Do Large Language Models Learn Human-Like Strategic Preferences?
2404.08710
0
0
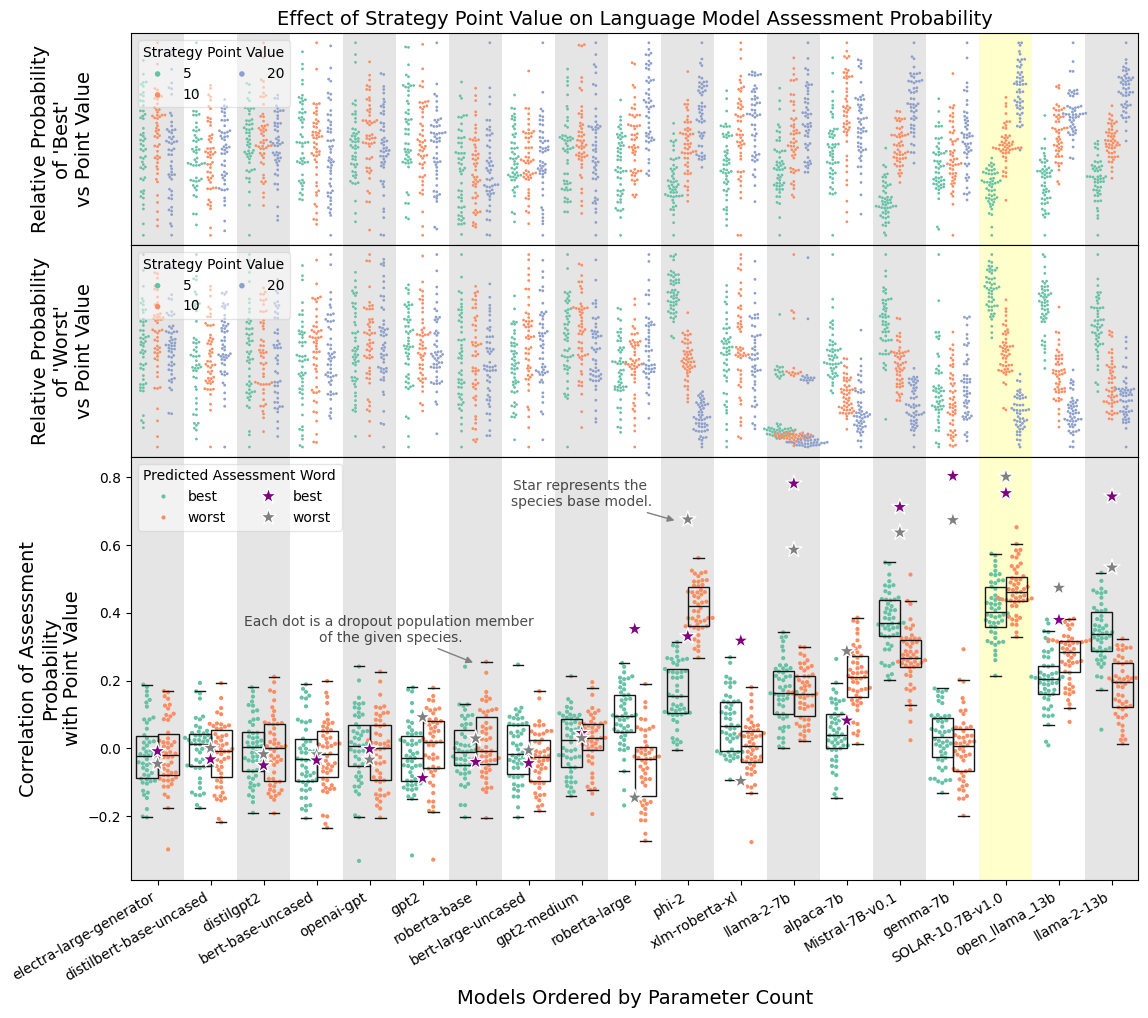
Abstract
We evaluate whether LLMs learn to make human-like preference judgements in strategic scenarios as compared with known empirical results. We show that Solar and Mistral exhibit stable value-based preference consistent with human in the prisoner's dilemma, including stake-size effect, and traveler's dilemma, including penalty-size effect. We establish a relationship between model size, value based preference, and superficiality. Finally, we find that models that tend to be less brittle were trained with sliding window attention. Additionally, we contribute a novel method for constructing preference relations from arbitrary LLMs and support for a hypothesis regarding human behavior in the traveler's dilemma.
Create account to get full access
Overview
- This paper investigates whether large language models (LLMs) can learn human-like strategic preferences, such as cooperation, competition, and fairness, through training on natural language data.
- The authors explore whether LLMs internalize these preferences and incorporate them into their decision-making, or if their behavior is driven solely by statistical patterns in the training data.
- The findings have implications for understanding the cognitive capabilities of LLMs and their potential alignment with human values and goals.
Plain English Explanation
In this research, the authors examine whether large language models (LLMs) - powerful AI systems trained on vast amounts of text data - can learn and adopt human-like strategic preferences, such as a tendency to cooperate, compete, or seek fairness.
The key question is whether these models truly understand and internalize these social and strategic concepts, or if their behavior is simply a reflection of the statistical patterns in their training data, without a deeper comprehension of the underlying principles.
Understanding the extent to which LLMs can learn and apply human-like strategic preferences is important for evaluating their cognitive capabilities and potential alignment with human values. If LLMs can meaningfully grasp and incorporate these preferences, it suggests they may be able to engage in more nuanced and socially-aware decision-making. However, if their behavior is driven solely by data patterns, it raises questions about their true understanding of complex human behavior and interactions.
By investigating this issue, the researchers aim to shed light on the nature of LLM intelligence and its implications for the development of AI systems that can collaborate with and assist humans in meaningful ways.
Technical Explanation
The paper describes a series of experiments designed to assess whether large language models (LLMs) exhibit human-like strategic preferences, such as cooperation, competition, and fairness, when engaging in decision-making tasks.
The authors first trained several LLM architectures, including GPT-3 and Megatron-LM, on a diverse corpus of natural language data. They then evaluated the models' behavior in a set of strategic games, including the Prisoner's Dilemma, the Ultimatum Game, and the Public Goods Game, which are widely used to study human social and strategic preferences.
In these games, the LLMs were tasked with making decisions that could lead to different payoff outcomes for themselves and their "opponents." The researchers analyzed the models' choices to determine whether they exhibited preferences akin to human players, such as a tendency to cooperate, maximize their own gains, or ensure fair outcomes.
The results suggest that the LLMs did indeed display some human-like strategic preferences, but the extent and nature of these preferences varied depending on the specific game and model architecture. For example, the models showed a greater propensity for fairness in the Ultimatum Game, but were more likely to prioritize their own gains in the Prisoner's Dilemma.
The authors also explored potential explanations for these findings, considering the role of the training data, the models' underlying architectures, and the potential for emergent strategic reasoning capabilities.
Critical Analysis
The paper provides valuable insights into the strategic reasoning capabilities of large language models, but it also acknowledges several caveats and limitations in the research.
One key limitation is the reliance on synthetic game-based scenarios, which may not fully capture the complexity and nuance of real-world human social interactions. The authors note that further research is needed to understand how LLMs' strategic preferences manifest in more naturalistic contexts.
Additionally, the study only examines a subset of strategic preferences, and it's unclear whether the models' behavior in these specific games can be generalized to a broader range of social and decision-making scenarios. The authors suggest that future work should explore a wider range of strategic environments and preferences.
Another potential concern is the potential for LLMs to exhibit biases or inconsistencies in their strategic preferences, depending on the specific game or task. The paper acknowledges this issue and calls for further investigation into the stability and coherence of these preferences across different contexts.
Overall, the research represents an important step in understanding the cognitive capabilities of large language models and their potential alignment with human values. However, more work is needed to fully characterize the nature and limits of LLMs' strategic reasoning abilities and their implications for the development of AI systems that can effectively collaborate with and assist humans.
Conclusion
This paper explores a critical question in the field of artificial intelligence: can large language models (LLMs) learn and exhibit human-like strategic preferences, such as a tendency to cooperate, compete, or seek fairness?
The findings suggest that LLMs do demonstrate some human-like strategic behavior, but the extent and nature of these preferences can vary depending on the specific decision-making context. This indicates that LLMs may be capable of more nuanced and socially-aware decision-making than previously thought, with potential implications for their use in a wide range of applications that require collaboration and alignment with human values.
However, the research also highlights the need for further investigation into the stability and generalizability of LLMs' strategic preferences, as well as the broader implications for the development of AI systems that can effectively interact with and assist humans. Addressing these challenges will be crucial as researchers and policymakers grapple with the ethical and practical considerations of integrating advanced language models into our lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Survey on Human Preference Learning for Large Language Models
Ruili Jiang, Kehai Chen, Xuefeng Bai, Zhixuan He, Juntao Li, Muyun Yang, Tiejun Zhao, Liqiang Nie, Min Zhang
0
0
The recent surge of versatile large language models (LLMs) largely depends on aligning increasingly capable foundation models with human intentions by preference learning, enhancing LLMs with excellent applicability and effectiveness in a wide range of contexts. Despite the numerous related studies conducted, a perspective on how human preferences are introduced into LLMs remains limited, which may prevent a deeper comprehension of the relationships between human preferences and LLMs as well as the realization of their limitations. In this survey, we review the progress in exploring human preference learning for LLMs from a preference-centered perspective, covering the sources and formats of preference feedback, the modeling and usage of preference signals, as well as the evaluation of the aligned LLMs. We first categorize the human feedback according to data sources and formats. We then summarize techniques for human preferences modeling and compare the advantages and disadvantages of different schools of models. Moreover, we present various preference usage methods sorted by the objectives to utilize human preference signals. Finally, we summarize some prevailing approaches to evaluate LLMs in terms of alignment with human intentions and discuss our outlooks on the human intention alignment for LLMs.
6/19/2024
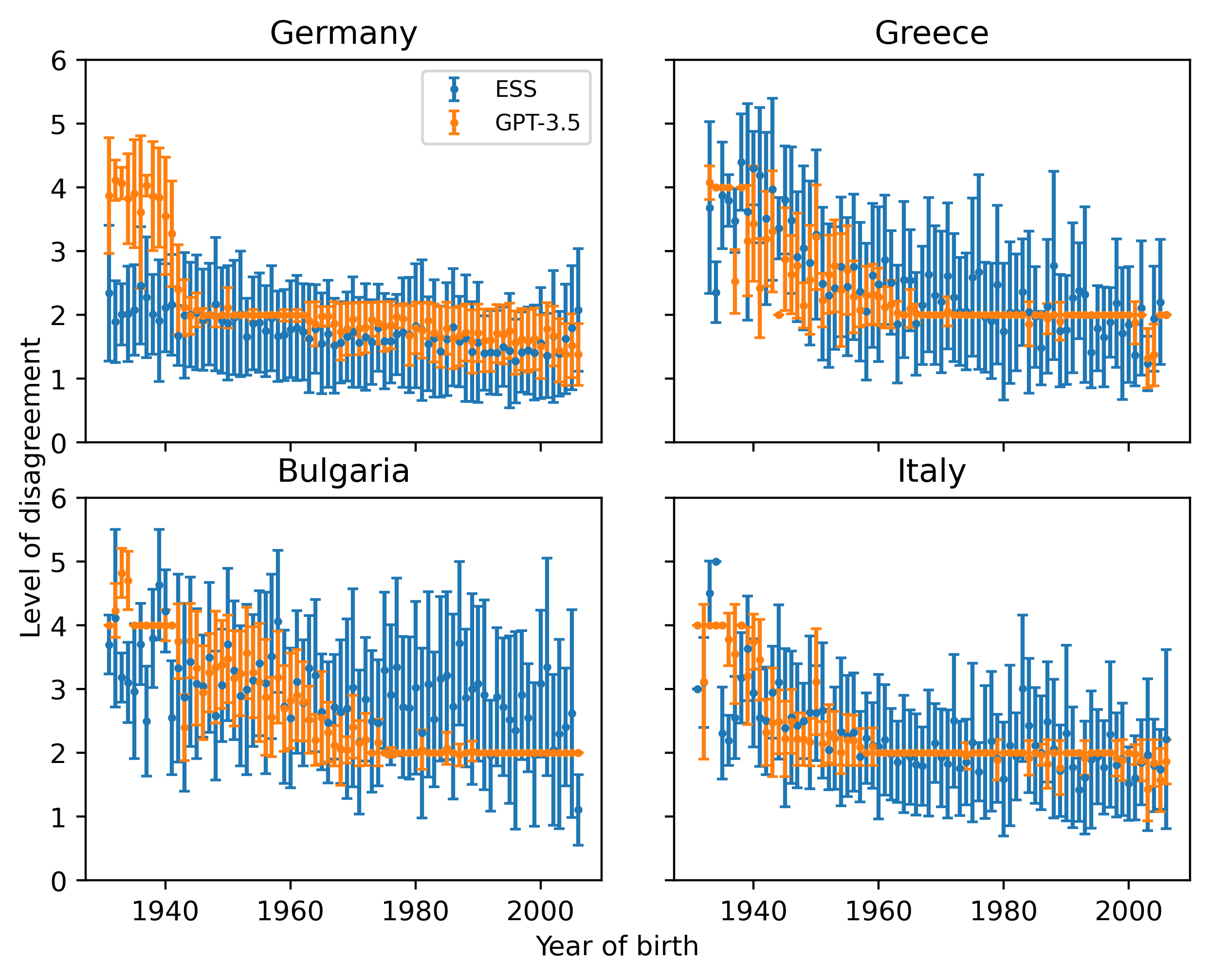
Are Large Language Models Chameleons?
Mingmeng Geng, Sihong He, Roberto Trotta
0
0
Do large language models (LLMs) have their own worldviews and personality tendencies? Simulations in which an LLM was asked to answer subjective questions were conducted more than 1 million times. Comparison of the responses from different LLMs with real data from the European Social Survey (ESS) suggests that the effect of prompts on bias and variability is fundamental, highlighting major cultural, age, and gender biases. Methods for measuring the difference between LLMs and survey data are discussed, such as calculating weighted means and a new proposed measure inspired by Jaccard similarity. We conclude that it is important to analyze the robustness and variability of prompts before using LLMs to model individual decisions or collective behavior, as their imitation abilities are approximate at best.
5/30/2024

LLM Voting: Human Choices and AI Collective Decision Making
Joshua C. Yang, Damian Dailisan, Marcin Korecki, Carina I. Hausladen, Dirk Helbing
0
0
This paper investigates the voting behaviors of Large Language Models (LLMs), specifically GPT-4 and LLaMA-2, their biases, and how they align with human voting patterns. Our methodology involved using a dataset from a human voting experiment to establish a baseline for human preferences and a corresponding experiment with LLM agents. We observed that the methods used for voting input and the presentation of choices influence LLM voting behavior. We discovered that varying the persona can reduce some of these biases and enhance alignment with human choices. While the Chain-of-Thought approach did not improve prediction accuracy, it has potential for AI explainability in the voting process. We also identified a trade-off between preference diversity and alignment accuracy in LLMs, influenced by different temperature settings. Our findings indicate that LLMs may lead to less diverse collective outcomes and biased assumptions when used in voting scenarios, emphasizing the importance of cautious integration of LLMs into democratic processes.
5/16/2024

Nicer Than Humans: How do Large Language Models Behave in the Prisoner's Dilemma?
Nicol'o Fontana, Francesco Pierri, Luca Maria Aiello
0
0
The behavior of Large Language Models (LLMs) as artificial social agents is largely unexplored, and we still lack extensive evidence of how these agents react to simple social stimuli. Testing the behavior of AI agents in classic Game Theory experiments provides a promising theoretical framework for evaluating the norms and values of these agents in archetypal social situations. In this work, we investigate the cooperative behavior of Llama2 when playing the Iterated Prisoner's Dilemma against random adversaries displaying various levels of hostility. We introduce a systematic methodology to evaluate an LLM's comprehension of the game's rules and its capability to parse historical gameplay logs for decision-making. We conducted simulations of games lasting for 100 rounds, and analyzed the LLM's decisions in terms of dimensions defined in behavioral economics literature. We find that Llama2 tends not to initiate defection but it adopts a cautious approach towards cooperation, sharply shifting towards a behavior that is both forgiving and non-retaliatory only when the opponent reduces its rate of defection below 30%. In comparison to prior research on human participants, Llama2 exhibits a greater inclination towards cooperative behavior. Our systematic approach to the study of LLMs in game theoretical scenarios is a step towards using these simulations to inform practices of LLM auditing and alignment.
6/21/2024