Do LLMs Really Adapt to Domains? An Ontology Learning Perspective

0

Sign in to get full access
Overview
- Explores whether large language models (LLMs) truly adapt to specific domains or if their performance is limited by inconsistencies in their knowledge representations
- Investigates this question from the perspective of ontology learning, which aims to extract structured knowledge from text
- Finds that while LLMs can leverage domain-specific knowledge, they struggle to learn coherent ontologies that capture the nuances of a given field
Plain English Explanation
The paper examines whether large language models (LLMs) can genuinely adapt to and master specific subject areas, or if their performance is ultimately constrained by fundamental limitations in how they represent knowledge. The researchers approach this by looking at ontology learning - the process of extracting structured conceptual models from text.
Their findings suggest that while LLMs can leverage domain-specific knowledge to a degree, they struggle to learn comprehensive and coherent ontologies that fully capture the nuances and relationships within a given field. This indicates that the adaptability of LLMs may be more limited than commonly assumed, and that their knowledge representations may not align well with real-world reality.
The research highlights the importance of enhancing LLM representations with ontological knowledge to improve their ability to reason about and apply domain-specific concepts.
Technical Explanation
The paper investigates whether large language models (LLMs) can truly adapt to and master specific domains, or if their performance is constrained by inherent limitations in how they represent knowledge. The researchers approach this question from the perspective of ontology learning - the task of extracting structured conceptual models (ontologies) from text.
They evaluate the ability of several prominent LLMs, including GPT-3 and BERT, to learn ontologies for specific domains such as biomedicine and finance. The experiment involves having the models generate ontology concepts and relationships from domain-specific corpora, and then assessing the coherence and completeness of the resulting ontologies.
The findings indicate that while the LLMs are able to leverage domain-relevant knowledge to a certain degree, they struggle to construct comprehensive and logically consistent ontologies that fully capture the nuanced conceptual structures of the target fields. The models exhibit a range of issues, including the introduction of contradictory or nonsensical relationships, the omission of key concepts, and the failure to appropriately organize the knowledge.
These results suggest that the adaptability of LLMs may be more limited than commonly assumed, and that their internal knowledge representations may not always align well with real-world conceptual structures. The researchers argue that enhancing LLM representations with explicit ontological knowledge could be a promising avenue for improving their reasoning capabilities within specific domains.
Critical Analysis
The paper provides a thoughtful and well-designed investigation into the limitations of LLMs in adapting to and representing domain-specific knowledge. The ontology learning task is a compelling and relevant lens through which to examine these issues, as it requires models to go beyond mere text generation and engage in a more structured form of knowledge extraction and organization.
One potential criticism is that the paper focuses primarily on a small number of prominent LLMs, and it's unclear how generalizable the findings are to the broader landscape of large language models. It would be helpful to see the analysis expanded to include a wider range of models, including more recent developments in the field.
Additionally, the paper does not delve deeply into the underlying causes of the LLMs' struggles in learning coherent ontologies. While the researchers provide some high-level speculation, a more detailed exploration of the mechanisms and biases within the models that lead to these issues could further strengthen the analysis.
Despite these minor limitations, the paper makes a valuable contribution to the ongoing discourse around the capabilities and limitations of large language models. The findings underscore the importance of continued research into enhancing LLM representations with more structured and ontological knowledge, to better align their reasoning with real-world conceptual frameworks.
Conclusion
This paper offers a thought-provoking investigation into the domain adaptability of large language models, using the lens of ontology learning as a means of evaluating their ability to capture and organize domain-specific knowledge. The key finding is that while LLMs can leverage relevant information to a degree, they struggle to construct coherent and comprehensive ontologies that fully reflect the nuanced conceptual structures of specific fields.
These results suggest that the adaptability of LLMs may be more limited than commonly assumed, and that their internal knowledge representations may not always align well with real-world reality. The paper highlights the need for continued research into enhancing LLM representations with explicit ontological knowledge, in order to improve their reasoning capabilities within specific domains and better align them with human conceptual frameworks.
Overall, this paper provides a valuable contribution to the ongoing discussion around the strengths and limitations of large language models, and the importance of exploring ways to address their inherent biases and inconsistencies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Do LLMs Really Adapt to Domains? An Ontology Learning Perspective
Huu Tan Mai, Cuong Xuan Chu, Heiko Paulheim
Large Language Models (LLMs) have demonstrated unprecedented prowess across various natural language processing tasks in various application domains. Recent studies show that LLMs can be leveraged to perform lexical semantic tasks, such as Knowledge Base Completion (KBC) or Ontology Learning (OL). However, it has not effectively been verified whether their success is due to their ability to reason over unstructured or semi-structured data, or their effective learning of linguistic patterns and senses alone. This unresolved question is particularly crucial when dealing with domain-specific data, where the lexical senses and their meaning can completely differ from what a LLM has learned during its training stage. This paper investigates the following question: Do LLMs really adapt to domains and remain consistent in the extraction of structured knowledge, or do they only learn lexical senses instead of reasoning? To answer this question and, we devise a controlled experiment setup that uses WordNet to synthesize parallel corpora, with English and gibberish terms. We examine the differences in the outputs of LLMs for each corpus in two OL tasks: relation extraction and taxonomy discovery. Empirical results show that, while adapting to the gibberish corpora, off-the-shelf LLMs do not consistently reason over semantic relationships between concepts, and instead leverage senses and their frame. However, fine-tuning improves the performance of LLMs on lexical semantic tasks even when the domain-specific terms are arbitrary and unseen during pre-training, hinting at the applicability of pre-trained LLMs for OL.
Read more7/30/2024
0
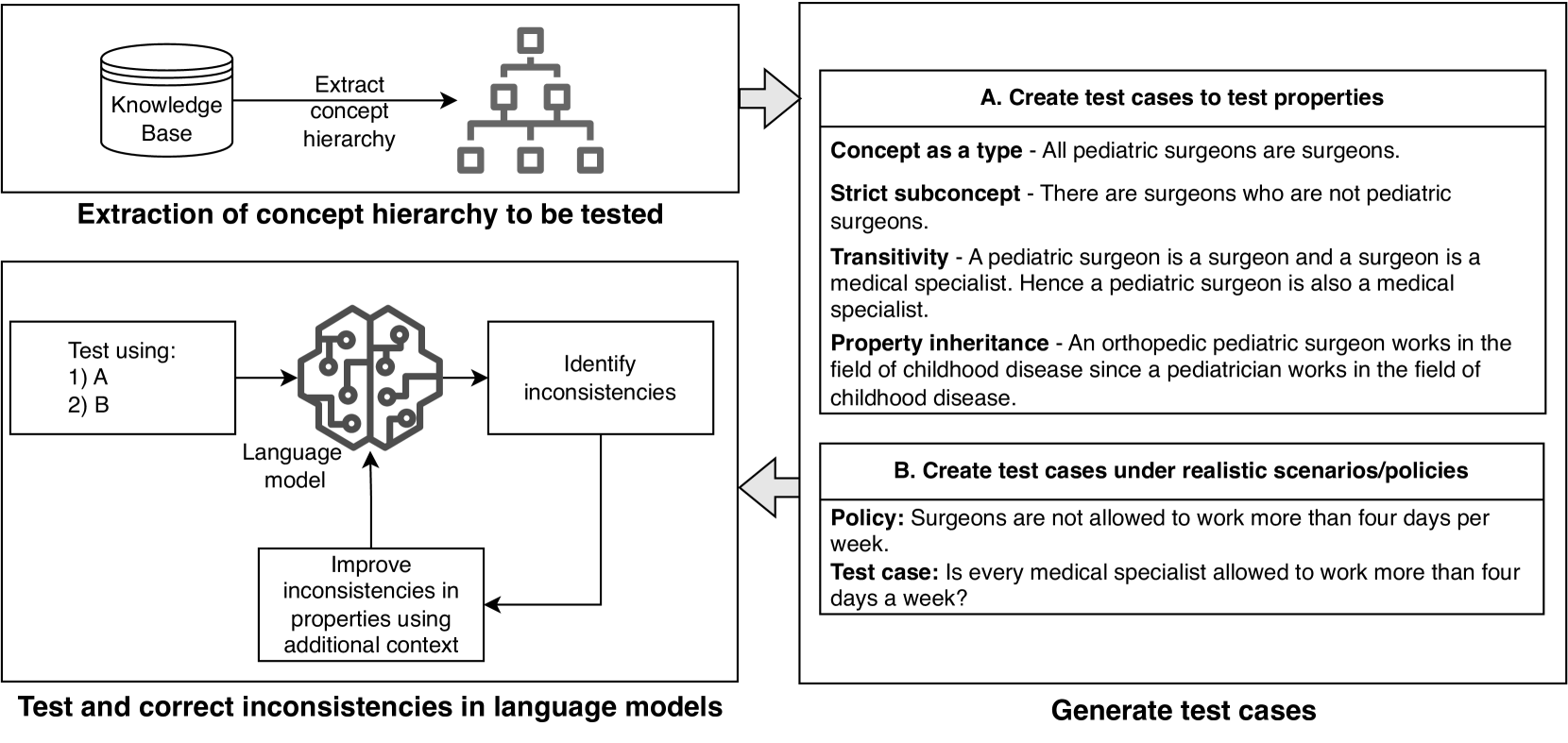
Reasoning about concepts with LLMs: Inconsistencies abound
Rosario Uceda-Sosa, Karthikeyan Natesan Ramamurthy, Maria Chang, Moninder Singh
The ability to summarize and organize knowledge into abstract concepts is key to learning and reasoning. Many industrial applications rely on the consistent and systematic use of concepts, especially when dealing with decision-critical knowledge. However, we demonstrate that, when methodically questioned, large language models (LLMs) often display and demonstrate significant inconsistencies in their knowledge. Computationally, the basic aspects of the conceptualization of a given domain can be represented as Is-A hierarchies in a knowledge graph (KG) or ontology, together with a few properties or axioms that enable straightforward reasoning. We show that even simple ontologies can be used to reveal conceptual inconsistencies across several LLMs. We also propose strategies that domain experts can use to evaluate and improve the coverage of key domain concepts in LLMs of various sizes. In particular, we have been able to significantly enhance the performance of LLMs of various sizes with openly available weights using simple knowledge-graph (KG) based prompting strategies.
Read more5/31/2024

0
Are Large Language Models a Good Replacement of Taxonomies?
Yushi Sun, Hao Xin, Kai Sun, Yifan Ethan Xu, Xiao Yang, Xin Luna Dong, Nan Tang, Lei Chen
Large language models (LLMs) demonstrate an impressive ability to internalize knowledge and answer natural language questions. Although previous studies validate that LLMs perform well on general knowledge while presenting poor performance on long-tail nuanced knowledge, the community is still doubtful about whether the traditional knowledge graphs should be replaced by LLMs. In this paper, we ask if the schema of knowledge graph (i.e., taxonomy) is made obsolete by LLMs. Intuitively, LLMs should perform well on common taxonomies and at taxonomy levels that are common to people. Unfortunately, there lacks a comprehensive benchmark that evaluates the LLMs over a wide range of taxonomies from common to specialized domains and at levels from root to leaf so that we can draw a confident conclusion. To narrow the research gap, we constructed a novel taxonomy hierarchical structure discovery benchmark named TaxoGlimpse to evaluate the performance of LLMs over taxonomies. TaxoGlimpse covers ten representative taxonomies from common to specialized domains with in-depth experiments of different levels of entities in this taxonomy from root to leaf. Our comprehensive experiments of eighteen state-of-the-art LLMs under three prompting settings validate that LLMs can still not well capture the knowledge of specialized taxonomies and leaf-level entities.
Read more6/21/2024
0
Large language models as oracles for instantiating ontologies with domain-specific knowledge
Giovanni Ciatto, Andrea Agiollo, Matteo Magnini, Andrea Omicini
Background. Endowing intelligent systems with semantic data commonly requires designing and instantiating ontologies with domain-specific knowledge. Especially in the early phases, those activities are typically performed manually by human experts possibly leveraging on their own experience. The resulting process is therefore time-consuming, error-prone, and often biased by the personal background of the ontology designer. Objective. To mitigate that issue, we propose a novel domain-independent approach to automatically instantiate ontologies with domain-specific knowledge, by leveraging on large language models (LLMs) as oracles. Method. Starting from (i) an initial schema composed by inter-related classes andproperties and (ii) a set of query templates, our method queries the LLM multi- ple times, and generates instances for both classes and properties from its replies. Thus, the ontology is automatically filled with domain-specific knowledge, compliant to the initial schema. As a result, the ontology is quickly and automatically enriched with manifold instances, which experts may consider to keep, adjust, discard, or complement according to their own needs and expertise. Contribution. We formalise our method in general way and instantiate it over various LLMs, as well as on a concrete case study. We report experiments rooted in the nutritional domain where an ontology of food meals and their ingredients is semi-automatically instantiated from scratch, starting from a categorisation of meals and their relationships. There, we analyse the quality of the generated ontologies and compare ontologies attained by exploiting different LLMs. Finally, we provide a SWOT analysis of the proposed method.
Read more4/8/2024