A Survey on Multimodal Benchmarks: In the Era of Large AI Models

0
🤖
Sign in to get full access
Overview
- Rapid evolution of Multimodal Large Language Models (MLLMs) has significantly enhanced AI capabilities for understanding and generating multimodal content.
- Prior studies have focused on model architectures and training methodologies, but a thorough analysis of benchmarks used for evaluating these models remains underexplored.
- This survey addresses this gap by systematically reviewing 211 benchmarks that assess MLLMs across four core domains: understanding, reasoning, generation, and application.
- The survey provides a detailed analysis of task designs, evaluation metrics, and dataset constructions across diverse modalities.
- The aim is to contribute to the advancement of MLLM research by offering a comprehensive overview of benchmarking practices and identifying promising directions for future work.
Plain English Explanation
Multimodal Large Language Models (MLLMs) are a type of artificial intelligence (AI) system that can understand and generate content across multiple forms of media, such as text, images, and audio. These models have rapidly improved in recent years, significantly enhancing AI's capabilities in this area.
While previous research has focused on the technical details of how these models are designed and trained, this survey takes a step back to examine the benchmarks, or tests, that are used to evaluate the performance of MLLMs. The researchers systematically reviewed 211 different benchmarks that assess MLLMs in four key areas: understanding (how well the models can comprehend multimodal information), reasoning (how well they can draw insights and make decisions), generation (how well they can create new multimodal content), and application (how well they can be used in real-world tasks).
By analyzing these benchmarks in detail, the researchers hope to provide a comprehensive overview of the current state of MLLM evaluation and identify promising directions for future research and development in this field. This information could help drive further advancements in multimodal AI and its applications.
Technical Explanation
The survey begins by reviewing the rapid progress of Multimodal Large Language Models (MLLMs), which have significantly enhanced the ability of artificial intelligence systems to understand and generate content across multiple modalities, such as text, images, and audio.
While previous studies have primarily focused on the model architectures and training methodologies of these models, the researchers identified a gap in the thorough analysis of the benchmarks used to evaluate MLLM performance.
To address this, the survey systematically reviewed 211 benchmarks that assess MLLMs across four core domains: understanding, reasoning, generation, and application. For each benchmark, the researchers analyzed the task designs, evaluation metrics, and dataset constructions, considering the diverse modalities involved.
The aim of this comprehensive survey is to contribute to the ongoing advancement of MLLM research by providing a thorough overview of current benchmarking practices and identifying promising directions for future work in this rapidly evolving field of artificial intelligence.
Critical Analysis
The survey provides a valuable and comprehensive review of the current state of benchmarking practices for Multimodal Large Language Models (MLLMs). By systematically analyzing 211 benchmarks across four core domains, the researchers offer a detailed and objective assessment of the various task designs, evaluation metrics, and dataset constructions used to assess MLLM performance.
One potential limitation of the survey is that it does not delve deeply into the specific strengths and weaknesses of individual benchmarks or the implications of the observed trends. While the researchers identify promising directions for future research, they could have provided more critical analysis or recommendations for improving benchmark design and evaluation.
Additionally, the survey focuses primarily on the technical aspects of MLLM benchmarking, without exploring the broader societal implications or potential biases inherent in the benchmarks and datasets used. Considering the growing importance of these models in real-world applications, a more holistic evaluation that considers ethical and fairness concerns would be a valuable addition to this research.
Overall, this survey represents a significant contribution to the understanding of MLLM benchmarking practices and lays the groundwork for further advancements in the field. By encouraging readers to think critically about the research and its limitations, the survey could inspire more in-depth investigations and discussions around the development and deployment of these powerful AI systems.
Conclusion
This comprehensive survey on Multimodal Large Language Model (MLLM) benchmarking practices offers a valuable overview of the current state of the field. By systematically reviewing 211 benchmarks across four core domains, the researchers provide insight into the task designs, evaluation metrics, and dataset constructions used to assess the performance of these rapidly evolving AI models.
The survey's findings contribute to the ongoing advancement of MLLM research by highlighting promising directions for future work, such as exploring more diverse modalities and real-world applications. Additionally, the critical analysis encourages readers to think deeply about the limitations and potential biases inherent in the benchmarking processes, which is crucial as these models become increasingly integrated into various aspects of society.
Overall, this survey represents an important step in understanding the current state of MLLM evaluation and lays the foundation for further research and development in this rapidly progressing field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
A Survey on Multimodal Benchmarks: In the Era of Large AI Models
Lin Li, Guikun Chen, Hanrong Shi, Jun Xiao, Long Chen
The rapid evolution of Multimodal Large Language Models (MLLMs) has brought substantial advancements in artificial intelligence, significantly enhancing the capability to understand and generate multimodal content. While prior studies have largely concentrated on model architectures and training methodologies, a thorough analysis of the benchmarks used for evaluating these models remains underexplored. This survey addresses this gap by systematically reviewing 211 benchmarks that assess MLLMs across four core domains: understanding, reasoning, generation, and application. We provide a detailed analysis of task designs, evaluation metrics, and dataset constructions, across diverse modalities. We hope that this survey will contribute to the ongoing advancement of MLLM research by offering a comprehensive overview of benchmarking practices and identifying promising directions for future work. An associated GitHub repository collecting the latest papers is available.
Read more9/30/2024

0
A Survey on Benchmarks of Multimodal Large Language Models
Jian Li, Weiheng Lu, Hao Fei, Meng Luo, Ming Dai, Min Xia, Yizhang Jin, Zhenye Gan, Ding Qi, Chaoyou Fu, Ying Tai, Wankou Yang, Yabiao Wang, Chengjie Wang
Multimodal Large Language Models (MLLMs) are gaining increasing popularity in both academia and industry due to their remarkable performance in various applications such as visual question answering, visual perception, understanding, and reasoning. Over the past few years, significant efforts have been made to examine MLLMs from multiple perspectives. This paper presents a comprehensive review of 200 benchmarks and evaluations for MLLMs, focusing on (1)perception and understanding, (2)cognition and reasoning, (3)specific domains, (4)key capabilities, and (5)other modalities. Finally, we discuss the limitations of the current evaluation methods for MLLMs and explore promising future directions. Our key argument is that evaluation should be regarded as a crucial discipline to support the development of MLLMs better. For more details, please visit our GitHub repository: https://github.com/swordlidev/Evaluation-Multimodal-LLMs-Survey.
Read more9/9/2024
0
A Survey on Evaluation of Multimodal Large Language Models
Jiaxing Huang, Jingyi Zhang
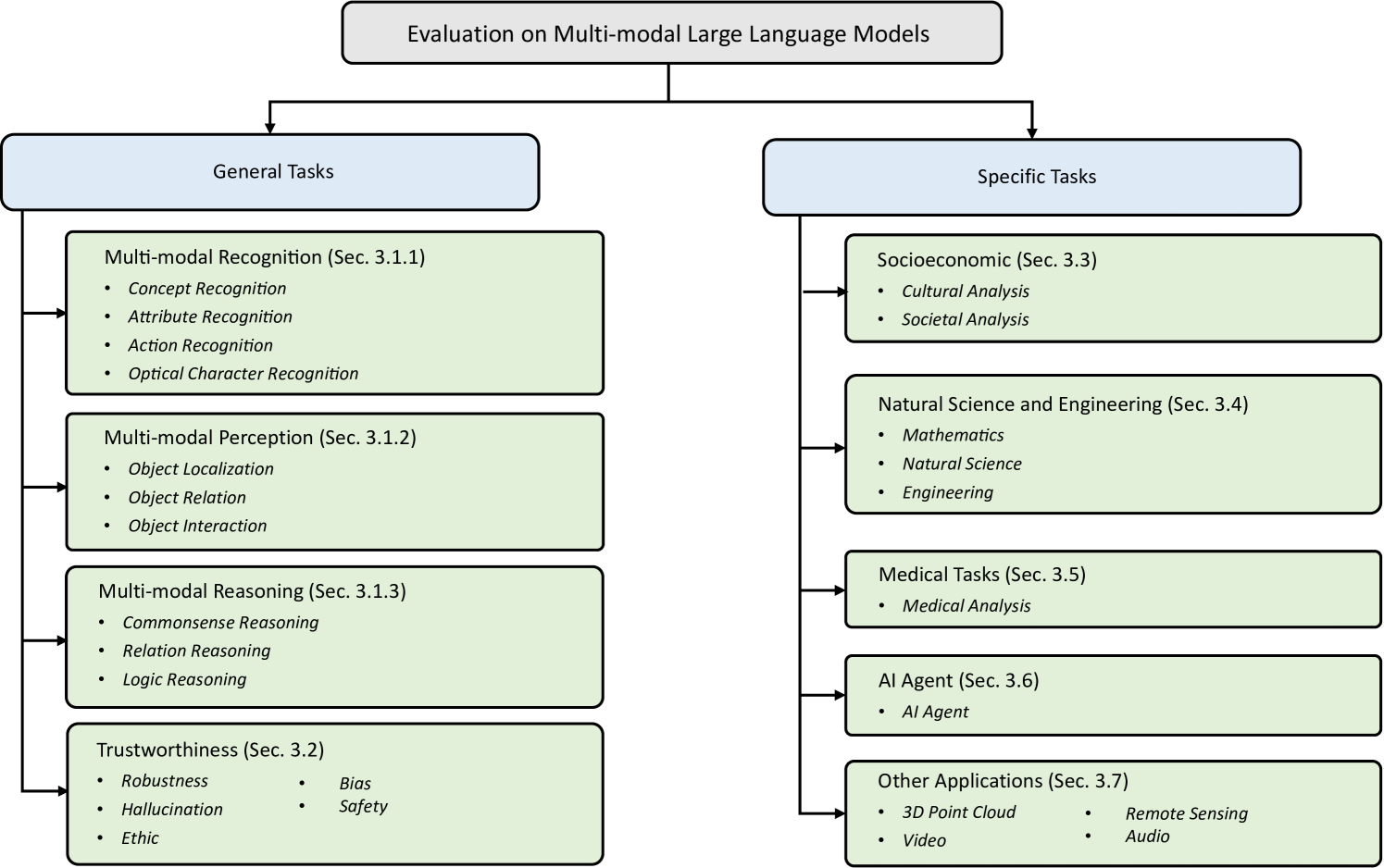
Multimodal Large Language Models (MLLMs) mimic human perception and reasoning system by integrating powerful Large Language Models (LLMs) with various modality encoders (e.g., vision, audio), positioning LLMs as the brain and various modality encoders as sensory organs. This framework endows MLLMs with human-like capabilities, and suggests a potential pathway towards achieving artificial general intelligence (AGI). With the emergence of all-round MLLMs like GPT-4V and Gemini, a multitude of evaluation methods have been developed to assess their capabilities across different dimensions. This paper presents a systematic and comprehensive review of MLLM evaluation methods, covering the following key aspects: (1) the background of MLLMs and their evaluation; (2) what to evaluate that reviews and categorizes existing MLLM evaluation tasks based on the capabilities assessed, including general multimodal recognition, perception, reasoning and trustworthiness, and domain-specific applications such as socioeconomic, natural sciences and engineering, medical usage, AI agent, remote sensing, video and audio processing, 3D point cloud analysis, and others; (3) where to evaluate that summarizes MLLM evaluation benchmarks into general and specific benchmarks; (4) how to evaluate that reviews and illustrates MLLM evaluation steps and metrics; Our overarching goal is to provide valuable insights for researchers in the field of MLLM evaluation, thereby facilitating the development of more capable and reliable MLLMs. We emphasize that evaluation should be regarded as a critical discipline, essential for advancing the field of MLLMs.
Read more8/29/2024

0
A Comprehensive Review of Multimodal Large Language Models: Performance and Challenges Across Different Tasks
Jiaqi Wang, Hanqi Jiang, Yiheng Liu, Chong Ma, Xu Zhang, Yi Pan, Mengyuan Liu, Peiran Gu, Sichen Xia, Wenjun Li, Yutong Zhang, Zihao Wu, Zhengliang Liu, Tianyang Zhong, Bao Ge, Tuo Zhang, Ning Qiang, Xintao Hu, Xi Jiang, Xin Zhang, Wei Zhang, Dinggang Shen, Tianming Liu, Shu Zhang
In an era defined by the explosive growth of data and rapid technological advancements, Multimodal Large Language Models (MLLMs) stand at the forefront of artificial intelligence (AI) systems. Designed to seamlessly integrate diverse data types-including text, images, videos, audio, and physiological sequences-MLLMs address the complexities of real-world applications far beyond the capabilities of single-modality systems. In this paper, we systematically sort out the applications of MLLM in multimodal tasks such as natural language, vision, and audio. We also provide a comparative analysis of the focus of different MLLMs in the tasks, and provide insights into the shortcomings of current MLLMs, and suggest potential directions for future research. Through these discussions, this paper hopes to provide valuable insights for the further development and application of MLLM.
Read more8/6/2024