMedQA}, a novel benchmark designed to assess LLM responses to medical queries across diverse patient demographics, such as gender and ethnicity. By perturbing questions from the MedQA dataset, which comprises medical board exam questions, we created a benchmark that captures the nuanced differences in medical diagnosis across varying patient profiles. Our findings reveal notable discrepancies in model performance when tested against these demographic variations. Furthermore, to ensure the perturbations were accurate, we also propose a filtering strategy that validates each perturbation. By releasing DiversityMedQA, we provide a resource for evaluating and mitigating demographic bias in LLM medical diagnoses.
Read more9/4/2024
🌀
0
Bias patterns in the application of LLMs for clinical decision support: A comprehensive study
Raphael Poulain, Hamed Fayyaz, Rahmatollah Beheshti
Large Language Models (LLMs) have emerged as powerful candidates to inform clinical decision-making processes. While these models play an increasingly prominent role in shaping the digital landscape, two growing concerns emerge in healthcare applications: 1) to what extent do LLMs exhibit social bias based on patients' protected attributes (like race), and 2) how do design choices (like architecture design and prompting strategies) influence the observed biases? To answer these questions rigorously, we evaluated eight popular LLMs across three question-answering (QA) datasets using clinical vignettes (patient descriptions) standardized for bias evaluations. We employ red-teaming strategies to analyze how demographics affect LLM outputs, comparing both general-purpose and clinically-trained models. Our extensive experiments reveal various disparities (some significant) across protected groups. We also observe several counter-intuitive patterns such as larger models not being necessarily less biased and fined-tuned models on medical data not being necessarily better than the general-purpose models. Furthermore, our study demonstrates the impact of prompt design on bias patterns and shows that specific phrasing can influence bias patterns and reflection-type approaches (like Chain of Thought) can reduce biased outcomes effectively. Consistent with prior studies, we call on additional evaluations, scrutiny, and enhancement of LLMs used in clinical decision support applications.
Read more4/24/2024
0
MedExpQA: Multilingual Benchmarking of Large Language Models for Medical Question Answering
I~nigo Alonso, Maite Oronoz, Rodrigo Agerri
Large Language Models (LLMs) have the potential of facilitating the development of Artificial Intelligence technology to assist medical experts for interactive decision support, which has been demonstrated by their competitive performances in Medical QA. However, while impressive, the required quality bar for medical applications remains far from being achieved. Currently, LLMs remain challenged by outdated knowledge and by their tendency to generate hallucinated content. Furthermore, most benchmarks to assess medical knowledge lack reference gold explanations which means that it is not possible to evaluate the reasoning of LLMs predictions. Finally, the situation is particularly grim if we consider benchmarking LLMs for languages other than English which remains, as far as we know, a totally neglected topic. In order to address these shortcomings, in this paper we present MedExpQA, the first multilingual benchmark based on medical exams to evaluate LLMs in Medical Question Answering. To the best of our knowledge, MedExpQA includes for the first time reference gold explanations written by medical doctors which can be leveraged to establish various gold-based upper-bounds for comparison with LLMs performance. Comprehensive multilingual experimentation using both the gold reference explanations and Retrieval Augmented Generation (RAG) approaches show that performance of LLMs still has large room for improvement, especially for languages other than English. Furthermore, and despite using state-of-the-art RAG methods, our results also demonstrate the difficulty of obtaining and integrating readily available medical knowledge that may positively impact results on downstream evaluations for Medical Question Answering. So far the benchmark is available in four languages, but we hope that this work may encourage further development to other languages.
Read more7/30/2024
0
MedREQAL: Examining Medical Knowledge Recall of Large Language Models via Question Answering
Juraj Vladika, Phillip Schneider, Florian Matthes
In recent years, Large Language Models (LLMs) have demonstrated an impressive ability to encode knowledge during pre-training on large text corpora. They can leverage this knowledge for downstream tasks like question answering (QA), even in complex areas involving health topics. Considering their high potential for facilitating clinical work in the future, understanding the quality of encoded medical knowledge and its recall in LLMs is an important step forward. In this study, we examine the capability of LLMs to exhibit medical knowledge recall by constructing a novel dataset derived from systematic reviews -- studies synthesizing evidence-based answers for specific medical questions. Through experiments on the new MedREQAL dataset, comprising question-answer pairs extracted from rigorous systematic reviews, we assess six LLMs, such as GPT and Mixtral, analyzing their classification and generation performance. Our experimental insights into LLM performance on the novel biomedical QA dataset reveal the still challenging nature of this task.
Read more6/11/2024