$L_p$-norm Distortion-Efficient Adversarial Attack

0

Sign in to get full access
Overview
- This paper proposes a new adversarial attack method called "𝐿_𝑝-norm Distortion-Efficient Adversarial Attack" that can generate adversarial examples with minimal distortion compared to existing techniques.
- The key idea is to formulate the attack as an optimization problem that minimizes the 𝐿_𝑝 norm of the adversarial perturbation while maximizing the model's classification loss.
- The authors demonstrate the effectiveness of their method on various image classification datasets and show that it outperforms state-of-the-art attacks in terms of distortion efficiency.
Plain English Explanation
Machine learning models, such as image classifiers, can be easily fooled by small, imperceptible changes to the input, known as adversarial examples. These adversarial examples cause the model to make incorrect predictions, which is a major security concern.
The paper proposes a new method to generate these adversarial examples in a more efficient way. Instead of making large, noticeable changes to the input, the method tries to find the smallest possible change that will still cause the model to misclassify the image.
The basic idea is to frame the problem as an optimization task. The method tries to minimize the size of the change (measured by the 𝐿_𝑝 norm) while also maximizing the model's classification error. This allows it to generate adversarial examples that are more "distortion-efficient" than previous techniques.
The authors test their method on several image classification datasets and show that it outperforms existing adversarial attack algorithms in terms of the tradeoff between the size of the perturbation and the model's classification accuracy. This suggests that their approach is a more effective way to probe the vulnerabilities of machine learning models.
Technical Explanation
The key technical contribution of this paper is the formulation of the adversarial attack as an optimization problem that minimizes the 𝐿_𝑝 norm of the adversarial perturbation while maximizing the model's classification loss.
Specifically, the authors define the attack as:
min ||δ||_p
s.t. argmax(f(x + δ)) ≠ argmax(f(x))
Where x is the original input, δ is the adversarial perturbation, f(·) is the target model, and ||·||_p denotes the 𝐿_𝑝 norm.
By optimizing this objective, the method can generate adversarial examples that are "distortion-efficient" in the sense that they achieve a high classification error with a small perturbation size.
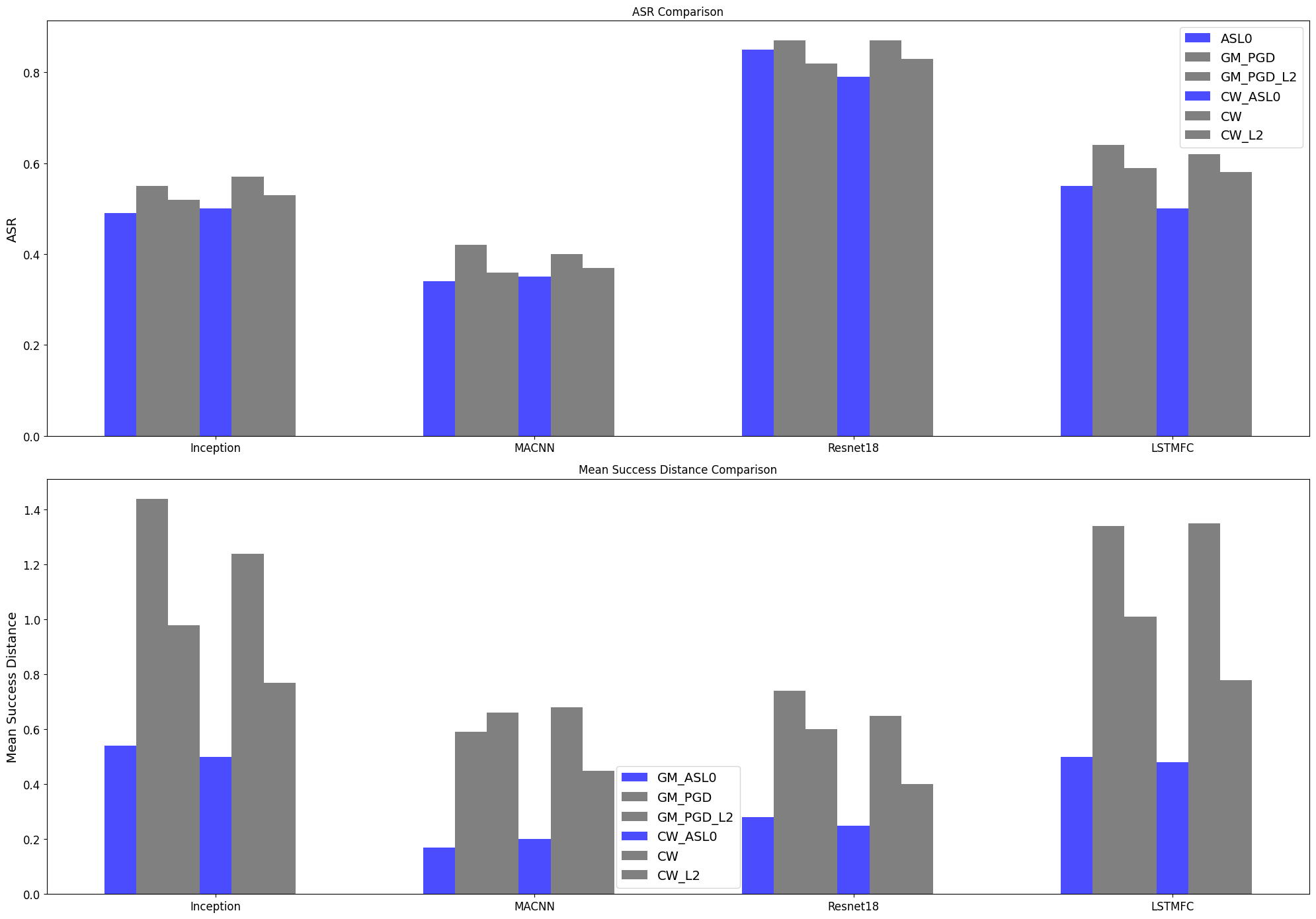
The authors propose two algorithms to solve this optimization problem: a projected gradient descent (PGD) method and a Frank-Wolfe-based method. They show that both approaches outperform existing adversarial attack techniques, such as PGD, AALN, and ConPatch, in terms of the trade-off between perturbation size and model classification error.
Critical Analysis
The proposed 𝐿_𝑝-norm Distortion-Efficient Adversarial Attack is a novel and promising approach to generating adversarial examples. The key strength of the method is its ability to find the smallest possible perturbation that can still fool the target model, which is an important property for understanding model robustness and security vulnerabilities.
However, the paper does not provide a thorough analysis of the limitations and potential issues with the proposed technique. For example, the authors only evaluate the method on image classification tasks, and it's unclear how well it would generalize to other domains, such as natural language processing or time series data.
Additionally, the paper does not discuss the computational complexity of the optimization-based attack, which could be an important practical consideration, especially for real-time applications.
It would also be valuable to see a more in-depth discussion of the potential implications and societal impact of this research. While the authors mention the security concerns around adversarial examples, they do not explore the broader ethical considerations or potential misuse of such techniques.
Conclusion
The 𝐿_𝑝-norm Distortion-Efficient Adversarial Attack proposed in this paper represents an important advancement in the field of adversarial machine learning. By framing the attack as an optimization problem that minimizes the perturbation size, the method can generate highly efficient adversarial examples that highlight the vulnerabilities of state-of-the-art image classifiers.
The authors have demonstrated the effectiveness of their approach on several benchmark datasets, and their work underscores the need for continued research into developing more robust and secure machine learning models. While the paper does not address all the potential limitations and implications of this research, it provides a strong foundation for future work in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
$L_p$-norm Distortion-Efficient Adversarial Attack
Chao Zhou, Yuan-Gen Wang, Zi-jia Wang, Xiangui Kang
Adversarial examples have shown a powerful ability to make a well-trained model misclassified. Current mainstream adversarial attack methods only consider one of the distortions among $L_0$-norm, $L_2$-norm, and $L_infty$-norm. $L_0$-norm based methods cause large modification on a single pixel, resulting in naked-eye visible detection, while $L_2$-norm and $L_infty$-norm based methods suffer from weak robustness against adversarial defense since they always diffuse tiny perturbations to all pixels. A more realistic adversarial perturbation should be sparse and imperceptible. In this paper, we propose a novel $L_p$-norm distortion-efficient adversarial attack, which not only owns the least $L_2$-norm loss but also significantly reduces the $L_0$-norm distortion. To this aim, we design a new optimization scheme, which first optimizes an initial adversarial perturbation under $L_2$-norm constraint, and then constructs a dimension unimportance matrix for the initial perturbation. Such a dimension unimportance matrix can indicate the adversarial unimportance of each dimension of the initial perturbation. Furthermore, we introduce a new concept of adversarial threshold for the dimension unimportance matrix. The dimensions of the initial perturbation whose unimportance is higher than the threshold will be all set to zero, greatly decreasing the $L_0$-norm distortion. Experimental results on three benchmark datasets show that under the same query budget, the adversarial examples generated by our method have lower $L_0$-norm and $L_2$-norm distortion than the state-of-the-art. Especially for the MNIST dataset, our attack reduces 8.1$%$ $L_2$-norm distortion meanwhile remaining 47$%$ pixels unattacked. This demonstrates the superiority of the proposed method over its competitors in terms of adversarial robustness and visual imperceptibility.
Read more7/4/2024
0
Evaluating Model Robustness Using Adaptive Sparse L0 Regularization
Weiyou Liu, Zhenyang Li, Weitong Chen
Deep Neural Networks have demonstrated remarkable success in various domains but remain susceptible to adversarial examples, which are slightly altered inputs designed to induce misclassification. While adversarial attacks typically optimize under Lp norm constraints, attacks based on the L0 norm, prioritising input sparsity, are less studied due to their complex and non convex nature. These sparse adversarial examples challenge existing defenses by altering a minimal subset of features, potentially uncovering more subtle DNN weaknesses. However, the current L0 norm attack methodologies face a trade off between accuracy and efficiency either precise but computationally intense or expedient but imprecise. This paper proposes a novel, scalable, and effective approach to generate adversarial examples based on the L0 norm, aimed at refining the robustness evaluation of DNNs against such perturbations.
Read more8/29/2024

0
Towards Efficient Training and Evaluation of Robust Models against $l_0$ Bounded Adversarial Perturbations
Xuyang Zhong, Yixiao Huang, Chen Liu
This work studies sparse adversarial perturbations bounded by $l_0$ norm. We propose a white-box PGD-like attack method named sparse-PGD to effectively and efficiently generate such perturbations. Furthermore, we combine sparse-PGD with a black-box attack to comprehensively and more reliably evaluate the models' robustness against $l_0$ bounded adversarial perturbations. Moreover, the efficiency of sparse-PGD enables us to conduct adversarial training to build robust models against sparse perturbations. Extensive experiments demonstrate that our proposed attack algorithm exhibits strong performance in different scenarios. More importantly, compared with other robust models, our adversarially trained model demonstrates state-of-the-art robustness against various sparse attacks. Codes are available at https://github.com/CityU-MLO/sPGD.
Read more5/9/2024
🖼️
0
Investigating the Corruption Robustness of Image Classifiers with Random Lp-norm Corruptions
Georg Siedel, Weijia Shao, Silvia Vock, Andrey Morozov
Robustness is a fundamental property of machine learning classifiers required to achieve safety and reliability. In the field of adversarial robustness of image classifiers, robustness is commonly defined as the stability of a model to all input changes within a p-norm distance. However, in the field of random corruption robustness, variations observed in the real world are used, while p-norm corruptions are rarely considered. This study investigates the use of random p-norm corruptions to augment the training and test data of image classifiers. We evaluate the model robustness against imperceptible random p-norm corruptions and propose a novel robustness metric. We empirically investigate whether robustness transfers across different p-norms and derive conclusions on which p-norm corruptions a model should be trained and evaluated. We find that training data augmentation with a combination of p-norm corruptions significantly improves corruption robustness, even on top of state-of-the-art data augmentation schemes.
Read more5/28/2024