Evaluating Model Robustness Using Adaptive Sparse L0 Regularization

0
Sign in to get full access
Overview
- Evaluates model robustness using adaptive sparse L0 regularization
- Proposes a new regularization method to improve model robustness against adversarial attacks
- Demonstrates improved performance on standard benchmarks compared to existing methods
Plain English Explanation
This research paper introduces a new technique called "adaptive sparse L0 regularization" to improve the robustness of machine learning models against adversarial attacks. Adversarial attacks are small, carefully crafted changes to the input data that can cause a model to make incorrect predictions.
The key idea behind the new regularization method is to encourage the model to rely on a sparse set of important features, rather than being overly sensitive to small changes in the input. By adaptively adjusting the regularization strength during training, the model learns to focus on the most relevant and robust features.
The researchers show that this approach outperforms existing methods for improving model robustness on standard benchmark datasets. This suggests that adaptive sparse regularization is an effective technique for training models that are more resistant to adversarial attacks, which is an important consideration for deploying machine learning systems in high-stakes applications.
Technical Explanation
The paper proposes a new regularization method called "Adaptive Sparse L0 Regularization" to improve the robustness of machine learning models. Traditional L1 and L2 regularization encourage sparse and smooth model weights, respectively, but do not directly target robustness to adversarial attacks.
The key innovation is to use an adaptive L0 regularization term, which penalizes the number of non-zero weights in the model. By adaptively adjusting the regularization strength during training, the model is encouraged to rely on a sparse set of the most important features, rather than being overly sensitive to small perturbations in the input.
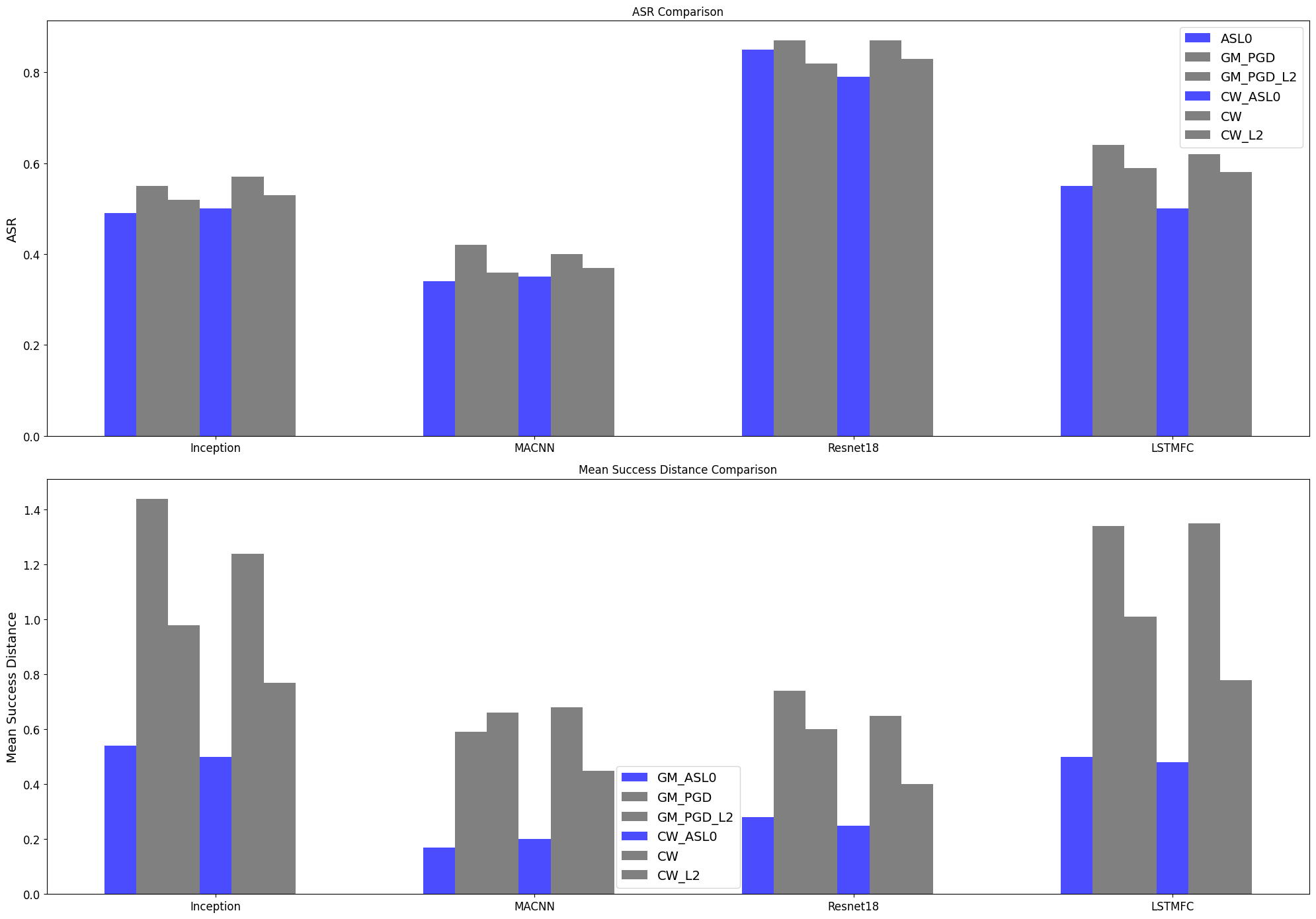
The researchers evaluate their approach on standard benchmark datasets for image classification and text classification, and demonstrate improved performance compared to existing methods for improving model robustness, such as adversarial training and certified defenses.
Critical Analysis
The paper provides a thorough evaluation of the proposed adaptive sparse L0 regularization method, including comparisons to state-of-the-art baselines on multiple datasets. The results suggest this is a promising approach for improving model robustness.
However, the paper does not address some potential limitations or caveats. For example, the computational overhead of the adaptive regularization process is not discussed, which could be an important practical consideration. Additionally, the paper focuses on relatively simple benchmark tasks, and it's unclear how well the method would scale to more complex, real-world machine learning problems.
Further research would be needed to better understand the strengths and weaknesses of this approach, as well as explore potential extensions or combinations with other robustness-enhancing techniques. Ultimately, improving the reliability and security of machine learning systems remains an active and important area of study.
Conclusion
This research paper introduces a novel approach called "Adaptive Sparse L0 Regularization" to improve the robustness of machine learning models against adversarial attacks. By adaptively encouraging the model to rely on a sparse set of important features, this method demonstrates improved performance on standard benchmarks compared to existing techniques.
While the results are promising, further research is needed to fully understand the capabilities and limitations of this approach. Nonetheless, this work represents a valuable contribution to the ongoing efforts to develop more reliable and secure machine learning systems, which is crucial as these technologies become increasingly widespread in high-stakes applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evaluating Model Robustness Using Adaptive Sparse L0 Regularization
Weiyou Liu, Zhenyang Li, Weitong Chen
Deep Neural Networks have demonstrated remarkable success in various domains but remain susceptible to adversarial examples, which are slightly altered inputs designed to induce misclassification. While adversarial attacks typically optimize under Lp norm constraints, attacks based on the L0 norm, prioritising input sparsity, are less studied due to their complex and non convex nature. These sparse adversarial examples challenge existing defenses by altering a minimal subset of features, potentially uncovering more subtle DNN weaknesses. However, the current L0 norm attack methodologies face a trade off between accuracy and efficiency either precise but computationally intense or expedient but imprecise. This paper proposes a novel, scalable, and effective approach to generate adversarial examples based on the L0 norm, aimed at refining the robustness evaluation of DNNs against such perturbations.
Read more8/29/2024

0
Towards Efficient Training and Evaluation of Robust Models against $l_0$ Bounded Adversarial Perturbations
Xuyang Zhong, Yixiao Huang, Chen Liu
This work studies sparse adversarial perturbations bounded by $l_0$ norm. We propose a white-box PGD-like attack method named sparse-PGD to effectively and efficiently generate such perturbations. Furthermore, we combine sparse-PGD with a black-box attack to comprehensively and more reliably evaluate the models' robustness against $l_0$ bounded adversarial perturbations. Moreover, the efficiency of sparse-PGD enables us to conduct adversarial training to build robust models against sparse perturbations. Extensive experiments demonstrate that our proposed attack algorithm exhibits strong performance in different scenarios. More importantly, compared with other robust models, our adversarially trained model demonstrates state-of-the-art robustness against various sparse attacks. Codes are available at https://github.com/CityU-MLO/sPGD.
Read more5/9/2024
📊
0
Certified Robustness against Sparse Adversarial Perturbations via Data Localization
Ambar Pal, Ren'e Vidal, Jeremias Sulam
Recent work in adversarial robustness suggests that natural data distributions are localized, i.e., they place high probability in small volume regions of the input space, and that this property can be utilized for designing classifiers with improved robustness guarantees for $ell_2$-bounded perturbations. Yet, it is still unclear if this observation holds true for more general metrics. In this work, we extend this theory to $ell_0$-bounded adversarial perturbations, where the attacker can modify a few pixels of the image but is unrestricted in the magnitude of perturbation, and we show necessary and sufficient conditions for the existence of $ell_0$-robust classifiers. Theoretical certification approaches in this regime essentially employ voting over a large ensemble of classifiers. Such procedures are combinatorial and expensive or require complicated certification techniques. In contrast, a simple classifier emerges from our theory, dubbed Box-NN, which naturally incorporates the geometry of the problem and improves upon the current state-of-the-art in certified robustness against sparse attacks for the MNIST and Fashion-MNIST datasets.
Read more5/24/2024

0
$L_p$-norm Distortion-Efficient Adversarial Attack
Chao Zhou, Yuan-Gen Wang, Zi-jia Wang, Xiangui Kang
Adversarial examples have shown a powerful ability to make a well-trained model misclassified. Current mainstream adversarial attack methods only consider one of the distortions among $L_0$-norm, $L_2$-norm, and $L_infty$-norm. $L_0$-norm based methods cause large modification on a single pixel, resulting in naked-eye visible detection, while $L_2$-norm and $L_infty$-norm based methods suffer from weak robustness against adversarial defense since they always diffuse tiny perturbations to all pixels. A more realistic adversarial perturbation should be sparse and imperceptible. In this paper, we propose a novel $L_p$-norm distortion-efficient adversarial attack, which not only owns the least $L_2$-norm loss but also significantly reduces the $L_0$-norm distortion. To this aim, we design a new optimization scheme, which first optimizes an initial adversarial perturbation under $L_2$-norm constraint, and then constructs a dimension unimportance matrix for the initial perturbation. Such a dimension unimportance matrix can indicate the adversarial unimportance of each dimension of the initial perturbation. Furthermore, we introduce a new concept of adversarial threshold for the dimension unimportance matrix. The dimensions of the initial perturbation whose unimportance is higher than the threshold will be all set to zero, greatly decreasing the $L_0$-norm distortion. Experimental results on three benchmark datasets show that under the same query budget, the adversarial examples generated by our method have lower $L_0$-norm and $L_2$-norm distortion than the state-of-the-art. Especially for the MNIST dataset, our attack reduces 8.1$%$ $L_2$-norm distortion meanwhile remaining 47$%$ pixels unattacked. This demonstrates the superiority of the proposed method over its competitors in terms of adversarial robustness and visual imperceptibility.
Read more7/4/2024