$mathbb{X}$-Sample Contrastive Loss: Improving Contrastive Learning with Sample Similarity Graphs

0

Sign in to get full access
Overview
- The paper introduces a new contrastive loss function called the "𝕏-Sample Contrastive Loss" that improves upon existing contrastive learning approaches.
- The key idea is to incorporate sample similarity information into the contrastive loss, leveraging a sample similarity graph.
- The proposed method aims to learn more effective representations by better capturing the underlying structure of the data.
Plain English Explanation
Contrastive learning is a powerful technique for training artificial intelligence models to learn useful representations from data. The core idea is to push similar samples closer together and dissimilar samples further apart in the representation space.
The 𝕏-Sample Contrastive Loss builds on this by incorporating additional information about the relationships between data samples. Rather than just considering pairs of similar and dissimilar samples, it uses a sample similarity graph to model more complex connections between the data. This allows the model to learn representations that better capture the underlying structure of the dataset.
By leveraging this richer sample similarity information, the 𝕏-Sample Contrastive Loss can learn more effective representations compared to standard contrastive learning approaches. This can lead to improved performance on a variety of tasks that rely on strong data representations, such as image classification, object detection, and recommender systems.
Technical Explanation
The 𝕏-Sample Contrastive Loss is designed to leverage a sample similarity graph that encodes relationships between data samples. This graph can be constructed using domain-specific knowledge or learned from the data itself.
The loss function encourages the model to learn representations where similar samples (connected in the graph) are pushed closer together, while dissimilar samples are pushed further apart. This is achieved by considering not just pairwise sample comparisons, but broader 𝕏-sample comparisons that incorporate the sample similarity information.
The authors demonstrate the effectiveness of the 𝕏-Sample Contrastive Loss through experiments on various datasets and tasks, including image classification, object detection, and recommender systems. The results show that the proposed approach outperforms standard contrastive learning methods, particularly in scenarios where the data exhibits complex underlying structures.
Critical Analysis
The 𝕏-Sample Contrastive Loss is a promising technique that can potentially improve the performance of many machine learning models by learning more effective data representations. However, the authors do not discuss the computational complexity of the approach, which could be a practical concern for large-scale applications.
Additionally, the paper does not explore the robustness of the 𝕏-Sample Contrastive Loss to noisy or incomplete sample similarity graphs. In real-world scenarios, the graph construction process may introduce errors or biases, which could impact the effectiveness of the proposed method.
Further research could investigate the 𝕏-Sample Contrastive Loss in the context of semi-supervised or few-shot learning settings, where the sample similarity information could be particularly valuable for improving data efficiency.
Conclusion
The 𝕏-Sample Contrastive Loss is a novel contrastive learning approach that leverages sample similarity graphs to learn more effective data representations. By considering broader 𝕏-sample comparisons that incorporate this structural information, the proposed method can outperform standard contrastive learning techniques on a variety of tasks.
While the paper demonstrates the potential of the 𝕏-Sample Contrastive Loss, further research is needed to address practical concerns, such as computational complexity and robustness to noisy or incomplete sample similarity graphs. Exploring the 𝕏-Sample Contrastive Loss in the context of semi-supervised and few-shot learning could also be a promising direction for future work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
$mathbb{X}$-Sample Contrastive Loss: Improving Contrastive Learning with Sample Similarity Graphs
Vlad Sobal, Mark Ibrahim, Randall Balestriero, Vivien Cabannes, Diane Bouchacourt, Pietro Astolfi, Kyunghyun Cho, Yann LeCun
Learning good representations involves capturing the diverse ways in which data samples relate. Contrastive loss - an objective matching related samples - underlies methods from self-supervised to multimodal learning. Contrastive losses, however, can be viewed more broadly as modifying a similarity graph to indicate how samples should relate in the embedding space. This view reveals a shortcoming in contrastive learning: the similarity graph is binary, as only one sample is the related positive sample. Crucially, similarities textit{across} samples are ignored. Based on this observation, we revise the standard contrastive loss to explicitly encode how a sample relates to others. We experiment with this new objective, called $mathbb{X}$-Sample Contrastive, to train vision models based on similarities in class or text caption descriptions. Our study spans three scales: ImageNet-1k with 1 million, CC3M with 3 million, and CC12M with 12 million samples. The representations learned via our objective outperform both contrastive self-supervised and vision-language models trained on the same data across a range of tasks. When training on CC12M, we outperform CLIP by $0.6%$ on both ImageNet and ImageNet Real. Our objective appears to work particularly well in lower-data regimes, with gains over CLIP of $16.8%$ on ImageNet and $18.1%$ on ImageNet Real when training with CC3M. Finally, our objective seems to encourage the model to learn representations that separate objects from their attributes and backgrounds, with gains of $3.3$-$5.6$% over CLIP on ImageNet9. We hope the proposed solution takes a small step towards developing richer learning objectives for understanding sample relations in foundation models.
Read more9/14/2024

0
Adaptive Multi-head Contrastive Learning
Lei Wang, Piotr Koniusz, Tom Gedeon, Liang Zheng
In contrastive learning, two views of an original image, generated by different augmentations, are considered a positive pair, and their similarity is required to be high. Similarly, two views of distinct images form a negative pair, with encouraged low similarity. Typically, a single similarity measure, provided by a lone projection head, evaluates positive and negative sample pairs. However, due to diverse augmentation strategies and varying intra-sample similarity, views from the same image may not always be similar. Additionally, owing to inter-sample similarity, views from different images may be more akin than those from the same image. Consequently, enforcing high similarity for positive pairs and low similarity for negative pairs may be unattainable, and in some cases, such enforcement could detrimentally impact performance. To address this challenge, we propose using multiple projection heads, each producing a distinct set of features. Our pre-training loss function emerges from a solution to the maximum likelihood estimation over head-wise posterior distributions of positive samples given observations. This loss incorporates the similarity measure over positive and negative pairs, each re-weighted by an individual adaptive temperature, regulated to prevent ill solutions. Our approach, Adaptive Multi-Head Contrastive Learning (AMCL), can be applied to and experimentally enhances several popular contrastive learning methods such as SimCLR, MoCo, and Barlow Twins. The improvement remains consistent across various backbones and linear probing epochs, and becomes more significant when employing multiple augmentation methods.
Read more9/24/2024
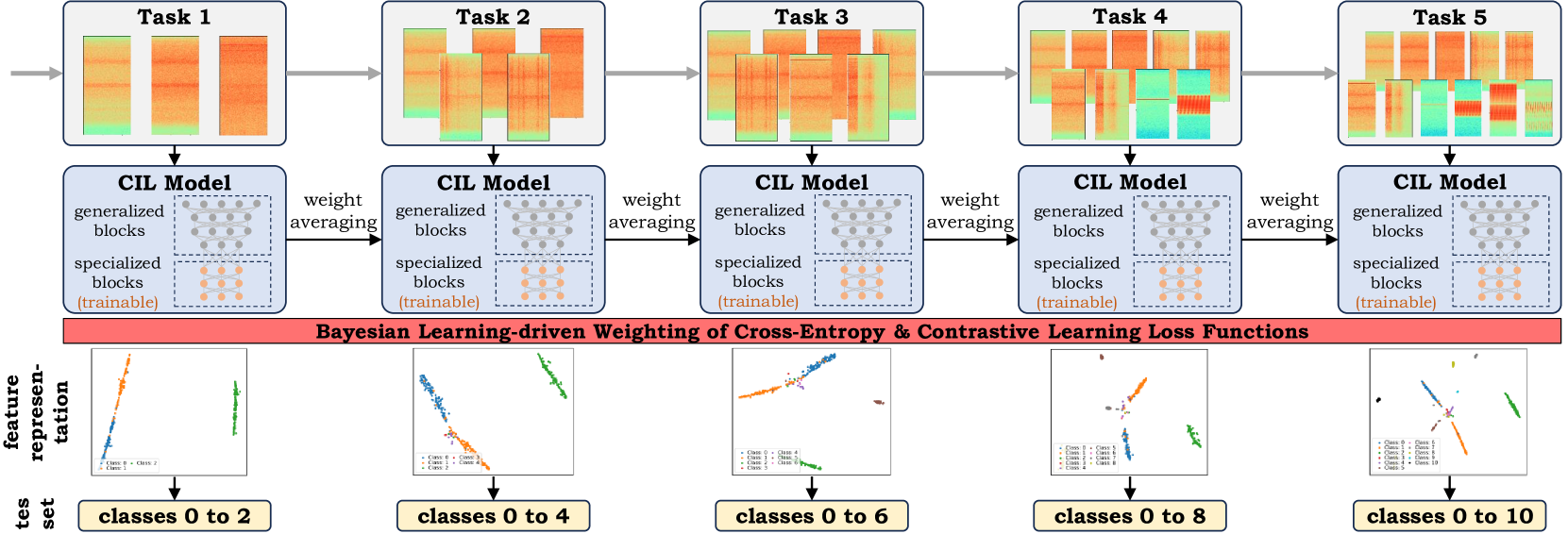
0
Bayesian Learning-driven Prototypical Contrastive Loss for Class-Incremental Learning
Nisha L. Raichur, Lucas Heublein, Tobias Feigl, Alexander Rugamer, Christopher Mutschler, Felix Ott
The primary objective of methods in continual learning is to learn tasks in a sequential manner over time from a stream of data, while mitigating the detrimental phenomenon of catastrophic forgetting. In this paper, we focus on learning an optimal representation between previous class prototypes and newly encountered ones. We propose a prototypical network with a Bayesian learning-driven contrastive loss (BLCL) tailored specifically for class-incremental learning scenarios. Therefore, we introduce a contrastive loss that incorporates new classes into the latent representation by reducing the intra-class distance and increasing the inter-class distance. Our approach dynamically adapts the balance between the cross-entropy and contrastive loss functions with a Bayesian learning technique. Empirical evaluations conducted on both the CIFAR-10 and CIFAR-100 dataset for image classification and images of a GNSS-based dataset for interference classification validate the efficacy of our method, showcasing its superiority over existing state-of-the-art approaches.
Read more7/15/2024

0
Towards Multi-view Graph Anomaly Detection with Similarity-Guided Contrastive Clustering
Lecheng Zheng, John R. Birge, Yifang Zhang, Jingrui He
Anomaly detection on graphs plays an important role in many real-world applications. Usually, these data are composed of multiple types (e.g., user information and transaction records for financial data), thus exhibiting view heterogeneity. Therefore, it can be challenging to leverage such multi-view information and learn the graph's contextual information to identify rare anomalies. To tackle this problem, many deep learning-based methods utilize contrastive learning loss as a regularization term to learn good representations. However, many existing contrastive-based methods show that traditional contrastive learning losses fail to consider the semantic information (e.g., class membership information). In addition, we theoretically show that clustering-based contrastive learning also easily leads to a sub-optimal solution. To address these issues, in this paper, we proposed an autoencoder-based clustering framework regularized by a similarity-guided contrastive loss to detect anomalous nodes. Specifically, we build a similarity map to help the model learn robust representations without imposing a hard margin constraint between the positive and negative pairs. Theoretically, we show that the proposed similarity-guided loss is a variant of contrastive learning loss, and how it alleviates the issue of unreliable pseudo-labels with the connection to graph spectral clustering. Experimental results on several datasets demonstrate the effectiveness and efficiency of our proposed framework.
Read more9/17/2024