Connecting NeRFs, Images, and Text

0
Sign in to get full access
Overview
- This paper explores the connections between neural radiance fields (NeRFs), images, and text, with the goal of enabling depth-aware text-based editing of NeRFs.
- It builds on recent advancements in vision-language models and neural feature compression to create a system that can efficiently represent and manipulate NeRFs using textual information.
- The research aims to unlock new possibilities for creative expression and content creation by allowing users to directly interact with and modify 3D scenes through natural language.
Plain English Explanation
The paper focuses on a technology called neural radiance fields (NeRFs), which are a way of representing 3D scenes using machine learning. NeRFs can create highly detailed and realistic 3D models from a collection of 2D images.
The researchers wanted to find a way to let people edit and change these 3D models using simple text commands, rather than having to manually adjust the 3D models themselves. This could be very useful for things like video game development, movie production, or even just hobbyist 3D modeling.
To do this, the researchers built on top of recent advancements in vision-language models - AI systems that can understand and generate text while also processing visual information. They also used neural feature compression techniques to make the NeRF models more efficient and easier to work with.
The end result is a system that allows users to directly interact with and modify 3D scenes using natural language. For example, you could tell the system "Make the chair in the corner bigger" or "Add a window on the left side of the room" and it would update the 3D model accordingly. This could open up new possibilities for creative expression and content creation, allowing people to more easily bring their ideas to life in 3D.
Technical Explanation
The paper presents a framework that connects neural radiance fields (NeRFs) to images and text, enabling depth-aware text-based editing of NeRFs. This is achieved by building on recent advancements in vision-language models and neural feature compression.
The key components of the framework include:
- A text-to-NeRF module that learns to generate NeRF parameters from textual descriptions, allowing users to create and modify 3D scenes through natural language.
- A NeRF-to-image module that can render photorealistic 2D images from the 3D NeRF representations.
- A vision-language model that jointly encodes visual and textual information, enabling depth-aware understanding and manipulation of the 3D scenes.
The researchers train this framework in an end-to-end fashion, leveraging large-scale datasets of images and associated captions. This allows the system to learn the complex mappings between text, 3D geometry, and 2D renderings, unlocking new possibilities for creative expression and content creation.
Critical Analysis
The paper presents an interesting and promising approach for bridging the gap between 3D modeling, image manipulation, and natural language processing. By combining state-of-the-art techniques in NeRF generation, neural feature compression, and vision-language models, the researchers have developed a powerful system that could significantly simplify 3D content creation and editing.
However, the paper also acknowledges several limitations and areas for further research:
- The system may struggle with complex, abstract, or open-ended textual instructions that go beyond simple geometric transformations.
- The quality and fidelity of the rendered images may still be limited compared to manually crafted 3D models or professional 3D animation.
- The system's performance and scalability when working with large-scale or high-resolution NeRF representations is not thoroughly evaluated.
Additionally, while the paper focuses on the technical aspects of the framework, it would be valuable to consider the potential societal implications and ethical considerations of such technology. For example, the ability to easily manipulate 3D scenes through text could have implications for misinformation, deepfakes, or unintended bias in generated content.
Overall, the research presented in this paper represents an important step forward in bridging the gap between 3D modeling, image editing, and natural language processing. However, as with any emerging technology, further development and rigorous evaluation will be necessary to unlock the full potential of this approach while also addressing its potential pitfalls.
Conclusion
This paper introduces a framework that connects neural radiance fields (NeRFs), images, and text, enabling depth-aware text-based editing of 3D scenes. By leveraging advancements in vision-language models and neural feature compression, the researchers have developed a system that allows users to create and modify photorealistic 3D environments through natural language.
The potential impact of this technology is significant, as it could greatly simplify and democratize 3D content creation, opening up new avenues for creative expression and innovation. However, the research also highlights the need to carefully consider the limitations and potential societal implications of such powerful tools.
As the field of 3D modeling, computer vision, and natural language processing continues to evolve, the insights and techniques presented in this paper will undoubtedly play an important role in shaping the future of how we interact with and manipulate the virtual world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Connecting NeRFs, Images, and Text
Francesco Ballerini, Pierluigi Zama Ramirez, Roberto Mirabella, Samuele Salti, Luigi Di Stefano
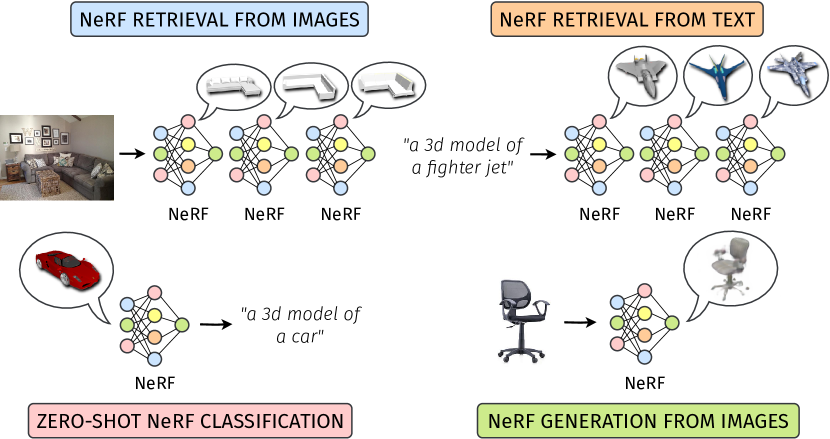
Neural Radiance Fields (NeRFs) have emerged as a standard framework for representing 3D scenes and objects, introducing a novel data type for information exchange and storage. Concurrently, significant progress has been made in multimodal representation learning for text and image data. This paper explores a novel research direction that aims to connect the NeRF modality with other modalities, similar to established methodologies for images and text. To this end, we propose a simple framework that exploits pre-trained models for NeRF representations alongside multimodal models for text and image processing. Our framework learns a bidirectional mapping between NeRF embeddings and those obtained from corresponding images and text. This mapping unlocks several novel and useful applications, including NeRF zero-shot classification and NeRF retrieval from images or text.
Read more4/12/2024

0
LLaNA: Large Language and NeRF Assistant
Andrea Amaduzzi, Pierluigi Zama Ramirez, Giuseppe Lisanti, Samuele Salti, Luigi Di Stefano
Multimodal Large Language Models (MLLMs) have demonstrated an excellent understanding of images and 3D data. However, both modalities have shortcomings in holistically capturing the appearance and geometry of objects. Meanwhile, Neural Radiance Fields (NeRFs), which encode information within the weights of a simple Multi-Layer Perceptron (MLP), have emerged as an increasingly widespread modality that simultaneously encodes the geometry and photorealistic appearance of objects. This paper investigates the feasibility and effectiveness of ingesting NeRF into MLLM. We create LLaNA, the first general-purpose NeRF-language assistant capable of performing new tasks such as NeRF captioning and Q&A. Notably, our method directly processes the weights of the NeRF's MLP to extract information about the represented objects without the need to render images or materialize 3D data structures. Moreover, we build a dataset of NeRFs with text annotations for various NeRF-language tasks with no human intervention. Based on this dataset, we develop a benchmark to evaluate the NeRF understanding capability of our method. Results show that processing NeRF weights performs favourably against extracting 2D or 3D representations from NeRFs.
Read more6/18/2024
🧠
0
Exploring Multi-modal Neural Scene Representations With Applications on Thermal Imaging
Mert Ozer, Maximilian Weiherer, Martin Hundhausen, Bernhard Egger
Neural Radiance Fields (NeRFs) quickly evolved as the new de-facto standard for the task of novel view synthesis when trained on a set of RGB images. In this paper, we conduct a comprehensive evaluation of neural scene representations, such as NeRFs, in the context of multi-modal learning. Specifically, we present four different strategies of how to incorporate a second modality, other than RGB, into NeRFs: (1) training from scratch independently on both modalities; (2) pre-training on RGB and fine-tuning on the second modality; (3) adding a second branch; and (4) adding a separate component to predict (color) values of the additional modality. We chose thermal imaging as second modality since it strongly differs from RGB in terms of radiosity, making it challenging to integrate into neural scene representations. For the evaluation of the proposed strategies, we captured a new publicly available multi-view dataset, ThermalMix, consisting of six common objects and about 360 RGB and thermal images in total. We employ cross-modality calibration prior to data capturing, leading to high-quality alignments between RGB and thermal images. Our findings reveal that adding a second branch to NeRF performs best for novel view synthesis on thermal images while also yielding compelling results on RGB. Finally, we also show that our analysis generalizes to other modalities, including near-infrared images and depth maps. Project page: https://mert-o.github.io/ThermalNeRF/.
Read more8/26/2024

0
DATENeRF: Depth-Aware Text-based Editing of NeRFs
Sara Rojas, Julien Philip, Kai Zhang, Sai Bi, Fujun Luan, Bernard Ghanem, Kalyan Sunkavall
Recent advancements in diffusion models have shown remarkable proficiency in editing 2D images based on text prompts. However, extending these techniques to edit scenes in Neural Radiance Fields (NeRF) is complex, as editing individual 2D frames can result in inconsistencies across multiple views. Our crucial insight is that a NeRF scene's geometry can serve as a bridge to integrate these 2D edits. Utilizing this geometry, we employ a depth-conditioned ControlNet to enhance the coherence of each 2D image modification. Moreover, we introduce an inpainting approach that leverages the depth information of NeRF scenes to distribute 2D edits across different images, ensuring robustness against errors and resampling challenges. Our results reveal that this methodology achieves more consistent, lifelike, and detailed edits than existing leading methods for text-driven NeRF scene editing.
Read more8/2/2024