Do Pre-trained Models Benefit Equally in Continual Learning?

0
✅
Sign in to get full access
Overview
- Existing continual learning (CL) algorithms focus on training models from scratch, but they perform poorly in real-world scenarios.
- This paper advocates for the systematic introduction of pre-training to CL, which can help transfer knowledge to downstream tasks.
- The paper explores the complexity of exploiting pre-trained models for CL, including the interaction between pre-trained models, CL algorithms, and CL scenarios.
- Interestingly, improvements in CL algorithms from pre-training are inconsistent, and a previously underperforming algorithm can become state-of-the-art when starting from a pre-trained model.
- The paper makes several other important observations, such as the benefits of less regularization and the limitations of stronger pre-trained models.
Plain English Explanation
Continual learning (CL) is the ability of AI systems to learn new tasks or information without forgetting what they've learned before. Most existing CL algorithms focus on training models from scratch, but these models often struggle in real-world scenarios.
This paper suggests that we should systematically incorporate pre-training into CL. Pre-training is a common technique in AI where a model is first trained on a large, general dataset and then fine-tuned for a specific task. The paper argues that pre-training could help CL models transfer knowledge more effectively to new tasks.
The paper explores the complexities of using pre-trained models for CL. It looks at how the choice of pre-trained model, the CL algorithm, and the CL scenario all interact to impact performance. Interestingly, the paper finds that a CL algorithm that performs poorly when trained from scratch can become highly competitive when starting from a pre-trained model. This suggests that the current practice of comparing CL methods in a from-scratch setting may not accurately reflect their real-world potential.
The paper also makes several other observations. For example, CL algorithms that use less regularization (constraints on the model) tend to benefit more from pre-training. Additionally, a stronger pre-trained model, like the CLIP model, does not necessarily guarantee better improvements in CL performance.
Based on these findings, the paper introduces a simple yet effective CL baseline that uses minimal regularization and leverages a beneficial pre-trained model. The researchers recommend that this baseline be included in future CL algorithm development, as it has shown state-of-the-art performance.
Technical Explanation
The paper starts by highlighting the limitations of existing continual learning (CL) algorithms, which are primarily designed for training models from scratch. Despite their impressive performance on artificial benchmarks, these algorithms struggle in real-world scenarios.
To address this, the paper advocates for the systematic introduction of pre-training to CL. Pre-training is a well-established technique for transferring knowledge from large, general datasets to downstream tasks, but it has been largely underexplored in the CL community.
The core of the paper's investigation is the multifaceted complexity of exploiting pre-trained models for CL. The authors examine this complexity along three key axes: pre-trained models, CL algorithms, and CL scenarios.
One of the most intriguing findings is that improvements in CL algorithms from pre-training are highly inconsistent. The paper shows that a previously underperforming CL algorithm can become competitive or even state-of-the-art when all algorithms start from a pre-trained model. This suggests that the current practice of comparing CL methods in a from-scratch setting may not accurately reflect their true potential.
The paper also makes several other important observations. For example, CL algorithms that use less regularization tend to benefit more from a pre-trained model. Additionally, the authors find that a stronger pre-trained model, such as CLIP, does not necessarily guarantee better improvements in CL performance.
Based on these insights, the paper introduces a simple yet effective CL baseline that employs minimal regularization and leverages a beneficial pre-trained model, using a two-stage training pipeline. The researchers recommend including this baseline in future CL algorithm development, as it has demonstrated state-of-the-art performance.
Critical Analysis
The paper presents a comprehensive and thought-provoking investigation into the role of pre-training in continual learning (CL). The authors rightly point out the limitations of existing CL algorithms, which have been primarily evaluated in a from-scratch training setting. By systematically exploring the interaction between pre-trained models, CL algorithms, and CL scenarios, the paper offers valuable insights that challenge the current CL research paradigm.
One potential limitation of the paper is the scope of the experiments, which mainly focus on image classification tasks. While these tasks are commonly used in CL research, it would be interesting to see how the findings translate to other domains, such as natural language processing or reinforcement learning.
Additionally, the paper does not delve into the specific mechanisms by which pre-training can benefit CL. A deeper analysis of the transfer learning dynamics and the role of different pre-training objectives could provide further insights and guide the development of more effective CL algorithms.
Despite these minor limitations, the paper's key contributions are significant. The finding that a previously underperforming CL algorithm can become competitive or even state-of-the-art when starting from a pre-trained model is particularly intriguing and highlights the need to reconsider the current CL evaluation paradigm.
The introduction of the simple yet effective CL baseline is also noteworthy, as it demonstrates the potential for leveraging pre-training to improve CL performance. This baseline can serve as a valuable reference point for future CL research and development.
Conclusion
This paper advocates for the systematic incorporation of pre-training into continual learning (CL) research, arguing that it can help transfer knowledge more effectively to downstream tasks. The authors' investigation reveals the complex interplay between pre-trained models, CL algorithms, and CL scenarios, leading to several important observations.
Perhaps the most striking finding is that improvements in CL algorithms from pre-training are highly inconsistent, with a previously underperforming algorithm becoming competitive or even state-of-the-art when starting from a pre-trained model. This suggests that the current practice of comparing CL methods in a from-scratch setting may not accurately reflect their true potential.
Based on these insights, the paper introduces a simple yet effective CL baseline that employs minimal regularization and leverages a beneficial pre-trained model. The researchers recommend including this baseline in future CL algorithm development, as it has demonstrated state-of-the-art performance.
Overall, this paper makes a compelling case for the systematic integration of pre-training into CL research, opening up new avenues for developing more robust and effective CL systems that can better adapt to real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✅
0
Do Pre-trained Models Benefit Equally in Continual Learning?
Kuan-Ying Lee, Yuanyi Zhong, Yu-Xiong Wang
Existing work on continual learning (CL) is primarily devoted to developing algorithms for models trained from scratch. Despite their encouraging performance on contrived benchmarks, these algorithms show dramatic performance drops in real-world scenarios. Therefore, this paper advocates the systematic introduction of pre-training to CL, which is a general recipe for transferring knowledge to downstream tasks but is substantially missing in the CL community. Our investigation reveals the multifaceted complexity of exploiting pre-trained models for CL, along three different axes, pre-trained models, CL algorithms, and CL scenarios. Perhaps most intriguingly, improvements in CL algorithms from pre-training are very inconsistent an underperforming algorithm could become competitive and even state-of-the-art when all algorithms start from a pre-trained model. This indicates that the current paradigm, where all CL methods are compared in from-scratch training, is not well reflective of the true CL objective and desired progress. In addition, we make several other important observations, including that CL algorithms that exert less regularization benefit more from a pre-trained model; and that a stronger pre-trained model such as CLIP does not guarantee a better improvement. Based on these findings, we introduce a simple yet effective baseline that employs minimum regularization and leverages the more beneficial pre-trained model, coupled with a two-stage training pipeline. We recommend including this strong baseline in the future development of CL algorithms, due to its demonstrated state-of-the-art performance.
Read more7/8/2024
🧠
0
Continual Learning with Pre-Trained Models: A Survey
Da-Wei Zhou, Hai-Long Sun, Jingyi Ning, Han-Jia Ye, De-Chuan Zhan
Nowadays, real-world applications often face streaming data, which requires the learning system to absorb new knowledge as data evolves. Continual Learning (CL) aims to achieve this goal and meanwhile overcome the catastrophic forgetting of former knowledge when learning new ones. Typical CL methods build the model from scratch to grow with incoming data. However, the advent of the pre-trained model (PTM) era has sparked immense research interest, particularly in leveraging PTMs' robust representational capabilities. This paper presents a comprehensive survey of the latest advancements in PTM-based CL. We categorize existing methodologies into three distinct groups, providing a comparative analysis of their similarities, differences, and respective advantages and disadvantages. Additionally, we offer an empirical study contrasting various state-of-the-art methods to highlight concerns regarding fairness in comparisons. The source code to reproduce these evaluations is available at: https://github.com/sun-hailong/LAMDA-PILOT
Read more4/24/2024
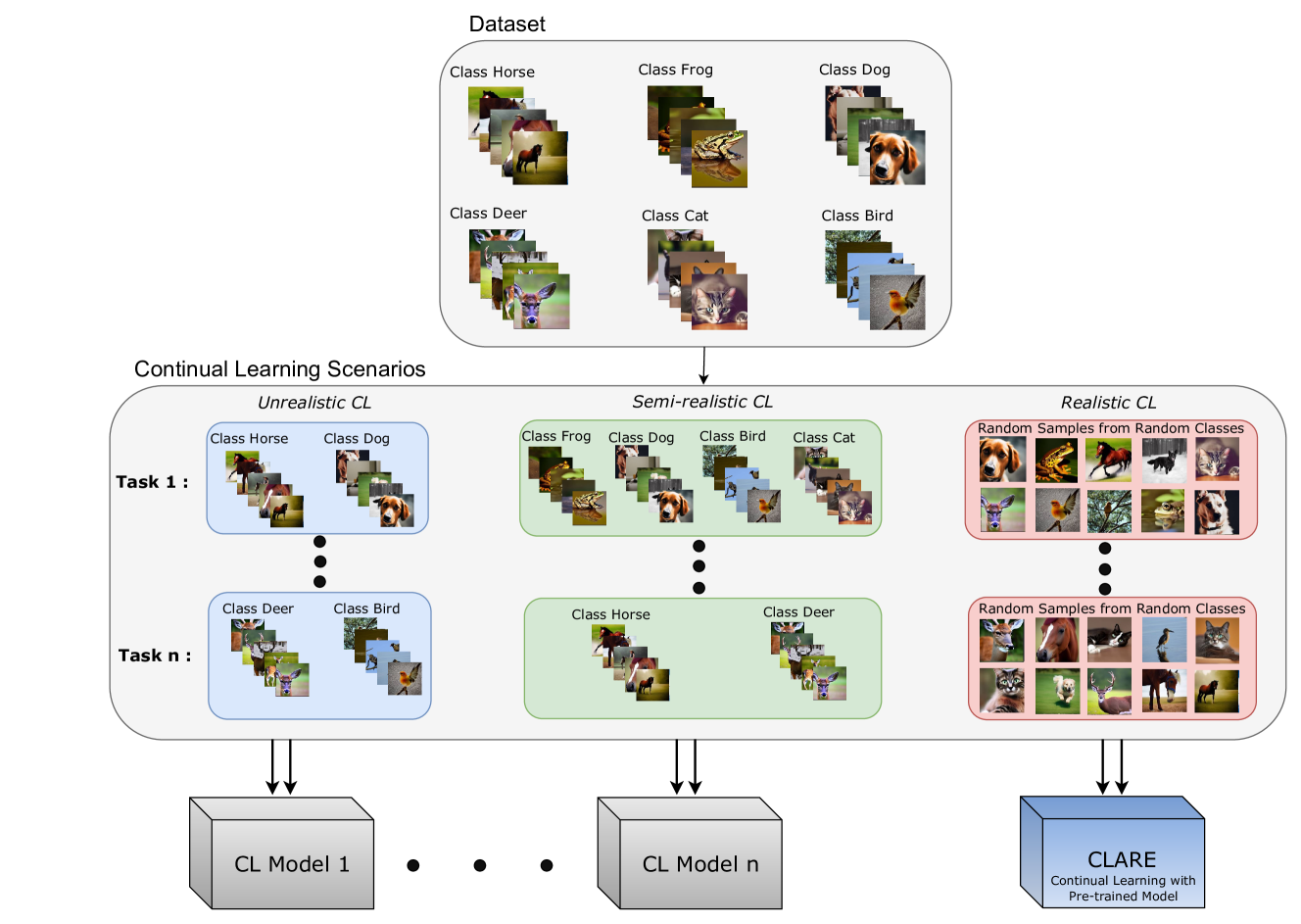
0
Realistic Continual Learning Approach using Pre-trained Models
Nadia Nasri, Carlos Guti'errez-'Alvarez, Sergio Lafuente-Arroyo, Saturnino Maldonado-Basc'on, Roberto J. L'opez-Sastre
Continual learning (CL) is crucial for evaluating adaptability in learning solutions to retain knowledge. Our research addresses the challenge of catastrophic forgetting, where models lose proficiency in previously learned tasks as they acquire new ones. While numerous solutions have been proposed, existing experimental setups often rely on idealized class-incremental learning scenarios. We introduce Realistic Continual Learning (RealCL), a novel CL paradigm where class distributions across tasks are random, departing from structured setups. We also present CLARE (Continual Learning Approach with pRE-trained models for RealCL scenarios), a pre-trained model-based solution designed to integrate new knowledge while preserving past learning. Our contributions include pioneering RealCL as a generalization of traditional CL setups, proposing CLARE as an adaptable approach for RealCL tasks, and conducting extensive experiments demonstrating its effectiveness across various RealCL scenarios. Notably, CLARE outperforms existing models on RealCL benchmarks, highlighting its versatility and robustness in unpredictable learning environments.
Read more4/12/2024

0
Recent Advances of Foundation Language Models-based Continual Learning: A Survey
Yutao Yang, Jie Zhou, Xuanwen Ding, Tianyu Huai, Shunyu Liu, Qin Chen, Liang He, Yuan Xie
Recently, foundation language models (LMs) have marked significant achievements in the domains of natural language processing (NLP) and computer vision (CV). Unlike traditional neural network models, foundation LMs obtain a great ability for transfer learning by acquiring rich commonsense knowledge through pre-training on extensive unsupervised datasets with a vast number of parameters. However, they still can not emulate human-like continuous learning due to catastrophic forgetting. Consequently, various continual learning (CL)-based methodologies have been developed to refine LMs, enabling them to adapt to new tasks without forgetting previous knowledge. However, a systematic taxonomy of existing approaches and a comparison of their performance are still lacking, which is the gap that our survey aims to fill. We delve into a comprehensive review, summarization, and classification of the existing literature on CL-based approaches applied to foundation language models, such as pre-trained language models (PLMs), large language models (LLMs) and vision-language models (VLMs). We divide these studies into offline CL and online CL, which consist of traditional methods, parameter-efficient-based methods, instruction tuning-based methods and continual pre-training methods. Offline CL encompasses domain-incremental learning, task-incremental learning, and class-incremental learning, while online CL is subdivided into hard task boundary and blurry task boundary settings. Additionally, we outline the typical datasets and metrics employed in CL research and provide a detailed analysis of the challenges and future work for LMs-based continual learning.
Read more5/30/2024