DATENeRF: Depth-Aware Text-based Editing of NeRFs

0

Sign in to get full access
Overview
- This paper introduces DATENeRF, a system for depth-aware, text-based editing of Neural Radiance Fields (NeRFs).
- NeRFs are 3D scene representations that can be used for tasks like view synthesis and 3D rendering.
- DATENeRF allows users to edit NeRFs by providing text descriptions of desired changes, while taking depth information into account.
- The system uses diffusion models to generate edited NeRFs that match the text descriptions.
Plain English Explanation
NeRFs are a powerful way to represent 3D scenes, but traditionally it has been difficult to edit them in a fine-grained way. DATENeRF: Depth-Aware Text-based Editing of NeRFs changes this by allowing users to modify NeRFs using simple text descriptions.
For example, a user could say "make the car in the scene red" or "add a tree to the left side of the image." DATENeRF would then update the NeRF to match these instructions, while also taking into account the depth information in the scene. This allows for more precise and realistic edits compared to just modifying the 2D image.
The key innovation is using diffusion models, a type of machine learning, to generate the edited NeRF. Diffusion models are good at creating new data that matches given constraints, in this case the text descriptions. By combining the text input with the depth data, DATENeRF can produce edited NeRFs that look natural and seamlessly integrated into the scene.
This advance in NeRF editing could be useful for applications like 3D content creation, virtual cinematography, and video game development, where artists and designers need to quickly iterate on 3D environments. It brings the power of language-based control to an important 3D representation format.
Technical Explanation
The core of DATENeRF is a diffusion model that takes in a text description and the existing NeRF and generates an edited NeRF. The text encoding is combined with a depth map of the scene, allowing the model to understand both the semantic changes requested and the spatial layout of the 3D environment.
The diffusion model is trained on a large dataset of NeRFs and associated text descriptions of edits. During inference, the model iteratively refines the NeRF, gradually introducing the requested changes while preserving the overall structure of the scene.
The paper also introduces techniques to improve the quality and consistency of the edited NeRFs, such as using a separate "depth-aware" diffusion model to refine the depth information. Extensive experiments show that DATENeRF outperforms baseline text-to-3D methods in terms of faithfully executing the requested edits while maintaining realism.
Critical Analysis
The DATENeRF paper makes a compelling case for the value of depth-aware, text-based NeRF editing. By leveraging diffusion models, the system can generate edited NeRFs that match natural language instructions in a plausible way, going beyond simple 2D image editing.
However, the paper acknowledges some limitations. The current system is limited to relatively simple edits, such as adding or modifying individual objects. More complex scene-level changes, like rearranging the layout or changing the lighting, are not yet supported. Additionally, the training data and model capacity may restrict the range of edits that can be faithfully executed.
Further research could explore ways to expand the scope and flexibility of DATENeRF, such as by incorporating more advanced language understanding or 3D reasoning capabilities. Investigating how to scale the system to handle larger and more complex scenes would also be valuable.
Overall, DATENeRF represents an exciting step towards making 3D content creation more accessible and intuitive. By bridging the gap between natural language and 3D geometry, it opens up new possibilities for designers, artists, and researchers working with virtual environments.
Conclusion
DATENeRF: Depth-Aware Text-based Editing of NeRFs introduces a novel system for editing Neural Radiance Fields using natural language descriptions. By combining text input with depth information, the system can generate edited NeRFs that realistically incorporate the requested changes.
This advance in NeRF editing could have significant implications for 3D content creation, virtual cinematography, video game development, and other applications where the ability to quickly and intuitively modify 3D environments is valuable. As the capabilities of language-based 3D editing continue to evolve, we may see an increasingly seamless integration between natural language and the creation of virtual worlds.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DATENeRF: Depth-Aware Text-based Editing of NeRFs
Sara Rojas, Julien Philip, Kai Zhang, Sai Bi, Fujun Luan, Bernard Ghanem, Kalyan Sunkavall
Recent advancements in diffusion models have shown remarkable proficiency in editing 2D images based on text prompts. However, extending these techniques to edit scenes in Neural Radiance Fields (NeRF) is complex, as editing individual 2D frames can result in inconsistencies across multiple views. Our crucial insight is that a NeRF scene's geometry can serve as a bridge to integrate these 2D edits. Utilizing this geometry, we employ a depth-conditioned ControlNet to enhance the coherence of each 2D image modification. Moreover, we introduce an inpainting approach that leverages the depth information of NeRF scenes to distribute 2D edits across different images, ensuring robustness against errors and resampling challenges. Our results reveal that this methodology achieves more consistent, lifelike, and detailed edits than existing leading methods for text-driven NeRF scene editing.
Read more8/2/2024

0
IE-NeRF: Inpainting Enhanced Neural Radiance Fields in the Wild
Shuaixian Wang, Haoran Xu, Yaokun Li, Jiwei Chen, Guang Tan
We present a novel approach for synthesizing realistic novel views using Neural Radiance Fields (NeRF) with uncontrolled photos in the wild. While NeRF has shown impressive results in controlled settings, it struggles with transient objects commonly found in dynamic and time-varying scenes. Our framework called textit{Inpainting Enhanced NeRF}, or ours, enhances the conventional NeRF by drawing inspiration from the technique of image inpainting. Specifically, our approach extends the Multi-Layer Perceptrons (MLP) of NeRF, enabling it to simultaneously generate intrinsic properties (static color, density) and extrinsic transient masks. We introduce an inpainting module that leverages the transient masks to effectively exclude occlusions, resulting in improved volume rendering quality. Additionally, we propose a new training strategy with frequency regularization to address the sparsity issue of low-frequency transient components. We evaluate our approach on internet photo collections of landmarks, demonstrating its ability to generate high-quality novel views and achieve state-of-the-art performance.
Read more7/16/2024
🛸
0
New!CompoNeRF: Text-guided Multi-object Compositional NeRF with Editable 3D Scene Layout
Haotian Bai, Yuanhuiyi Lyu, Lutao Jiang, Sijia Li, Haonan Lu, Xiaodong Lin, Lin Wang
Text-to-3D form plays a crucial role in creating editable 3D scenes for AR/VR. Recent advances have shown promise in merging neural radiance fields (NeRFs) with pre-trained diffusion models for text-to-3D object generation. However, one enduring challenge is their inadequate capability to accurately parse and regenerate consistent multi-object environments. Specifically, these models encounter difficulties in accurately representing quantity and style prompted by multi-object texts, often resulting in a collapse of the rendering fidelity that fails to match the semantic intricacies. Moreover, amalgamating these elements into a coherent 3D scene is a substantial challenge, stemming from generic distribution inherent in diffusion models. To tackle the issue of 'guidance collapse' and further enhance scene consistency, we propose a novel framework, dubbed CompoNeRF, by integrating an editable 3D scene layout with object-specific and scene-wide guidance mechanisms. It initiates by interpreting a complex text into the layout populated with multiple NeRFs, each paired with a corresponding subtext prompt for precise object depiction. Next, a tailored composition module seamlessly blends these NeRFs, promoting consistency, while the dual-level text guidance reduces ambiguity and boosts accuracy. Noticeably, our composition design permits decomposition. This enables flexible scene editing and recomposition into new scenes based on the edited layout or text prompts. Utilizing the open-source Stable Diffusion model, CompoNeRF generates multi-object scenes with high fidelity. Remarkably, our framework achieves up to a textbf{54%} improvement by the multi-view CLIP score metric. Our user study indicates that our method has significantly improved semantic accuracy, multi-view consistency, and individual recognizability for multi-object scene generation.
Read more9/24/2024
0
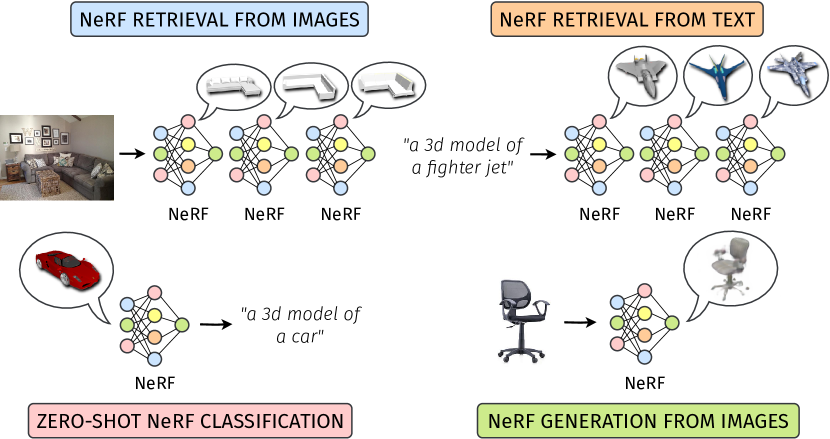
Connecting NeRFs, Images, and Text
Francesco Ballerini, Pierluigi Zama Ramirez, Roberto Mirabella, Samuele Salti, Luigi Di Stefano
Neural Radiance Fields (NeRFs) have emerged as a standard framework for representing 3D scenes and objects, introducing a novel data type for information exchange and storage. Concurrently, significant progress has been made in multimodal representation learning for text and image data. This paper explores a novel research direction that aims to connect the NeRF modality with other modalities, similar to established methodologies for images and text. To this end, we propose a simple framework that exploits pre-trained models for NeRF representations alongside multimodal models for text and image processing. Our framework learns a bidirectional mapping between NeRF embeddings and those obtained from corresponding images and text. This mapping unlocks several novel and useful applications, including NeRF zero-shot classification and NeRF retrieval from images or text.
Read more4/12/2024