Large language models as oracles for instantiating ontologies with domain-specific knowledge
2404.04108
0
0
Abstract
Background. Endowing intelligent systems with semantic data commonly requires designing and instantiating ontologies with domain-specific knowledge. Especially in the early phases, those activities are typically performed manually by human experts possibly leveraging on their own experience. The resulting process is therefore time-consuming, error-prone, and often biased by the personal background of the ontology designer. Objective. To mitigate that issue, we propose a novel domain-independent approach to automatically instantiate ontologies with domain-specific knowledge, by leveraging on large language models (LLMs) as oracles. Method. Starting from (i) an initial schema composed by inter-related classes andproperties and (ii) a set of query templates, our method queries the LLM multi- ple times, and generates instances for both classes and properties from its replies. Thus, the ontology is automatically filled with domain-specific knowledge, compliant to the initial schema. As a result, the ontology is quickly and automatically enriched with manifold instances, which experts may consider to keep, adjust, discard, or complement according to their own needs and expertise. Contribution. We formalise our method in general way and instantiate it over various LLMs, as well as on a concrete case study. We report experiments rooted in the nutritional domain where an ontology of food meals and their ingredients is semi-automatically instantiated from scratch, starting from a categorisation of meals and their relationships. There, we analyse the quality of the generated ontologies and compare ontologies attained by exploiting different LLMs. Finally, we provide a SWOT analysis of the proposed method.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores how large language models (LLMs) can be used as "oracles" to help create and expand domain-specific ontologies, which are formal representations of knowledge in a particular field.
- The authors describe how LLMs can be leveraged to automatically generate candidate concepts, relations, and axioms to populate and enrich ontologies, drawing on the models' broad knowledge and language understanding capabilities.
- The paper presents several experiments demonstrating the feasibility and potential benefits of this approach, as well as discussing the challenges and limitations involved.
Plain English Explanation
Ontologies are structured ways of representing knowledge about a particular topic or field. They define the key concepts, the relationships between them, and the rules or axioms that govern how they interact. Ontologies are essential for powering various AI and data-driven applications, from search engines to knowledge graphs.
Traditionally, creating and maintaining ontologies has been a laborious, manual process that requires significant domain expertise. This paper explores a new approach that leverages the remarkable capabilities of large language models (LLMs) like GPT-3 and DALL-E.
The key idea is to use these LLMs as "oracles" - intelligent assistants that can automatically suggest new concepts, relationships, and rules to include in an ontology. By prompting the LLM with information about a particular domain, the model can draw on its broad knowledge to propose candidate ontology elements. This can significantly accelerate the ontology building process and help ensure the ontology covers relevant and up-to-date information.
The paper presents experiments where the authors used LLMs to expand existing ontologies in domains like physics and biology. The results demonstrate that LLMs can indeed generate meaningful, high-quality ontology components that domain experts can then review and refine.
Of course, there are challenges and limitations to this approach. LLMs can sometimes produce nonsensical or biased outputs, and their knowledge may not always be fully accurate or comprehensive. The paper discusses strategies for mitigating these issues, such as carefully curating the prompts and performing extensive validation.
Overall, this research suggests that large language models have tremendous potential to streamline and enhance the process of building domain-specific ontologies - a crucial step in powering the next generation of AI-driven applications and knowledge management systems.
Technical Explanation
The paper begins by providing background on ontologies, description logics, and the Semantic Web - the foundational technologies and frameworks that enable the formal representation and reasoning about conceptual knowledge. The authors explain how ontologies are typically constructed through a labor-intensive, manual process involving domain experts.
The core contribution of the paper is the proposal to leverage large language models (LLMs) as "oracles" to assist in the ontology instantiation process. The authors hypothesize that the broad knowledge and language understanding capabilities of LLMs can be harnessed to automatically generate candidate concepts, relations, and axioms to populate and expand domain-specific ontologies.
To test this idea, the researchers conducted several experiments. They started with existing ontologies in domains like physics and biology, and used prompts to query LLMs like GPT-3 for potential new ontology elements. The model outputs were then filtered, validated, and integrated into the ontologies by the researchers.
The results of these experiments demonstrate that LLMs can indeed generate meaningful, high-quality ontology components that are relevant and consistent with the target domains. The paper provides detailed quantitative and qualitative analyses of the generated content, as well as comparisons to manual ontology building approaches.
The authors also discuss the challenges and limitations of their approach. LLMs can sometimes produce nonsensical or biased outputs, and their knowledge may not always be fully accurate or comprehensive. To mitigate these issues, the researchers experimented with techniques like prompt engineering, output filtering, and iterative refinement.
Overall, the paper presents a novel and promising approach to leveraging the capabilities of large language models to assist in the construction and expansion of domain-specific ontologies. The authors argue that this could significantly streamline the ontology building process and help ensure the resulting knowledge representations are up-to-date and comprehensive.
Critical Analysis
The paper makes a compelling case for using large language models as "oracles" to support ontology instantiation and expansion. The experiments demonstrate that LLMs can indeed generate high-quality, relevant ontology components in a variety of domains. This is a promising result that could have significant implications for the field of knowledge representation and reasoning.
However, the authors acknowledge several key limitations and challenges that should be considered:
-
Accuracy and Reliability: While the LLM-generated content was generally of high quality, the authors note that the models can sometimes produce nonsensical or biased outputs. Ensuring the reliability and accuracy of the generated ontology elements remains an important challenge.
-
Knowledge Comprehensiveness: The authors point out that the knowledge captured by LLMs, while broad, may not be fully comprehensive or up-to-date, particularly for highly specialized or rapidly evolving domains. Relying solely on LLMs for ontology building could lead to gaps or omissions in the final knowledge representation.
-
Validation and Curation: The paper highlights the need for extensive validation and curation of the LLM-generated content by domain experts. This manual review process could limit the scalability and efficiency gains of the proposed approach.
-
Interpretability and Explainability: As with many AI systems, the inner workings of large language models can be opaque, making it difficult to understand and explain the reasoning behind the generated ontology elements. This lack of interpretability could be a concern for mission-critical applications.
These limitations and challenges suggest that while the LLM-based ontology instantiation approach is promising, it may need to be combined with other techniques and human oversight to ensure the resulting ontologies are reliable, comprehensive, and trustworthy. Further research is needed to address these issues and fully realize the potential of this approach.
Conclusion
This paper presents a novel and intriguing approach to leveraging the capabilities of large language models to assist in the construction and expansion of domain-specific ontologies. The experiments demonstrate that LLMs can generate high-quality, relevant ontology components that can significantly accelerate the ontology building process.
However, the authors also highlight several important challenges and limitations that must be addressed, such as ensuring the accuracy and reliability of the generated content, maintaining comprehensive domain knowledge, and providing interpretability and explainability.
Overall, this research suggests that large language models have tremendous potential to revolutionize the field of knowledge representation and reasoning. By using LLMs as "oracles" to propose and expand ontologies, we may be able to build more comprehensive, up-to-date, and easily maintainable knowledge representations to power the next generation of AI-driven applications and knowledge management systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
On the Use of Large Language Models to Generate Capability Ontologies
Luis Miguel Vieira da Silva, Aljosha Kocher, Felix Gehlhoff, Alexander Fay
0
0
Capability ontologies are increasingly used to model functionalities of systems or machines. The creation of such ontological models with all properties and constraints of capabilities is very complex and can only be done by ontology experts. However, Large Language Models (LLMs) have shown that they can generate machine-interpretable models from natural language text input and thus support engineers / ontology experts. Therefore, this paper investigates how LLMs can be used to create capability ontologies. We present a study with a series of experiments in which capabilities with varying complexities are generated using different prompting techniques and with different LLMs. Errors in the generated ontologies are recorded and compared. To analyze the quality of the generated ontologies, a semi-automated approach based on RDF syntax checking, OWL reasoning, and SHACL constraints is used. The results of this study are very promising because even for complex capabilities, the generated ontologies are almost free of errors.
4/30/2024
Towards Complex Ontology Alignment using Large Language Models
Reihaneh Amini, Sanaz Saki Norouzi, Pascal Hitzler, Reza Amini
0
0
Ontology alignment, a critical process in the Semantic Web for detecting relationships between different ontologies, has traditionally focused on identifying so-called simple 1-to-1 relationships through class labels and properties comparison. The more practically useful exploration of more complex alignments remains a hard problem to automate, and as such is largely underexplored, i.e. in application practice it is usually done manually by ontology and domain experts. Recently, the surge in Natural Language Processing (NLP) capabilities, driven by advancements in Large Language Models (LLMs), presents new opportunities for enhancing ontology engineering practices, including ontology alignment tasks. This paper investigates the application of LLM technologies to tackle the complex ontology alignment challenge. Leveraging a prompt-based approach and integrating rich ontology content so-called modules our work constitutes a significant advance towards automating the complex alignment task.
4/17/2024
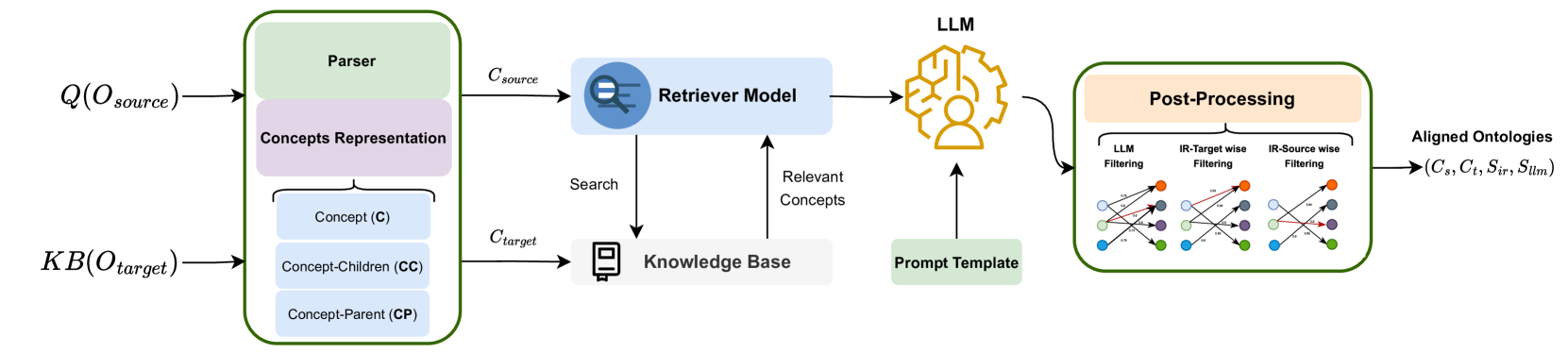
LLMs4OM: Matching Ontologies with Large Language Models
Hamed Babaei Giglou, Jennifer D'Souza, Felix Engel, Soren Auer
0
0
Ontology Matching (OM), is a critical task in knowledge integration, where aligning heterogeneous ontologies facilitates data interoperability and knowledge sharing. Traditional OM systems often rely on expert knowledge or predictive models, with limited exploration of the potential of Large Language Models (LLMs). We present the LLMs4OM framework, a novel approach to evaluate the effectiveness of LLMs in OM tasks. This framework utilizes two modules for retrieval and matching, respectively, enhanced by zero-shot prompting across three ontology representations: concept, concept-parent, and concept-children. Through comprehensive evaluations using 20 OM datasets from various domains, we demonstrate that LLMs, under the LLMs4OM framework, can match and even surpass the performance of traditional OM systems, particularly in complex matching scenarios. Our results highlight the potential of LLMs to significantly contribute to the field of OM.
4/24/2024
💬
Large Language Models as Planning Domain Generators
James Oswald, Kavitha Srinivas, Harsha Kokel, Junkyu Lee, Michael Katz, Shirin Sohrabi
0
0
Developing domain models is one of the few remaining places that require manual human labor in AI planning. Thus, in order to make planning more accessible, it is desirable to automate the process of domain model generation. To this end, we investigate if large language models (LLMs) can be used to generate planning domain models from simple textual descriptions. Specifically, we introduce a framework for automated evaluation of LLM-generated domains by comparing the sets of plans for domain instances. Finally, we perform an empirical analysis of 7 large language models, including coding and chat models across 9 different planning domains, and under three classes of natural language domain descriptions. Our results indicate that LLMs, particularly those with high parameter counts, exhibit a moderate level of proficiency in generating correct planning domains from natural language descriptions. Our code is available at https://github.com/IBM/NL2PDDL.
5/14/2024