${M^2D}$NeRF: Multi-Modal Decomposition NeRF with 3D Feature Fields
2405.05010
0
0
✨
Abstract
Neural fields (NeRF) have emerged as a promising approach for representing continuous 3D scenes. Nevertheless, the lack of semantic encoding in NeRFs poses a significant challenge for scene decomposition. To address this challenge, we present a single model, Multi-Modal Decomposition NeRF (${M^2D}$NeRF), that is capable of both text-based and visual patch-based edits. Specifically, we use multi-modal feature distillation to integrate teacher features from pretrained visual and language models into 3D semantic feature volumes, thereby facilitating consistent 3D editing. To enforce consistency between the visual and language features in our 3D feature volumes, we introduce a multi-modal similarity constraint. We also introduce a patch-based joint contrastive loss that helps to encourage object-regions to coalesce in the 3D feature space, resulting in more precise boundaries. Experiments on various real-world scenes show superior performance in 3D scene decomposition tasks compared to prior NeRF-based methods.
Create account to get full access
Overview
- NeRF (Neural Radiance Fields) is a promising approach for representing continuous 3D scenes.
- However, the lack of semantic encoding in NeRFs poses a challenge for scene decomposition.
- To address this, the researchers present a model called [M^2D]NeRF that enables both text-based and visual patch-based edits.
- The key innovations are multi-modal feature distillation, a multi-modal similarity constraint, and a patch-based joint contrastive loss.
- Experiments show superior performance in 3D scene decomposition tasks compared to prior NeRF-based methods.
Plain English Explanation
NeRF is a technology that can create 3D models of real-world scenes by analyzing a series of 2D images. This is a powerful tool, but the 3D models it generates lack semantic information about the objects and structures in the scene. This makes it difficult to edit or manipulate the 3D models in meaningful ways.
To address this, the researchers developed a new system called [M^2D]NeRF. This system integrates features from pre-trained visual and language models to add semantic understanding to the 3D models. This allows users to edit the 3D models using text-based commands (e.g., "remove the chair") or by selecting specific visual regions (e.g., "edit the table").
The key innovations in [M^2D]NeRF are:
- Multi-modal feature distillation: Integrating features from visual and language models into the 3D feature volumes to enable consistent 3D editing.
- Multi-modal similarity constraint: Enforcing consistency between the visual and language features in the 3D feature volumes.
- Patch-based joint contrastive loss: Encouraging object-regions to coalesce in the 3D feature space, resulting in more precise boundaries.
By incorporating these techniques, the researchers were able to create 3D models with much richer semantic information than traditional NeRF approaches. This allows for more sophisticated and intuitive 3D scene editing, as demonstrated in their experiments on real-world scenes.
Technical Explanation
The researchers present a novel model called [M^2D]NeRF that extends the capabilities of Neural Radiance Fields (NeRF) by enabling both text-based and visual patch-based 3D scene editing.
To address the lack of semantic encoding in NeRFs, the researchers use multi-modal feature distillation to integrate teacher features from pre-trained visual and language models into the 3D feature volumes. This allows the model to leverage the rich semantic information from these pre-trained models, facilitating more consistent 3D editing.
To further enforce consistency between the visual and language features in the 3D feature volumes, the researchers introduce a multi-modal similarity constraint. This helps to ensure that the textual and visual representations of the scene are well-aligned.
Additionally, the researchers propose a patch-based joint contrastive loss that encourages object-regions to coalesce in the 3D feature space, resulting in more precise object boundaries. This patch-based approach helps to improve the granularity of the 3D scene decomposition, as shown in MonoPatchNeRF.
The researchers evaluate their [M^2D]NeRF model on various real-world scenes and demonstrate superior performance in 3D scene decomposition tasks compared to prior NeRF-based methods, such as NeRF-DETS and DATENeRF.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their paper. While [M^2D]NeRF demonstrates strong performance in 3D scene decomposition, the model still faces challenges in handling complex occlusions and accurately representing fine-grained details.
Additionally, the reliance on pre-trained visual and language models may limit the model's ability to generalize to new domains or data distributions. The researchers suggest that exploring self-supervised or unsupervised methods for semantic feature extraction could be a promising direction for future work.
Another potential area for improvement is the computational efficiency of the [M^2D]NeRF model, as the integration of multi-modal features and the patch-based approach may increase the overall runtime and memory requirements. Developing more lightweight and efficient architectures could broaden the practical applications of this technology.
Overall, the [M^2D]NeRF model presents an exciting step forward in bridging the gap between 3D scene representation and semantic understanding. By enabling text-based and visual patch-based editing, this work opens up new possibilities for intuitive and powerful 3D scene manipulation. As the researchers continue to refine and expand upon this approach, we can expect to see even more advanced and versatile 3D modeling and editing capabilities in the future.
Conclusion
The [M^2D]NeRF model developed by the researchers represents a significant advancement in the field of 3D scene representation and editing. By integrating multi-modal features and introducing novel techniques like multi-modal similarity constraints and patch-based contrastive learning, the model is able to generate 3D scene representations with rich semantic information.
This breakthrough enables users to manipulate 3D scenes in more intuitive and powerful ways, using both text-based commands and visual selection of specific regions. As the researchers continue to refine and build upon this work, we can expect to see even more sophisticated 3D modeling and editing capabilities emerge, with far-reaching implications for a wide range of applications, from virtual reality and gaming to architectural design and urban planning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
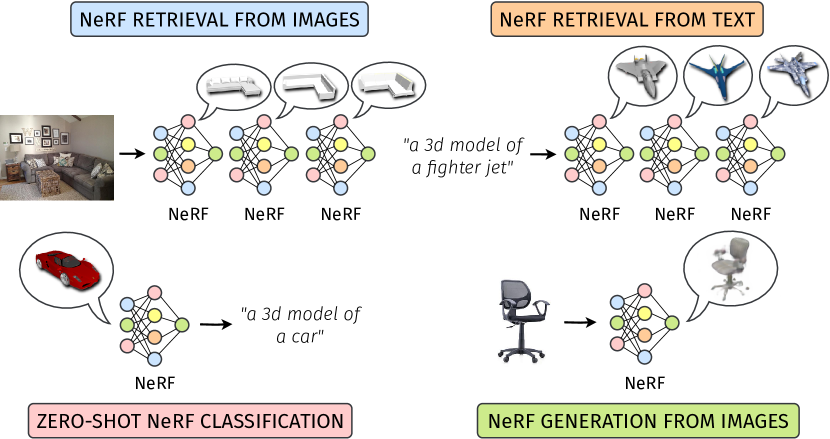
Connecting NeRFs, Images, and Text
Francesco Ballerini, Pierluigi Zama Ramirez, Roberto Mirabella, Samuele Salti, Luigi Di Stefano
0
0
Neural Radiance Fields (NeRFs) have emerged as a standard framework for representing 3D scenes and objects, introducing a novel data type for information exchange and storage. Concurrently, significant progress has been made in multimodal representation learning for text and image data. This paper explores a novel research direction that aims to connect the NeRF modality with other modalities, similar to established methodologies for images and text. To this end, we propose a simple framework that exploits pre-trained models for NeRF representations alongside multimodal models for text and image processing. Our framework learns a bidirectional mapping between NeRF embeddings and those obtained from corresponding images and text. This mapping unlocks several novel and useful applications, including NeRF zero-shot classification and NeRF retrieval from images or text.
4/12/2024

DATENeRF: Depth-Aware Text-based Editing of NeRFs
Sara Rojas, Julien Philip, Kai Zhang, Sai Bi, Fujun Luan, Bernard Ghanem, Kalyan Sunkavall
0
0
Recent advancements in diffusion models have shown remarkable proficiency in editing 2D images based on text prompts. However, extending these techniques to edit scenes in Neural Radiance Fields (NeRF) is complex, as editing individual 2D frames can result in inconsistencies across multiple views. Our crucial insight is that a NeRF scene's geometry can serve as a bridge to integrate these 2D edits. Utilizing this geometry, we employ a depth-conditioned ControlNet to enhance the coherence of each 2D image modification. Moreover, we introduce an inpainting approach that leverages the depth information of NeRF scenes to distribute 2D edits across different images, ensuring robustness against errors and resampling challenges. Our results reveal that this methodology achieves more consistent, lifelike, and detailed edits than existing leading methods for text-driven NeRF scene editing.
4/9/2024

DistillNeRF: Perceiving 3D Scenes from Single-Glance Images by Distilling Neural Fields and Foundation Model Features
Letian Wang, Seung Wook Kim, Jiawei Yang, Cunjun Yu, Boris Ivanovic, Steven L. Waslander, Yue Wang, Sanja Fidler, Marco Pavone, Peter Karkus
0
0
We propose DistillNeRF, a self-supervised learning framework addressing the challenge of understanding 3D environments from limited 2D observations in autonomous driving. Our method is a generalizable feedforward model that predicts a rich neural scene representation from sparse, single-frame multi-view camera inputs, and is trained self-supervised with differentiable rendering to reconstruct RGB, depth, or feature images. Our first insight is to exploit per-scene optimized Neural Radiance Fields (NeRFs) by generating dense depth and virtual camera targets for training, thereby helping our model to learn 3D geometry from sparse non-overlapping image inputs. Second, to learn a semantically rich 3D representation, we propose distilling features from pre-trained 2D foundation models, such as CLIP or DINOv2, thereby enabling various downstream tasks without the need for costly 3D human annotations. To leverage these two insights, we introduce a novel model architecture with a two-stage lift-splat-shoot encoder and a parameterized sparse hierarchical voxel representation. Experimental results on the NuScenes dataset demonstrate that DistillNeRF significantly outperforms existing comparable self-supervised methods for scene reconstruction, novel view synthesis, and depth estimation; and it allows for competitive zero-shot 3D semantic occupancy prediction, as well as open-world scene understanding through distilled foundation model features. Demos and code will be available at https://distillnerf.github.io/.
6/19/2024
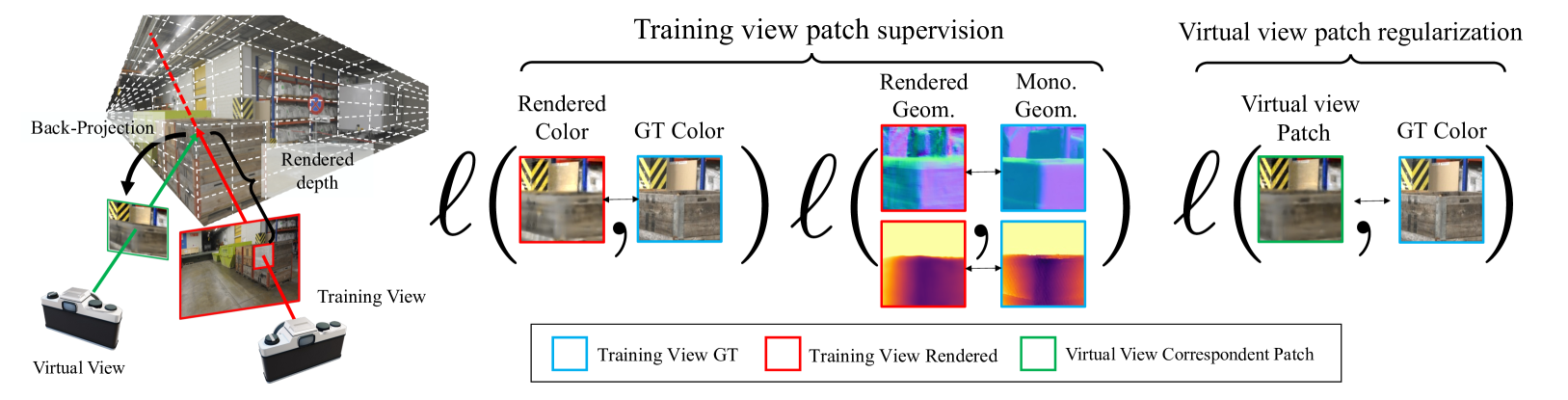
MonoPatchNeRF: Improving Neural Radiance Fields with Patch-based Monocular Guidance
Yuqun Wu, Jae Yong Lee, Chuhang Zou, Shenlong Wang, Derek Hoiem
0
0
The latest regularized Neural Radiance Field (NeRF) approaches produce poor geometry and view extrapolation for multiview stereo (MVS) benchmarks such as ETH3D. In this paper, we aim to create 3D models that provide accurate geometry and view synthesis, partially closing the large geometric performance gap between NeRF and traditional MVS methods. We propose a patch-based approach that effectively leverages monocular surface normal and relative depth predictions. The patch-based ray sampling also enables the appearance regularization of normalized cross-correlation (NCC) and structural similarity (SSIM) between randomly sampled virtual and training views. We further show that density restrictions based on sparse structure-from-motion points can help greatly improve geometric accuracy with a slight drop in novel view synthesis metrics. Our experiments show 4x the performance of RegNeRF and 8x that of FreeNeRF on average F1@2cm for ETH3D MVS benchmark, suggesting a fruitful research direction to improve the geometric accuracy of NeRF-based models, and sheds light on a potential future approach to enable NeRF-based optimization to eventually outperform traditional MVS.
4/15/2024