Decomposing Label Space, Format and Discrimination: Rethinking How LLMs Respond and Solve Tasks via In-Context Learning

0
🤖
Sign in to get full access
Overview
- In-context Learning (ICL) allows large language models (LLMs) to perform a wide range of tasks without updating millions of parameters, by using few-shot demonstrative examples.
- This paper aims to empirically decompose the overall performance of ICL into three dimensions: label space, format, and discrimination.
- The paper evaluates four general-purpose LLMs across a diverse range of tasks and finds that demonstrations have a marginal impact on provoking discriminative knowledge in language models.
- However, ICL is shown to be effective in regulating the label space and format, helping LLMs respond with desired label words, similar to detailed instructions.
- The paper also analyzes the mechanism of retrieval in ICL, finding that retrieving the most semantically similar examples boosts the model's discriminative capability.
Plain English Explanation
In-context Learning (ICL) is a powerful capability that allows large language models (LLMs) to perform a wide range of tasks without having to update millions of parameters. This is done by providing the LLM with a few examples that demonstrate how to complete a specific task. [https://aimodels.fyi/papers/arxiv/take-one-step-at-time-to-know]
However, the precise ways in which these demonstrations improve the LLM's performance on the end task have not been thoroughly investigated. This paper aims to break down the overall performance of ICL into three key aspects: the label space (the set of possible output labels), the format of the outputs, and the model's ability to discriminate between different options (its "discriminative knowledge").
The researchers evaluated four different LLMs on a variety of tasks and found some surprising results. Contrary to what one might expect, the demonstrations had only a marginal impact on the models' discriminative knowledge. [https://aimodels.fyi/papers/arxiv/context-learning-generalizes-but-not-always-robustly]
However, ICL was very effective at helping the LLMs regulate the label space and output format, allowing them to respond with the desired words or format. This suggests that ICL functions a bit like detailed instructions for the LLM to follow, rather than primarily improving its underlying understanding.
The paper also examines the role of retrieval in ICL, finding that retrieving the most semantically similar examples can significantly boost the model's discriminative capability. [https://aimodels.fyi/papers/arxiv/rectifying-demonstration-shortcut-context-learning]
Technical Explanation
This paper empirically decomposes the overall performance of In-context Learning (ICL) into three key dimensions: label space, format, and discrimination.
The researchers evaluate four general-purpose large language models (LLMs) on a diverse set of tasks, using few-shot demonstrations to enable the models to perform these tasks. They find that, counter-intuitively, the demonstrations have only a marginal impact on provoking discriminative knowledge in the language models. [https://aimodels.fyi/papers/arxiv/supervised-knowledge-makes-large-language-models-better]
However, the paper demonstrates that ICL is highly effective at regulating the label space and format of the model's outputs, helping the LLMs respond with the desired label words. This suggests that ICL functions more like detailed instructions for the model to follow, rather than primarily improving its underlying understanding.
The authors also provide an in-depth analysis of the retrieval mechanism underlying ICL. They find that retrieving the most semantically similar demonstration examples can notably boost the model's discriminative capability. [https://aimodels.fyi/papers/arxiv/how-does-multi-task-training-affect-transformer]
Critical Analysis
The paper provides valuable insights into the specific mechanisms by which In-context Learning (ICL) can improve the performance of large language models (LLMs) on a wide range of tasks. The finding that demonstrations have a marginal impact on the models' discriminative knowledge is particularly counterintuitive and worth further investigation.
One potential limitation of the study is the specific set of tasks and LLMs evaluated. It would be interesting to see if the same patterns hold across an even broader range of tasks and model architectures. Additionally, the paper does not delve into the potential reasons why demonstrations have a limited impact on discriminative knowledge, which could be an area for future research.
The analysis of the retrieval mechanism is a strength of the paper, as it provides a potential avenue for further improving the effectiveness of ICL. However, the authors do not explore how the retrieved examples could be optimized or selected to maximize the boost in discriminative capability.
Overall, this paper makes an important contribution to our understanding of how ICL works and the specific ways in which it can enhance LLM performance. The findings challenge some common assumptions and point to areas for further exploration that could lead to even more powerful and effective language models.
Conclusion
This paper provides a detailed empirical investigation into the mechanisms underlying In-context Learning (ICL) and its impact on the performance of large language models (LLMs). The key findings are:
- Demonstrations have a marginal impact on provoking discriminative knowledge in LLMs, counter to expectations.
- However, ICL is highly effective at regulating the label space and output format, helping LLMs respond with desired label words.
- Retrieving the most semantically similar demonstration examples can notably boost the model's discriminative capability.
These insights challenge some common assumptions about ICL and point to new directions for further research and development of even more powerful language models. By understanding the specific ways in which ICL works, researchers and practitioners can work to optimize and enhance this important capability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
Decomposing Label Space, Format and Discrimination: Rethinking How LLMs Respond and Solve Tasks via In-Context Learning
Quanyu Long, Yin Wu, Wenya Wang, Sinno Jialin Pan
In-context Learning (ICL) has emerged as a powerful capability alongside the development of scaled-up large language models (LLMs). By instructing LLMs using few-shot demonstrative examples, ICL enables them to perform a wide range of tasks without updating millions of parameters. However, the precise contributions of demonstrations towards improving end-task performance have not been thoroughly investigated in recent analytical studies. In this paper, we empirically decompose the overall performance of ICL into three dimensions, label space, format, and discrimination, and we evaluate four general-purpose LLMs across a diverse range of tasks. Counter-intuitively, we find that the demonstrations have a marginal impact on provoking discriminative knowledge of language models. However, ICL exhibits significant efficacy in regulating the label space and format, which helps LLMs respond to desired label words. We then demonstrate that this ability functions similar to detailed instructions for LLMs to follow. We additionally provide an in-depth analysis of the mechanism of retrieval helping with ICL. Our findings demonstrate that retrieving the semantically similar examples notably boosts the model's discriminative capability. However, we also observe a trade-off in selecting good in-context examples regarding label diversity.
Read more7/24/2024

0
Large Language Models Know What Makes Exemplary Contexts
Quanyu Long, Jianda Chen, Wenya Wang, Sinno Jialin Pan
In-context learning (ICL) has proven to be a significant capability with the advancement of Large Language models (LLMs). By instructing LLMs using few-shot demonstrative examples, ICL enables them to perform a wide range of tasks without needing to update millions of parameters. This paper presents a unified framework for LLMs that allows them to self-select influential in-context examples to compose their contexts; self-rank candidates with different demonstration compositions; self-optimize the demonstration selection and ordering through reinforcement learning. Specifically, our method designs a parameter-efficient retrieval head that generates the optimized demonstration after training with rewards from LLM's own preference. Experimental results validate the proposed method's effectiveness in enhancing ICL performance. Additionally, our approach effectively identifies and selects the most representative examples for the current task, and includes more diversity in retrieval.
Read more8/21/2024

0
Unveiling In-Context Learning: A Coordinate System to Understand Its Working Mechanism
Anhao Zhao, Fanghua Ye, Jinlan Fu, Xiaoyu Shen
Large language models (LLMs) exhibit remarkable in-context learning (ICL) capabilities. However, the underlying working mechanism of ICL remains poorly understood. Recent research presents two conflicting views on ICL: One attributes it to LLMs' inherent ability of task recognition, deeming label correctness and shot numbers of demonstrations as not crucial; the other emphasizes the impact of similar examples in the demonstrations, stressing the need for label correctness and more shots. In this work, we provide a Two-Dimensional Coordinate System that unifies both views into a systematic framework. The framework explains the behavior of ICL through two orthogonal variables: whether LLMs can recognize the task and whether similar examples are presented in the demonstrations. We propose the peak inverse rank metric to detect the task recognition ability of LLMs and study LLMs' reactions to different definitions of similarity. Based on these, we conduct extensive experiments to elucidate how ICL functions across each quadrant on multiple representative classification tasks. Finally, we extend our analyses to generation tasks, showing that our coordinate system can also be used to interpret ICL for generation tasks effectively.
Read more7/25/2024
0
Unifying Demonstration Selection and Compression for In-Context Learning
Jun Gao, Ziqiang Cao, Wenjie Li
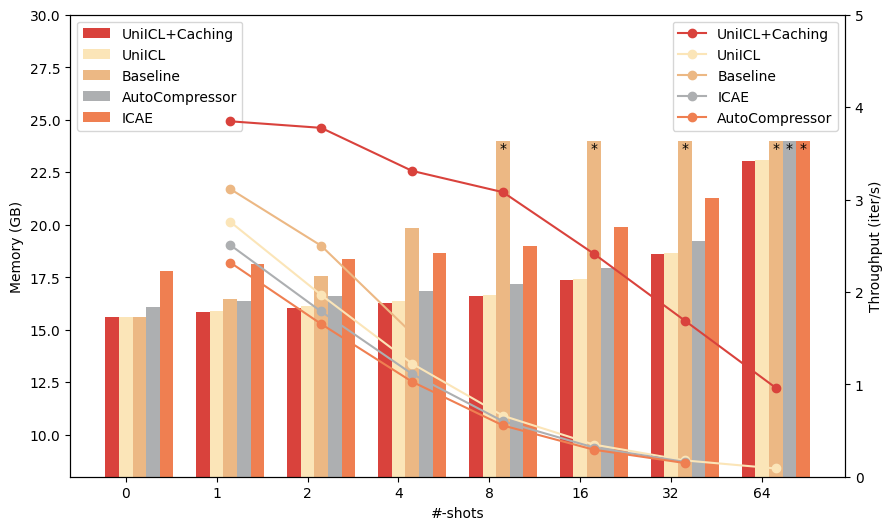
In-context learning (ICL) facilitates large language models (LLMs) exhibiting spectacular emergent capabilities in various scenarios. Unfortunately, introducing demonstrations easily makes the prompt length explode, bringing a significant burden to hardware. In addition, random demonstrations usually achieve limited improvements in ICL, necessitating demonstration selection among accessible candidates. Previous studies introduce extra modules to perform demonstration compression or selection independently. In this paper, we propose an ICL framework UniICL, which Unifies demonstration selection and compression, and final response generation via a single frozen LLM. Specifically, UniICL first projects actual demonstrations and inference text inputs into short virtual tokens, respectively. Then, virtual tokens are applied to select suitable demonstrations by measuring semantic similarity within latent space among candidate demonstrations and inference input. Finally, inference text inputs together with selected virtual demonstrations are fed into the same frozen LLM for response generation. Notably, UniICL is a parameter-efficient framework that only contains 17M trainable parameters originating from the projection layer. We conduct experiments and analysis over in- and out-domain datasets of both generative and understanding tasks, encompassing ICL scenarios with plentiful and limited demonstration candidates. Results show that UniICL effectively unifies $12 times$ compression, demonstration selection, and response generation, efficiently scaling up the baseline from 4-shot to 64-shot ICL in IMDb with 24 GB CUDA allocation
Read more6/18/2024