A Survey on Human Preference Learning for Large Language Models
2406.11191
0
0

Abstract
The recent surge of versatile large language models (LLMs) largely depends on aligning increasingly capable foundation models with human intentions by preference learning, enhancing LLMs with excellent applicability and effectiveness in a wide range of contexts. Despite the numerous related studies conducted, a perspective on how human preferences are introduced into LLMs remains limited, which may prevent a deeper comprehension of the relationships between human preferences and LLMs as well as the realization of their limitations. In this survey, we review the progress in exploring human preference learning for LLMs from a preference-centered perspective, covering the sources and formats of preference feedback, the modeling and usage of preference signals, as well as the evaluation of the aligned LLMs. We first categorize the human feedback according to data sources and formats. We then summarize techniques for human preferences modeling and compare the advantages and disadvantages of different schools of models. Moreover, we present various preference usage methods sorted by the objectives to utilize human preference signals. Finally, we summarize some prevailing approaches to evaluate LLMs in terms of alignment with human intentions and discuss our outlooks on the human intention alignment for LLMs.
Create account to get full access
Overview
- This paper provides a comprehensive survey of the current state of research on human preference learning for large language models (LLMs).
- The review covers key areas such as aligning language models with human preferences, understanding the learning dynamics of human feedback alignment, and using LLMs to model human beliefs and preferences.
- The paper also discusses the potential for using self-generated preferences to align LLMs and the broader question of whether LLMs can learn human-like preferences.
Plain English Explanation
This paper looks at how researchers are trying to teach large language models (LLMs) to better understand and align with human preferences. LLMs are AI systems that can generate human-like text, but they don't always produce outputs that are aligned with what humans want or find acceptable.
The researchers review different approaches that have been explored to address this, such as:
- Aligning LLMs with Human Preferences: Finding ways to train LLMs to generate text that is more in line with human values and preferences.
- Understanding Feedback Dynamics: Studying how LLMs learn and adapt when provided with human feedback, to improve the alignment process.
- Modeling Human Beliefs and Preferences: Using LLMs themselves to better understand how humans think about preferences and morality.
- Self-Generated Preferences: Exploring whether LLMs can learn to produce their own preferences that are aligned with human values.
- Human-Like Preferences: Investigating whether LLMs can truly develop preferences that are similar to how humans form their own values and beliefs.
By summarizing the state of research in these areas, the paper provides a helpful overview of the key challenges and approaches involved in making LLMs behave in ways that are more useful and acceptable to humans.
Technical Explanation
The paper begins by providing background on the importance of aligning large language models (LLMs) with human preferences, as these models become increasingly powerful and ubiquitous. The authors highlight the risk of LLMs producing outputs that are misaligned with human values, and the need to develop techniques to address this.
The main part of the paper surveys the current research landscape across several key areas:
-
Aligning Language Models with Human Preferences: This section covers work on training LLMs to generate text that is more aligned with human values and preferences, using techniques like reward modeling and constrained optimization.
-
Understanding the Learning Dynamics of Alignment with Human Feedback: The authors review research investigating how LLMs adapt and learn when provided with human feedback, to better understand the process of preference alignment.
-
Aligning Large Language Models Using Self-Generated Preferences: This part examines efforts to have LLMs develop their own preferences that are inherently aligned with human values, without the need for external feedback.
-
Using LLMs to Model Beliefs and Preferences: The paper discusses research on leveraging the language modeling capabilities of LLMs to better understand how humans form their own beliefs and preferences.
-
Do Large Language Models Learn Human-Like Preferences?: The final section explores the fundamental question of whether LLMs can truly develop preferences that are analogous to human values and decision-making.
Throughout the technical explanation, the authors provide relevant citations to the key papers and research in each area.
Critical Analysis
The survey paper provides a comprehensive and insightful overview of the current state of research on human preference learning for large language models. The authors do a commendable job of covering the major approaches and challenges in this important and rapidly evolving field.
One potential limitation of the paper is that it focuses primarily on the technical aspects of the research, without delving too deeply into the broader ethical and societal implications of this work. As LLMs become more powerful and ubiquitous, it will be crucial to carefully consider the long-term consequences of successfully aligning these models with human preferences, and to ensure that the preferences being learned are truly reflective of societal values, rather than those of a limited set of researchers or stakeholders.
Additionally, the paper does not address the inherent difficulties in defining and measuring human preferences, which can be highly subjective, context-dependent, and evolving over time. Translating these complex and often ambiguous human preferences into a form that can be effectively learned by LLMs is a significant challenge that deserves further exploration.
Despite these minor limitations, the survey paper provides an invaluable resource for researchers and practitioners working in this field. By synthesizing the current state of the art, the authors have laid the groundwork for future advancements and highlighted the key areas that will require continued focus and innovation.
Conclusion
This comprehensive survey paper offers a detailed overview of the current research on human preference learning for large language models (LLMs). The authors cover a range of important topics, including aligning LLMs with human values, understanding the dynamics of human feedback, leveraging self-generated preferences, and exploring the potential for LLMs to develop human-like preferences.
By synthesizing the existing work in this rapidly evolving field, the paper provides a valuable resource for researchers and developers working to ensure that LLMs become more aligned with human needs and societal values. As these powerful AI systems continue to advance, the challenge of preference alignment will only grow in importance, and this survey lays the groundwork for addressing these critical issues.
While the technical details of the research are thoroughly covered, the paper also highlights the need to consider the broader ethical and societal implications of successfully aligning LLMs with human preferences. Ensuring that these preferences are truly reflective of diverse human values and not just those of a limited set of stakeholders will be a crucial consideration going forward.
Overall, this survey paper offers a comprehensive and insightful look at the current state of human preference learning for LLMs, setting the stage for continued advancements in this important area of AI research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Aligning language models with human preferences
Tomasz Korbak
0
0
Language models (LMs) trained on vast quantities of text data can acquire sophisticated skills such as generating summaries, answering questions or generating code. However, they also manifest behaviors that violate human preferences, e.g., they can generate offensive content, falsehoods or perpetuate social biases. In this thesis, I explore several approaches to aligning LMs with human preferences. First, I argue that aligning LMs can be seen as Bayesian inference: conditioning a prior (base, pretrained LM) on evidence about human preferences (Chapter 2). Conditioning on human preferences can be implemented in numerous ways. In Chapter 3, I investigate the relation between two approaches to finetuning pretrained LMs using feedback given by a scoring function: reinforcement learning from human feedback (RLHF) and distribution matching. I show that RLHF can be seen as a special case of distribution matching but distributional matching is strictly more general. In chapter 4, I show how to extend the distribution matching to conditional language models. Finally, in chapter 5 I explore a different root: conditioning an LM on human preferences already during pretraining. I show that involving human feedback from the very start tends to be more effective than using it only during supervised finetuning. Overall, these results highlight the room for alignment techniques different from and complementary to RLHF.
4/19/2024

Understanding the Learning Dynamics of Alignment with Human Feedback
Shawn Im, Yixuan Li
0
0
Aligning large language models (LLMs) with human intentions has become a critical task for safely deploying models in real-world systems. While existing alignment approaches have seen empirical success, theoretically understanding how these methods affect model behavior remains an open question. Our work provides an initial attempt to theoretically analyze the learning dynamics of human preference alignment. We formally show how the distribution of preference datasets influences the rate of model updates and provide rigorous guarantees on the training accuracy. Our theory also reveals an intricate phenomenon where the optimization is prone to prioritizing certain behaviors with higher preference distinguishability. We empirically validate our findings on contemporary LLMs and alignment tasks, reinforcing our theoretical insights and shedding light on considerations for future alignment approaches. Disclaimer: This paper contains potentially offensive text; reader discretion is advised.
4/17/2024
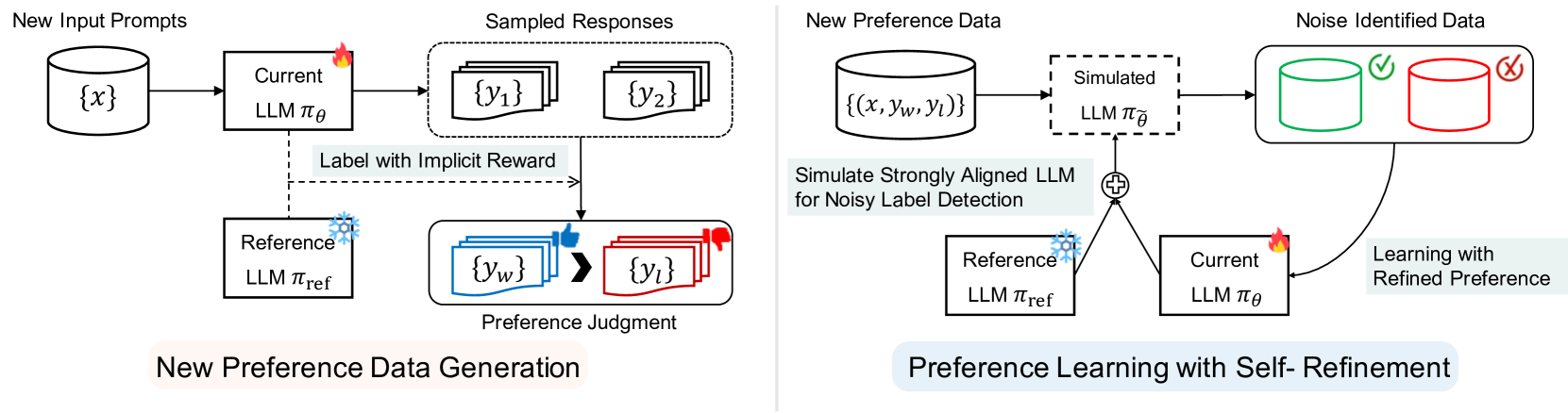
Aligning Large Language Models with Self-generated Preference Data
Dongyoung Kim, Kimin Lee, Jinwoo Shin, Jaehyung Kim
0
0
Aligning large language models (LLMs) with human preferences becomes a key component to obtaining state-of-the-art performance, but it yields a huge cost to construct a large human-annotated preference dataset. To tackle this problem, we propose a new framework that boosts the alignment of LLMs through Self-generated Preference data (Selfie) using only a very small amount of human-annotated preference data. Our key idea is leveraging the human prior knowledge within the small (seed) data and progressively improving the alignment of LLM, by iteratively generating the responses and learning from them with the self-annotated preference data. To be specific, we propose to derive the preference label from the logits of LLM to explicitly extract the model's inherent preference. Compared to the previous approaches using external reward models or implicit in-context learning, we observe that the proposed approach is significantly more effective. In addition, we introduce a noise-aware preference learning algorithm to mitigate the risk of low quality within generated preference data. Our experimental results demonstrate that the proposed framework significantly boosts the alignment of LLMs. For example, we achieve superior alignment performance on AlpacaEval 2.0 with only 3.3% of the ground-truth preference labels in the Ultrafeedback data compared to the cases using the entire data or state-of-the-art baselines.
6/10/2024

Using LLMs to Model the Beliefs and Preferences of Targeted Populations
Keiichi Namikoshi, Alex Filipowicz, David A. Shamma, Rumen Iliev, Candice L. Hogan, Nikos Arechiga
0
0
We consider the problem of aligning a large language model (LLM) to model the preferences of a human population. Modeling the beliefs, preferences, and behaviors of a specific population can be useful for a variety of different applications, such as conducting simulated focus groups for new products, conducting virtual surveys, and testing behavioral interventions, especially for interventions that are expensive, impractical, or unethical. Existing work has had mixed success using LLMs to accurately model human behavior in different contexts. We benchmark and evaluate two well-known fine-tuning approaches and evaluate the resulting populations on their ability to match the preferences of real human respondents on a survey of preferences for battery electric vehicles (BEVs). We evaluate our models against their ability to match population-wide statistics as well as their ability to match individual responses, and we investigate the role of temperature in controlling the trade-offs between these two. Additionally, we propose and evaluate a novel loss term to improve model performance on responses that require a numeric response.
4/1/2024