Do Multimodal Foundation Models Understand Enterprise Workflows? A Benchmark for Business Process Management Tasks

0
Sign in to get full access
Overview
- This paper proposes a benchmark to evaluate how well multimodal foundation models (e.g., CLIP, VisualWebBench) can understand and perform business process management (BPM) tasks.
- The benchmark covers a range of BPM tasks, including text-to-image generation, image-to-text captioning, and question-answering on business process diagrams.
- The paper evaluates several multimodal models on this benchmark and provides insights into their strengths and limitations in understanding enterprise workflows.
Plain English Explanation
The paper is looking at how well advanced AI models, called multimodal foundation models, can understand and perform tasks related to business processes. Business processes are the series of steps and activities that organizations use to get work done, like processing customer orders or approving expense reports.
The researchers created a benchmark, which is a standardized test, to evaluate these AI models on different BPM tasks. The tasks include generating images from text descriptions, captioning images of business processes, and answering questions about process diagrams.
By testing the models on this benchmark, the researchers can see how well the models understand the language, visuals, and logic of business processes. This is important because these models could potentially be used to automate or assist with business process management in the future.
The paper presents the results of evaluating several multimodal models on this benchmark and discusses the insights gained. It helps us understand the current capabilities and limitations of these advanced AI models when it comes to comprehending the complex workflows and activities that occur in businesses and organizations.
Technical Explanation
The paper introduces a new benchmark for evaluating multimodal foundation models on various business process management (BPM) tasks. The benchmark consists of several tasks that assess the models' ability to understand and reason about enterprise workflows, including:
- Text-to-image generation: Generating images from text descriptions of business process steps or activities.
- Image-to-text captioning: Describing the content and steps of a business process diagram or workflow visualization.
- Question-answering on process diagrams: Answering questions about the logic, content, and relationships in a given business process diagram.
The researchers evaluate the performance of several multimodal foundation models, such as CLIP and VisualWebBench, on this benchmark. They find that while these models exhibit impressive capabilities on the tasks, they also have significant limitations in comprehending the nuances and complexities of enterprise-level business processes.
The paper also discusses the potential applications of these models in automating or assisting with BPM tasks, as well as the need for further research to develop models that can better understand and reason about multimodal business data and automatically generate business workflows.
Critical Analysis
The paper provides a valuable contribution to the field of business process management by introducing a comprehensive benchmark to assess the capabilities of multimodal foundation models in understanding enterprise workflows. The researchers have thoughtfully designed the benchmark to cover a range of relevant BPM tasks, which allows for a nuanced evaluation of the models' strengths and weaknesses.
One potential limitation of the study is the scope of the benchmark, which may not capture the full breadth of activities and complexities encountered in real-world business processes. Additionally, the paper does not delve deeply into the specific reasons for the models' performance on certain tasks, which could provide further insights for future research and model development.
Furthermore, the paper could have discussed the ethical considerations and potential risks associated with deploying these models in enterprise settings, such as concerns around data privacy, bias, and the impact on human workers. Addressing these issues would help readers understand the broader implications of this research.
Despite these minor limitations, the paper makes a significant contribution by highlighting the current capabilities and limitations of multimodal foundation models in the context of business process management. This work serves as an important step towards developing more advanced AI systems that can effectively support and automate enterprise workflows.
Conclusion
This paper presents a comprehensive benchmark for evaluating how well multimodal foundation models can understand and perform business process management tasks. The results reveal that while these advanced AI models exhibit impressive capabilities, they also have significant limitations in comprehending the nuances and complexities of enterprise-level workflows.
The insights gained from this research can inform the development of future AI systems that are better equipped to assist with and automate various BPM activities, ultimately improving the efficiency and effectiveness of business operations. However, it also highlights the need for further advancements in multimodal understanding and reasoning about diverse business data to fully realize the potential of these technologies in enterprise settings.
Overall, this paper makes an important contribution to the ongoing efforts to leverage machine learning and AI for business process management, paving the way for more intelligent and effective enterprise-wide automation and decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Do Multimodal Foundation Models Understand Enterprise Workflows? A Benchmark for Business Process Management Tasks
Michael Wornow, Avanika Narayan, Ben Viggiano, Ishan S. Khare, Tathagat Verma, Tibor Thompson, Miguel Angel Fuentes Hernandez, Sudharsan Sundar, Chloe Trujillo, Krrish Chawla, Rongfei Lu, Justin Shen, Divya Nagaraj, Joshua Martinez, Vardhan Agrawal, Althea Hudson, Nigam H. Shah, Christopher Re
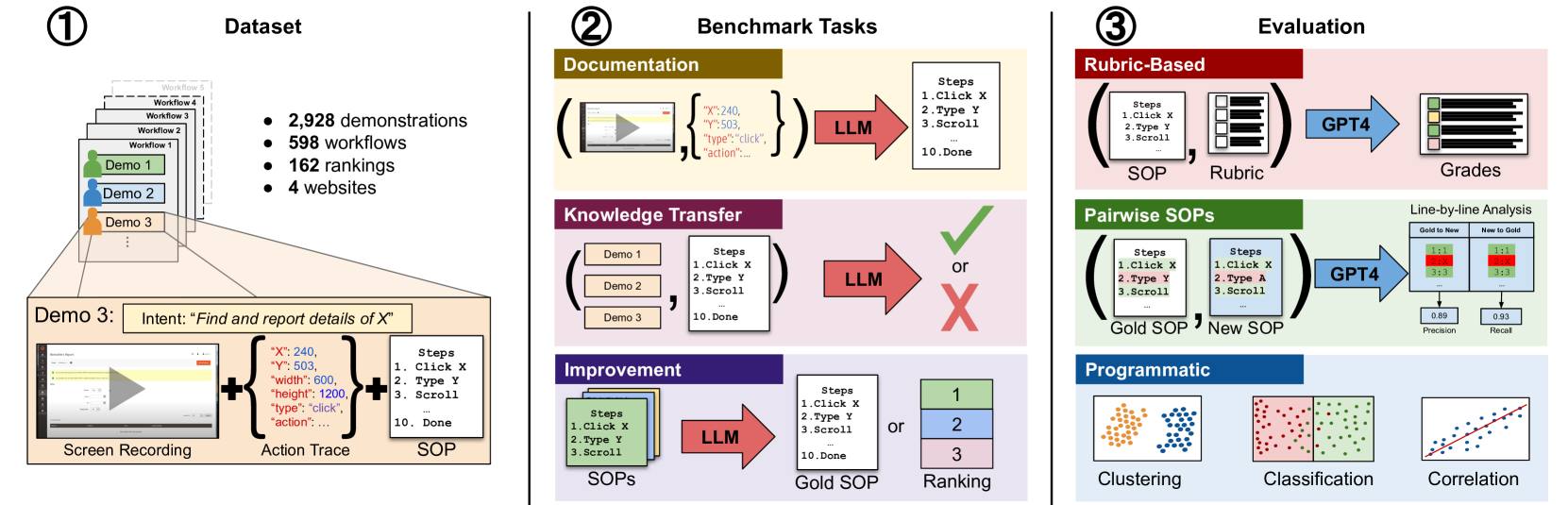
Existing ML benchmarks lack the depth and diversity of annotations needed for evaluating models on business process management (BPM) tasks. BPM is the practice of documenting, measuring, improving, and automating enterprise workflows. However, research has focused almost exclusively on one task - full end-to-end automation using agents based on multimodal foundation models (FMs) like GPT-4. This focus on automation ignores the reality of how most BPM tools are applied today - simply documenting the relevant workflow takes 60% of the time of the typical process optimization project. To address this gap we present WONDERBREAD, the first benchmark for evaluating multimodal FMs on BPM tasks beyond automation. Our contributions are: (1) a dataset containing 2928 documented workflow demonstrations; (2) 6 novel BPM tasks sourced from real-world applications ranging from workflow documentation to knowledge transfer to process improvement; and (3) an automated evaluation harness. Our benchmark shows that while state-of-the-art FMs can automatically generate documentation (e.g. recalling 88% of the steps taken in a video demonstration of a workflow), they struggle to re-apply that knowledge towards finer-grained validation of workflow completion (F1 < 0.3). We hope WONDERBREAD encourages the development of more human-centered AI tooling for enterprise applications and furthers the exploration of multimodal FMs for the broader universe of BPM tasks. We publish our dataset and experiments here: https://github.com/HazyResearch/wonderbread
Read more6/21/2024
0
Automating the Enterprise with Foundation Models
Michael Wornow, Avanika Narayan, Krista Opsahl-Ong, Quinn McIntyre, Nigam H. Shah, Christopher Re
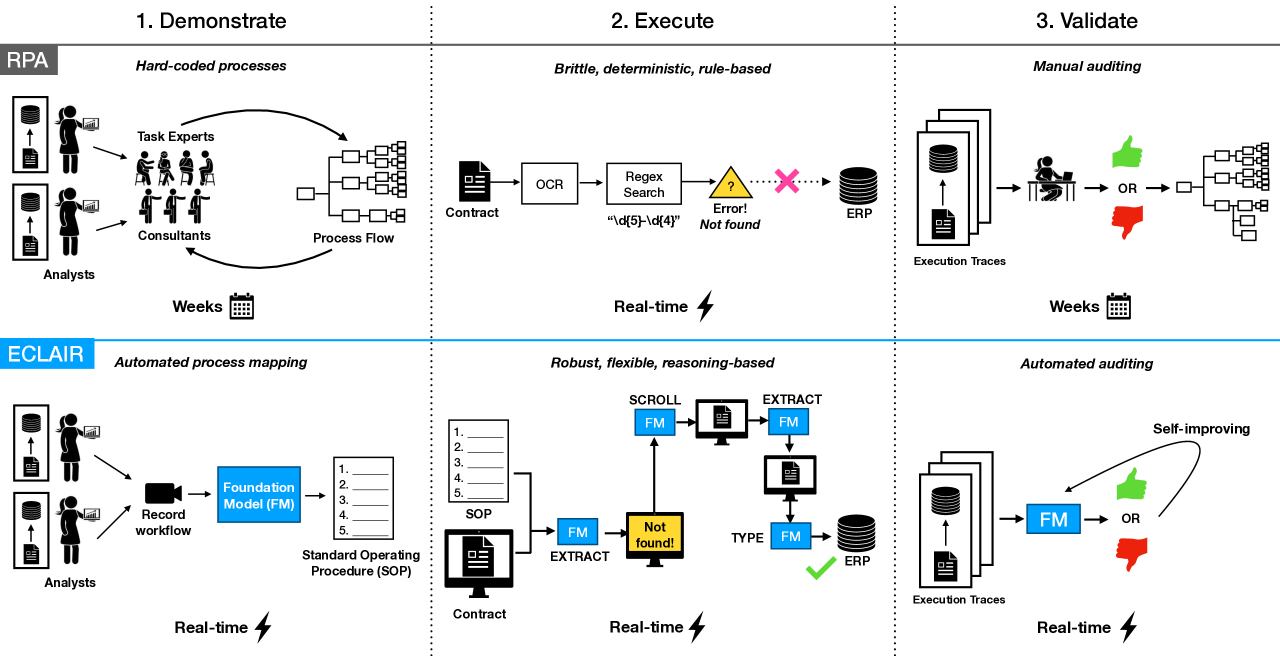
Automating enterprise workflows could unlock $4 trillion/year in productivity gains. Despite being of interest to the data management community for decades, the ultimate vision of end-to-end workflow automation has remained elusive. Current solutions rely on process mining and robotic process automation (RPA), in which a bot is hard-coded to follow a set of predefined rules for completing a workflow. Through case studies of a hospital and large B2B enterprise, we find that the adoption of RPA has been inhibited by high set-up costs (12-18 months), unreliable execution (60% initial accuracy), and burdensome maintenance (requiring multiple FTEs). Multimodal foundation models (FMs) such as GPT-4 offer a promising new approach for end-to-end workflow automation given their generalized reasoning and planning abilities. To study these capabilities we propose ECLAIR, a system to automate enterprise workflows with minimal human supervision. We conduct initial experiments showing that multimodal FMs can address the limitations of traditional RPA with (1) near-human-level understanding of workflows (93% accuracy on a workflow understanding task) and (2) instant set-up with minimal technical barrier (based solely on a natural language description of a workflow, ECLAIR achieves end-to-end completion rates of 40%). We identify human-AI collaboration, validation, and self-improvement as open challenges, and suggest ways they can be solved with data management techniques. Code is available at: https://github.com/HazyResearch/eclair-agents
Read more5/8/2024

0
Leveraging Large Language Models for Enhanced Process Model Comprehension
Humam Kourani, Alessandro Berti, Jasmin Hennrich, Wolfgang Kratsch, Robin Weidlich, Chiao-Yun Li, Ahmad Arslan, Daniel Schuster, Wil M. P. van der Aalst
In Business Process Management (BPM), effectively comprehending process models is crucial yet poses significant challenges, particularly as organizations scale and processes become more complex. This paper introduces a novel framework utilizing the advanced capabilities of Large Language Models (LLMs) to enhance the interpretability of complex process models. We present different methods for abstracting business process models into a format accessible to LLMs, and we implement advanced prompting strategies specifically designed to optimize LLM performance within our framework. Additionally, we present a tool, AIPA, that implements our proposed framework and allows for conversational process querying. We evaluate our framework and tool by i) an automatic evaluation comparing different LLMs, model abstractions, and prompting strategies and ii) a user study designed to assess AIPA's effectiveness comprehensively. Results demonstrate our framework's ability to improve the accessibility and interpretability of process models, pioneering new pathways for integrating AI technologies into the BPM field.
Read more9/23/2024
🤖
0
New!A Survey on Multimodal Benchmarks: In the Era of Large AI Models
Lin Li, Guikun Chen, Hanrong Shi, Jun Xiao, Long Chen
The rapid evolution of Multimodal Large Language Models (MLLMs) has brought substantial advancements in artificial intelligence, significantly enhancing the capability to understand and generate multimodal content. While prior studies have largely concentrated on model architectures and training methodologies, a thorough analysis of the benchmarks used for evaluating these models remains underexplored. This survey addresses this gap by systematically reviewing 211 benchmarks that assess MLLMs across four core domains: understanding, reasoning, generation, and application. We provide a detailed analysis of task designs, evaluation metrics, and dataset constructions, across diverse modalities. We hope that this survey will contribute to the ongoing advancement of MLLM research by offering a comprehensive overview of benchmarking practices and identifying promising directions for future work. An associated GitHub repository collecting the latest papers is available.
Read more9/30/2024